Опановування масивами суфіксів: остаточний посібник з ефективної обробки рядків та зіставлення шаблонів. Досліджуйте, як масиви суфіксів революціонізують текстові алгоритми.
- Вступ до масивів суфіксів
- Як працюють масиви суфіксів: основні концепції
- Будування масиву суфіксів: покроково
- Масиви суфіксів vs. дерева суфіксів: ключові відмінності
- Застосування масивів суфіксів у комп’ютерних науках
- Оптимізація пошуку та зіставлення шаблонів з масивами суфіксів
- Звичні алгоритми, що використовують масиви суфіксів
- Розгляд продуктивності та обмеження
- Справжні випадки використання та приклади
- Подальше читання та розширені теми
- Джерела та посилання
Вступ до масивів суфіксів
Масив суфіксів є потужною структурою даних, що використовується в обробці рядків, зокрема для ефективного зіставлення шаблонів, запитів на підрядки та індексування тексту. Він представляє відсортований порядок усіх суфіксів заданого рядка, зазвичай у вигляді масиву початкових індексів. Ця структура забезпечує різноманітні застосування в таких галузях, як біоінформатика, стиснення даних та інформаційний пошук, де швидкий пошук та аналіз великих текстів є надзвичайно важливими.
Концепція масиву суфіксів була введена як економний у використанні пам’яті альтернативою дереву суфіксів, що пропонує подібні функції, але з меншими витратами пам’яті. На відміну від дерев суфіксів, які можуть бути складними для впровадження та підтримки, масиви суфіксів є простими та компактними, що робить їх підходящими для великих завдань обробки тексту. Будівництво масиву суфіксів передбачає сортування усіх можливих суфіксів рядка, що може бути досягнуто за O(n log n) часу за допомогою алгоритмів, що базуються на порівнянні, або навіть за лінійний час з використанням більш просунутих методів, таких як метод індукованого сортування (Американське математичне товариство).
Масиви суфіксів часто використовуються разом з допоміжними структурами даних, такими як масив найдовших спільних префіксів (LCP), які ще більше підвищують їхню корисність для вирішення таких проблем, як пошук найдовшого повторюваного підрядка або виконання швидких лексикографічних порівнянь. Їхня ефективність і універсальність зробили масиви суфіксів основним інструментом у сучасному алгоритмічному аналізі рядків (Принстонський університет).
Як працюють масиви суфіксів: основні концепції
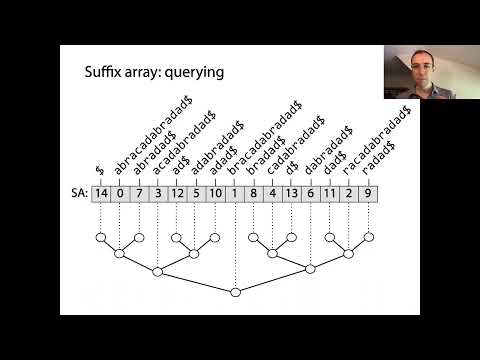
Масиви суфіксів є потужними структурами даних, які дозволяють ефективно обробляти рядки, зокрема для зіставлення шаблонів та індексування тексту. В основі масивів суфіксів лежить представлення відсортованого порядку всіх можливих суфіксів даного рядка. Процес будівництва починається з генерації кожного суфікса вхідного рядка, кожний з яких починається з різної позиції. Ці суфікси потім сортуються в лексикографічному порядку, а сам масив суфіксів є масивом цілих чисел, де кожен запис вказує на початковий індекс суфікса у цьому відсортованому порядку.
Ключова концепція масивів суфіксів полягає в тому, що, сортувавши всі суфікси, можна виконувати швидкі бінарні пошуки для знаходження підрядків або шаблонів у початковому тексті. Це є суттєвим поліпшенням в порівнянні з наївними методами пошуку, які можуть вимагати сканування всього тексту для кожного запиту. Масиви суфіксів часто поєднуються з масивом найдовших спільних префіксів (LCP), який зберігає довжини найдовших спільних префіксів між послідовними суфіксами у відсортованому масиві. Це поєднання ще більше прискорює різноманітні операції з рядками, такі як пошук повторюваних підрядків або кількість різних підрядків.
Ефективні алгоритми будівництва, такі як метод індукованого сортування або використання подвоєння префіксів, зменшили часову складність побудови масивів суфіксів до лінійного або майже лінійного часу, що робить їх практичними для великих застосувань. Масиви суфіксів широко використовуються в біоінформатиці, стисненні даних і інформаційному пошуку, де швидка та пам’яттєзберігаюча обробка рядків є критично важливою. Для повного огляду основних принципів та алгоритмів зверніться до документації Кафедри комп’ютерних наук Гельсінського університету.
