掌握后缀数组:高效字符串处理和模式匹配的终极指南。发现后缀数组如何革新文本算法。
- 后缀数组简介
- 后缀数组的工作原理:核心概念
- 构建后缀数组:逐步指南
- 后缀数组与后缀树:关键区别
- 后缀数组在计算机科学中的应用
- 利用后缀数组优化搜索和模式匹配
- 常见利用后缀数组的算法
- 性能考虑与局限性
- 真实世界的案例与示例
- 进一步阅读与进阶主题
- 来源和参考文献
后缀数组简介
后缀数组是一种强大的数据结构,用于字符串处理,特别是在高效的模式匹配、子串查询和文本索引中。它表示给定字符串所有后缀的排序顺序,通常作为起始索引的数组。这一结构在生物信息学、数据压缩和信息检索等领域具有多种应用,在这些领域中,快速搜索和分析大文本至关重要。
后缀数组的概念作为后缀树的一种空间高效替代方案被引入,提供了类似的功能,但内存开销较小。与后缀树相比,后缀树在实现和维护上可能比较复杂,后缀数组则更为简单和紧凑,适合用于大规模文本处理任务。构建后缀数组的过程涉及对字符串的所有可能后缀进行排序,可以使用基于比较的算法在 O(n log n) 时间内完成,或通过更先进的技术如引导排序法以线性时间实现(美国数学会)。
后缀数组通常与辅助数据结构结合使用,如最长公共前缀 (LCP) 数组,这进一步增强了其在解决问题(如查找最长重复子串或进行快速字典序比较)中的实用性。由于其高效性和多功能性,后缀数组已成为现代算法字符串分析的基础工具(普林斯顿大学)。
后缀数组的工作原理:核心概念
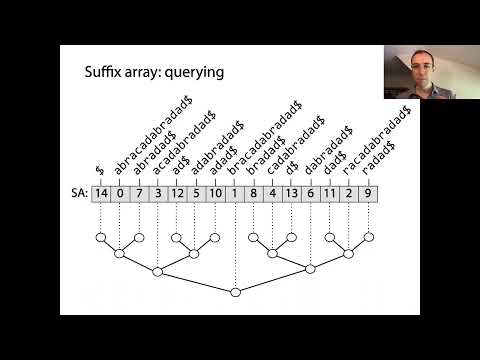
后缀数组是强大的数据结构,使高效的字符串处理成为可能,尤其是在模式匹配和文本索引中。在其核心,后缀数组表示给定字符串所有可能后缀的排序顺序。构建的第一步是生成输入字符串的每个后缀,每个后缀从不同的位置开始。这些后缀随后按照字典顺序排序,后缀数组本身是一个整数数组,每个条目指示在此排序顺序中后缀的起始索引。
后缀数组背后的关键概念是,通过对所有后缀进行排序,可以执行快速的二进制搜索,以定位原始文本中的子串或模式。这是对简单搜索方法的显著改进,后者可能需要对每一个查询扫描整个文本。后缀数组通常与最长公共前缀 (LCP) 数组配对,后者存储排序数组中连续后缀之间最长公共前缀的长度。此配对进一步加快各种字符串操作,如查找重复子串或不同子串的数量。
高效的构建算法,如引导排序法或前缀加倍技术,已经将构建后缀数组的时间复杂度降低到线性或接近线性,为大规模应用提供实用性。后缀数组广泛应用于生物信息学、数据压缩和信息检索等领域,其中快速和内存高效的字符串处理至关重要。有关基础原理和算法的全面概述,请参阅赫尔辛基大学计算机科学系的文档。
构建后缀数组:逐步指南
构建后缀数组涉及生成给定字符串所有后缀的排序数组,由它们的起始索引表示。该过程可以分为几个关键步骤:
- 1. 生成所有后缀:对于长度为 n 的字符串,通过起始位置枚举所有后缀。例如,字符串“banana”yield 的后缀从索引 0 开始(“banana”)、1(“anana”)、2(“nana”)等等。
- 2. 排序后缀:按字典顺序对这些后缀进行排序。这可以通过直接比较字符串在 O(n2 log n) 时间内简单地完成,但也有更高效的算法。
- 3. 存储索引:不存储实际的后缀字符串,而是以排序顺序存储其起始索引。这个索引数组就是后缀数组。
- 4. 优化:高级算法,如 Manber-Myers 算法,使用加倍技术实现 O(n log n) 的时间复杂度。更快的,Karkkainen-Sanders 算法(也称为 Skew 算法)可以在整数字母表中以线性时间 O(n) 构建后缀数组。这些方法依赖于通过等级排序和递归策略来避免直接的字符串比较(计算机协会)。
- 5. 最终输出:最终的后缀数组使得高效的模式匹配、子串查询成为可能,并且是构建其他数据结构(如 LCP 数组)的基础(GeeksforGeeks)。
理解每个步骤和可用优化对于在大规模字符串处理应用中利用后缀数组至关重要。