Будування масиву суфіксів: покроково
Будування масиву суфіксів передбачає створення відсортованого масиву всіх суфіксів даного рядка, представленого їхніми початковими індексами. Процес можна розділити на кілька ключових етапів:
- 1. Генерація всіх суфіксів: Для рядка довжини n перерахувати всі суфікси за їхніми початковими позиціями. Наприклад, рядок “banana” дає суфікси, що починаються на індексах 0 (“banana”), 1 (“anana”), 2 (“nana”) і так далі.
- 2. Сортування суфіксів: Відсортувати ці суфікси в лексикографічному порядку. Це можна зробити наївно за O(n2 log n) часу, порівнюючи рядки безпосередньо, але існують більш ефективні алгоритми.
- 3. Зберігання індексів: Замість зберігання фактичних суфіксів, зберігайте їх початкові індекси в відсортованому порядку. Цей масив індексів і є масивом суфіксів.
- 4. Оптимізація: Просунуті алгоритми, як-от алгоритм Manber-Myers, використовують техніку подвоєння для досягнення складності O(n log n). Навіть швидше, алгоритм Karkkainen-Sanders (відомий також як Skew algorithm) може побудувати масив суфіксів за лінійний час O(n) для цілих алфавітів. Ці методи покладаються на сортування за рангами та рекурсивні стратегії, щоб уникнути безпосередніх порівнянь рядків Асоціація обчислювальної техніки.
- 5. Остаточний вихід: Отриманий масив суфіксів дозволяє ефективно виконувати зіставлення шаблонів, запити на підрядки і є основою для побудови інших структур даних, таких як масив LCP GeeksforGeeks.
Розуміння кожного етапу та доступних оптимізацій є критично важливим для використання масивів суфіксів у великих програмах обробки рядків.
Масиви суфіксів vs. дерева суфіксів: ключові відмінності
Масиви суфіксів і дерева суфіксів є основними структурами даних для ефективної обробки рядків, зокрема в застосуваннях, таких як зіставлення шаблонів, біоінформатика та стиснення даних. Хоча вони виконують подібні функції, їх структури, вимоги до пам’яті та операційні характеристики істотно відрізняються.
Дерево суфіксів є стиснутим trie (деревом) усіх суфіксів заданого рядка, що дозволяє здійснювати надзвичайно швидкі запити на підрядки, зазвичай за лінійний час у відношенні до довжини шаблону. Проте дерева суфіксів складні у впровадженні та вимагають значних витрат пам’яті — часто в кілька разів більше розміру оригінального рядка — через їх структуру на вузлах та необхідність зберігання покажчиків і міток ребер. Це робить їх менш практичними для дуже великих наборів даних або для середовищ з обмеженою пам’яттю.
На відміну від цього, масив суфіксів є значно простішою та економнішою у використанні пам’яті структурою даних. Він складається з масиву цілих чисел, що представляють початкові позиції всіх відсортованих суфіксів рядка. Масиви суфіксів можуть бути побудовані за лінійний час і потребують лише O(n) пам’яті, де n — це довжина рядка. Хоча пошуки підрядків за допомогою масиву суфіксів зазвичай повільніші, ніж з деревом суфіксів (O(m log n) для шаблону довжини m), це можна поліпшити до O(m) за допомогою допоміжних структур даних, таких як масив найдовших спільних префіксів (LCP). Простота та менший обсяг пам’яті масивів суфіксів роблять їх кращими для завдань індексування та пошуку великих текстів.
Для детального порівняння та подальшого читання дивіться Асоціацію обчислювальної техніки та GeeksforGeeks.
Застосування масивів суфіксів у комп’ютерних науках
Масиви суфіксів стали основною структурою даних у комп’ютерних науках, зокрема у сфері обробки рядків, біоінформатики та інформаційного пошуку. Їх основна корисність полягає в забезпеченні ефективного зіставлення шаблонів та запитів на підрядки. Наприклад, масиви суфіксів широко використовуються в пошукових системах повнотекстового пошуку, де вони дозволяють швидко ідентифікувати всі випадки наявності підрядка запиту в великому текстовому корпусі. Це досягається за рахунок використання лексикографічно відсортованого порядку суфіксів, що підтримує бінарні пошукові операції для зіставлення шаблонів з логарифмічною часовою складністю Принстонський університет.
У біоінформатиці масиви суфіксів полегшують вирівнювання та порівняння послідовностей ДНК та білків. Інструменти для складання геномів і вирівнювання послідовностей, такі як ті, що використовуються в секвенуванні наступного покоління, часто покладаються на масиви суфіксів для ефективної обробки величезних біологічних наборів даних Національний центр біотехнологічної інформації. Крім того, масиви суфіксів є невід’ємною частиною алгоритмів стиснення даних, таких як перетворення Бурроуза-Уїлера, яке є основою популярних інструментів стиснення, таких як bzip2. Тут масив суфіксів дозволяє перетворення вхідних даних у форму, більш сприятливу до стиснення, шляхом зкладання подібних символів разом bzip2.