后缀数组与后缀树:关键区别
后缀数组和后缀树都是高效字符串处理的基本数据结构,尤其在模式匹配、生物信息学和数据压缩等应用中。尽管它们目的相似,但其结构、内存需求和操作特征差异显著。
后缀树是给定字符串所有后缀的压缩尝试,允许非常快速的子串查询,通常相对于模式长度为线性时间。然而,后缀树实现复杂,需要大量内存开销——通常是原始字符串大小的几倍——因为它们的节点结构和存储指针及边标签的需求。这使得在非常大的数据集或内存受限的环境中使用它们变得不太实用。
相比之下,后缀数组则是一个更简单、更节省空间的数据结构。它由一个整数数组组成,表示字符串所有已排序后缀的起始位置。后缀数组可以在 O(n) 时间内构建,仅需 O(n) 的空间,其中 n 是字符串的长度。尽管使用后缀数组的子串搜索通常比后缀树慢(对于长度为 m 的模式为 O(m log n)),但通过使用辅助数据结构,如最长公共前缀 (LCP) 数组,可以将其改进到 O(m)。后缀数组的简单性和较低的内存占用,使其成为大规模文本索引和搜索任务的首选。
有关详细的比较和进一步阅读,请参见 计算机协会 和 GeeksforGeeks。
后缀数组在计算机科学中的应用
后缀数组已成为计算机科学中的基本数据结构,特别是在字符串处理、生物信息学和信息检索领域。它们的主要用途在于实现高效的模式匹配和子串查询。例如,后缀数组广泛用于全文搜索引擎,使其能够快速识别大文本语料库中查询子串的所有出现。这是通过利用后缀的字典顺序来实现的,这支持对模式匹配的二进制搜索操作,时间复杂度为对数时间 普林斯顿大学。
在生物信息学中,后缀数组促进DNA和蛋白质序列的比对与比较。用于基因组组装和序列比对的工具,例如下一代测序中所使用的,常常依赖后缀数组以高效处理大规模生物数据集 国立生物技术信息中心。此外,后缀数组是数据压缩算法的重要组成部分,如Burrows-Wheeler变换,它支撑了流行的压缩工具如bzip2。在这里,后缀数组使得输入数据转变为更易于通过将相似字符聚集在一起来进行压缩的形式。
除此之外,后缀数组还用于剽窃检测、数据去重以及构建高效数据结构以处理最长公共前缀 (LCP) 查询。它们的多功能性和高效性使其在需要快速和可扩展字符串处理的应用中不可或缺。
利用后缀数组优化搜索和模式匹配
后缀数组是强大的数据结构,显著优化字符串中的搜索和模式匹配操作。通过以字典顺序存储文本所有后缀的起始索引,后缀数组实现了高效的子串查询,这在全文搜索、生物信息学和数据压缩等应用中至关重要。使用后缀数组的主要优势是,在模式匹配时大大降低了时间复杂度。虽然暴力方法可能需要 O(nm) 时间,对于长度为 n 的文本和长度为 m 的模式,后缀数组可以通过在排序后的后缀上利用二进制搜索将模式搜索的复杂度降低到 O(m + log n)。
为了进一步提升性能,后缀数组通常与辅助数据结构如最长公共前缀(LCP)数组结合使用。LCP数组存储后缀数组中连续后缀之间最长公共前缀的长度,进而实现更快的模式匹配,并方便执行如查找独特子串数量或最长重复子串等任务。除此之外,现代构建后缀数组的算法,如引导排序法,能以线性时间复杂度实现,使其对大规模文本的处理变得实用(赫尔辛基大学)。
与后缀树相比,后缀数组在空间上的效率更高,因为它们仅需 O(n) 的空间并且更易于实施。其效率和多功能性使其成为快速和可扩展文本索引与模式匹配系统设计的基石(普林斯顿大学)。
常见利用后缀数组的算法
后缀数组是字符串处理中的基础数据结构,使得高效解决多种复杂问题成为可能。几种常见算法利用后缀数组实现最佳或接近最佳的性能,特别是在模式匹配、数据压缩和生物信息学领域。
最显著的应用之一是 子串搜索。通过结合后缀数组和二进制搜索,可以以 O(m log n) 的时间找到文本中模式的所有出现,其中 m 为模式长度,n 为文本长度。该方法显著快于简单的搜索方法,尤其是在处理大文本时。此外,最长公共前缀 (LCP) 数组 常与后缀数组同时构建,以进一步优化重复模式查询并促进查找最长重复子串或多个字符串之间最长公共子串的算法。