Окрім цих, масиви суфіксів також використовуються в системах виявлення плагіату, дуплікації даних та побудові ефективних структур даних для запитів найдовших спільних префіксів (LCP). Їх універсальність та ефективність роблять їх незамінними у застосуваннях, де необхідна швидка та масштабована обробка рядків.
Оптимізація пошуку та зіставлення шаблонів з масивами суфіксів
Масиви суфіксів є потужними структурами даних, які значно оптимізують операції пошуку та зіставлення шаблонів у рядках. Зберігаючи початкові індекси всіх суфіксів тексту в лексикографічному порядку, масиви суфіксів дозволяють виконувати ефективні запити на підрядки, що є основоположними в таких застосуваннях, як повнотекстовий пошук, біоінформатика та стиснення даних. Головною перевагою використання масиву суфіксів над наївними методами пошуку є зменшення часової складності для зіставлення шаблонів. Хоча у грубій силі підхід може вимагати O(nm) часу для тексту довжини n та шаблону довжини m, масиви суфіксів дозволяють проводити пошуки шаблонів за O(m + log n) часу, використовуючи бінарний пошук на відсортованих суфіксах.
Щоб ще більше підвищити продуктивність, масиви суфіксів часто використовуються разом із допоміжними структурами даних, такими як масив найдовших спільних префіксів (LCP). Масив LCP зберігає довжини найдовших спільних префіксів між послідовними суфіксами в масиві суфіксів, що дозволяє ще швидше виконувати зіставлення шаблонів і полегшує завдання на кшталт знаходження кількості різних підрядків або найдовшого повторюваного підрядка за лінійний час. Крім того, сучасні алгоритми для побудови масивів суфіксів, такі як метод індукованого сортування, досягають лінійної часової складності, що робить їх практичними для великих текстів (Гельсінський університет).
Масиви суфіксів також є економічними в плані пам’яті в порівнянні з деревами суфіксів, оскільки вони потребують лише O(n) пам’яті і легші у впровадженні. Їхня ефективність і універсальність роблять їх наріжним каменем у розробці швидких і масштабованих систем індексування тексту та зіставлення шаблонів (Принстонський університет).
Звичні алгоритми, що використовують масиви суфіксів
Масиви суфіксів є основоположними структурами даних в обробці рядків, які дозволяють ефективно знаходити рішення для різноманітних складних задач. Кілька звичних алгоритмів використовують масиви суфіксів для досягнення оптимальної або майже оптимальної продуктивності, зокрема в сфері зіставлення шаблонів, стиснення даних та біоінформатики.
Одним із найпомітніших застосувань є пошук підрядків. Поєднуючи масив суфіксів з бінарним пошуком, можна знайти всі випадки наявності шаблону в тексті за O(m log n) часу, де m — це довжина шаблону, а n — довжина тексту. Цей підхід є значно швидшим за наївні методи пошуку, особливо для великих текстів. Крім того, масив найдовших спільних префіксів (LCP) часто будується разом із масивом суфіксів, щоб додатково оптимізувати запити на повторювані шаблони та полегшити алгоритми для пошуку найдовшого повторюваного підрядка або найдовшого спільного підрядка між кількома рядками.
Масиви суфіксів також є невід’ємною частиною алгоритмів стиснення даних, таких як перетворення Бурроуза-Уїлера (BWT), яке є ключовим елементом інструменту стиснення bzip2. BWT покладається на відсортований порядок суфіксів для перетворення вхідного тексту, що робить його більш придатним для кодування довгих рядків та інших технік стиснення (bzip2).
У біоінформатиці масиви суфіксів використовуються для ефективного вирівнювання послідовностей та аналізу геномів, де швидкий пошук і порівняння послідовностей ДНК є критично важливими (Національний центр біотехнологічної інформації). Їх економічність у пам’яті та швидкість роблять їх кращими за дерева суфіксів у багатьох великих застосуваннях.
Розгляд продуктивності та обмеження
Масиви суфіксів є надзвичайно ефективними структурами даних для вирішення різноманітних задач обробки рядків, таких як пошук підрядків, зіставлення шаблонів і обчислення найдовшого спільного префікса. Однак їх продуктивність та застосовність залежать від кількох факторів і внутрішніх обмежень.