后缀数组在 数据压缩算法 中也不可或缺,如Burrows-Wheeler变换(BWT),它是bzip2压缩工具的关键组成部分。BWT依赖后缀的排序顺序重新排列输入文本,从而使其更易于进行基于运行长度编码和其他压缩技术(bzip2)。
在 生物信息学 中,后缀数组用于高效的序列比对和基因组分析,在快速搜索和比较DNA序列方面至关重要(国立生物技术信息中心)。在许多大规模应用中,其空间效率和速度使它们优于后缀树。
性能考虑与局限性
后缀数组是解决各种字符串处理问题(如子串搜索、模式匹配和计算最长公共前缀)的高效数据结构。然而,实际性能和适用性受到几个考虑因素和固有局限性的影响。
主要的性能因素之一是构建时间。尽管构建后缀数组的简单算法在 O(n log2 n) 的时间内运行,但更先进的算法,如 SA-IS 算法可以实现线性时间复杂度。然而,这些最优算法实现起来可能比较复杂,并且可能具有显著的常数因子,这会影响实际性能,特别是在处理非常大的文本或内存受限的环境时。空间复杂性也是一个重要方面;后缀数组通常需要 O(n) 的空间,但像最长公共前缀 (LCP) 数组或其他附加索引结构可能进一步增加内存使用(赫尔辛基大学)。
与后缀树相比,后缀数组在动态更新方面的灵活性较差,如文本中的插入或删除。修改构建后的后缀数组是非常复杂的,并且通常需要重建整个结构,使其在基础文本频繁变化的应用中不太适用(卡内基梅隆大学</a)。此外,尽管后缀数组比后缀树在空间上更高效,但在处理极大数据集,如整个基因组序列时,如果没有进一步压缩或外部内存技术,它们可能仍然不切实际(国立生物技术信息中心)。
总之,尽管后缀数组在静态文本的速度和内存效率方面提供显著优势,但在动态场景和大规模应用中的局限性必须在系统设计中仔细考虑。
真实世界的案例与示例
后缀数组广泛应用于各种需要高效字符串处理和模式匹配的现实应用中。其中一个最显著的用例是在生物信息学,特别是在基因组测序和分析中。像 Burrows-Wheeler Aligner 这样的工具利用后缀数组快速将短DNA读取对齐到参考基因组,从而推动大规模基因组研究和个性化医学的发展。
在信息检索中,后缀数组是实施快速全文搜索引擎的基础。例如, Apache Lucene 项目利用后缀数组和相关数据结构提供高效的子串搜索功能,这对索引和查询大型文本语料库至关重要。
后缀数组还在数据压缩算法中发挥着重要作用。例如,bzip2压缩工具使用Burrows-Wheeler变换,依赖构建后缀数组来重新排列输入数据并改善可压缩性。
此外,后缀数组被用于剽窃检测系统,例如 Turnitin,通过高效比较子串来识别文档之间的相似性。在自然语言处理领域,它们被用于识别重复短语、提取关键词和构建索引。
这些例子凸显了后缀数组在处理大规模字符串处理任务中的多功能性和高效性,涵盖从计算生物学到搜索引擎和数据压缩的多个领域。
进一步阅读与进阶主题
对于对后缀数组深入研究的读者,许多高级主题和资源可供参考。其中一个重要领域是 增强后的后缀数组 的研究,这种结构在基本结构中增加了额外的数据,如最长公共前缀 (LCP) 数组,使得模式匹配和子串查询更为高效。后缀数组与 后缀树 之间的相互作用也是研究的一个丰富领域,因为这两种结构解决类似的问题,但在空间和构建时间方面有不同的权衡。
最近的研究集中在后缀数组的 线性时间构建算法 上,例如 SA-IS 和 DC3(Skew)算法,这对于处理大规模基因组或文本数据至关重要。这些算法在文献中有详细讨论,包括 赫尔辛基大学功能后缀数组组 的基础性工作。
后缀数组的应用不仅限于字符串匹配,还扩展到数据压缩(例如,Burrows-Wheeler变换)、生物信息学(基因组组装和比对)和信息检索等领域。有关综合概述,强烈推荐丹·古斯菲尔德(Dan Gusfield)的书籍 《字符串、树和序列上的算法》。
- 后缀数组:一种在线字符串搜索的新方法(Manber 和 Myers 的原始论文)
- 使用引导排序的线性时间后缀数组构建(SA-IS 算法)
- 维基百科:后缀数组(概述及进一步链接)
来源和参考文献