Одним із основних факторів продуктивності є час побудови. У той час як наївні алгоритми для створення масивів суфіксів працюють за O(n log2 n) часу, більш прогресивні алгоритми досягають лінійної часової складності, таких як алгоритм SA-IS. Проте ці оптимальні алгоритми можуть бути складними у впровадженні і мати значні константні фактори, що можуть вплинути на практичну продуктивність, особливо для дуже великих текстів або в середовищах з обмеженою пам’яттю. Просторова складність є ще одним важливим аспектом: масив суфіксів зазвичай вимагає O(n) пам’яті, але допоміжні структури, такі як масив найдовших спільних префіксів (LCP), або додаткові індексуючі структури можуть ще більше збільшити використання пам’яті Гельсінський університет.
Масиви суфіксів гірше реагують на динамічні зміни, такі як вставки або видалення в тексті. Зміна масиву суфіксів після його побудови не є тривіальною і часто вимагає відбудови всієї структури, що робить їх менш підходящими для застосувань, в яких базовий текст часто змінюється Університет Карнегі-Меллона. Крім того, хоча масиви суфіксів є більш економічними в пам’яті, ніж дерева суфіксів, вони все ще можуть бути непридатними для надзвичайно великих наборів даних, таких як цілі геномні послідовності, без подальшого стиснення або зовнішніх методів пам’яті Національний центр біотехнологічної інформації.
Коротко кажучи, хоча масиви суфіксів пропонують значні переваги в термінах швидкості та економії пам’яті для статичних текстів, їх обмеження в динамічних сценаріях і масштабних застосуваннях потрібно ретельно враховувати під час проєктування системи.
Справжні випадки використання та приклади
Масиви суфіксів широко використовуються в різних реальних застосуваннях, які потребують ефективної обробки рядків та зіставлення шаблонів. Один із найпомітніших випадків використання — це біоінформатика, особливо в секвенуванні та аналізі геному. Інструменти, такі як Burrows-Wheeler Aligner, використовують масиви суфіксів для швидкого вирівнювання коротких ДНК-читів до референтних геномів, що дозволяє здійснювати великомасштабні геномні дослідження та персоналізовану медицину.
У інформаційному пошуку масиви суфіксів є основоположними для реалізації швидких повнотекстових пошукових систем. Наприклад, проект Apache Lucene використовує масиви суфіксів та відповідні структури даних для забезпечення ефективних можливостей пошуку підрядків, що є необхідним для індексування та запитів до великих текстових корпусів.
Масиви суфіксів також виконують ключову роль в алгоритмах стиснення даних. Інструмент стиснення bzip2, наприклад, використовує перетворення Бурроуза-Уїлера, яке спирається на побудову масиву суфіксів для перетворення вхідних даних і підвищення стиснень.
Додатково масиви суфіксів використовуються в системах виявлення плагіату, таких як Turnitin, для виявлення подібностей між документами шляхом ефективного порівняння підрядків. У обробці природної мови вони використовуються для завдань, таких як виявлення повторюваних фраз, вилучення ключових слів і створення конкорданцій.
Ці приклади підкреслюють універсальність та ефективність масивів суфіксів у виконанні задач великомасштабної обробки рядків у різних сферах, від обчислювальної біології до пошукових систем і стиснення даних.
Подальше читання та розширені теми
Для читачів, які хочуть заглибитися в масиви суфіксів, доступно кілька розширених тем і ресурсів. Однією з важливих областей є вивчення поліпшених масивів суфіксів, які доповнюють базову структуру додатковими даними, такими як масив найдовших спільних префіксів (LCP), що дозволяє більш ефективно виконувати зіставлення шаблонів і запити на підрядки. Взаємозв’язок між масивами суфіксів та деревами суфіксів також є багатою областю, оскільки обидві структури вирішують подібні проблеми, але з різними компромісами в термінах простору та часу побудови.
Нещодавні дослідження зосереджені на алгоритмах побудови в лінійний час для масивів суфіксів, таких як алгоритми SA-IS та DC3 (Skew), які є критичними для обробки великомасштабних геномних чи текстових даних. Ці алгоритми докладно обговорюються в літературі, включаючи основоположну роботу Групи функціональних масивів суфіксів Гельсінського університету.
Застосування масивів суфіксів виходить за межі зіставлення рядків до таких областей, як стиснення даних (наприклад, перетворення Бурроуза-Уїлера), біоінформатика (складання та вирівнювання геномів) і інформаційний пошук. Для всебічного огляду рекомендується книга Algorithms on Strings, Trees, and Sequences Дена Гасфілда.
- Масиви суфіксів: новий метод для он-лайн пошуку рядків (оригінальна стаття Манбера і Майєра)
- Лінійний алгоритм конструювання масиву суфіксів за допомогою індукованого сортування (алгоритм SA-IS)
- Wikipedia: Масив суфіксів (огляд та подальші посилання)
Джерела та посилання
- Американське математичне товариство
- Принстонський університет
- Кафедра комп’ютерних наук Гельсінського університету
- GeeksforGeeks
- Національний центр біотехнологічної інформації
- Університет Карнегі-Меллона
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Масив суфіксів