Ovladavanje Suffix Nizovima: Definitivni Vodič za Efikasnu Obradu Stringova i Pretragu Šablona. Otkrijte Kako Suffix Nizovi Revolucioniraju Algoritme za Tekst.
- Uvod u Suffix Nizove
- Kako Suffix Nizovi Funkcionišu: Osnovni Koncepti
- Izgradnja Suffix Niza: Korak po Korak
- Suffix Nizovi vs. Suffix Drveće: Ključne Razlike
- Primena Suffix Nizova u Računarskoj Nauci
- Optimizacija Pretrage i Pretrage Šablona uz Suffix Nizove
- Uobičajeni Algoritmi koji Iskorišćavaju Suffix Nizove
- Razmatranja o Performansama i Ograničenja
- Praktične Upotrebe i Primeri
- Dalje Čitanje i Napredne Teme
- Izvori i Reference
Uvod u Suffix Nizove
Suffix niz je moćna struktura podataka koja se koristi u obradi stringova, posebno za efikasno pretraživanje šablona, upite na podstringove i indeksiranje teksta. Predstavlja sortirani redosled svih suffixa datog stringa, obično kao niz početnih indeksa. Ova struktura omogućava razne primene u oblasti kao što su bioinformatika, kompresija podataka i preuzimanje informacija, gde su brza pretraga i analiza velikih tekstova od suštinskog značaja.
Koncept suffix niza uveden je kao prostor-efikasna alternativa suffix drvetu, nudeći slične funkcionalnosti ali sa smanjenim troškovima memorije. Za razliku od suffix stabala, koja mogu biti kompleksna za implementaciju i održavanje, suffix nizovi su jednostavniji i kompaktniji, što ih čini pogodnim za obradu velikih tekstova. Izgradnja suffix niza podrazumeva sortiranje svih mogućih suffixa datog stringa, što se može postići za O(n log n) vremena korišćenjem algoritama zasnovanih na poređenju ili čak u linearnom vremenu uz naprednije tehnike poput metode indukovanog sortiranja (Američko matematičko društvo).
Suffix nizovi se često koriste u kombinaciji sa pomoćnim strukturama podataka kao što je niz najdužih zajedničkih prefiksa (LCP), što dodatno poboljšava njihovu korisnost pri rešavanju problema kao što su pronalaženje najdužeg ponovljenog podstringa ili izvođenje brzih leksikografskih poređenja. Njihova efikasnost i svestranost učinile su suffix nizove osnovnim alatom u savremenoj algoritamskoj analizi stringova (Princeton University).
Kako Suffix Nizovi Funkcionišu: Osnovni Koncepti
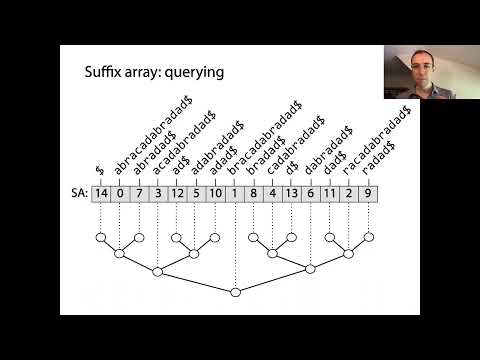
Suffix nizovi su moćne strukture podataka koje omogućavaju efikasnu obradu stringova, posebno za pretragu šablona i indeksiranje teksta. U svojoj suštini, suffix nizovi predstavljaju sortirani redosled svih mogućih suffixa datog stringa. Izgradnja počinje generisanjem svakog suffixa ulaznog stringa, svaki počinjući na različitoj poziciji. Ovi suffixi se zatim sortiraju leksikografski, a suffix niz sam po sebi je niz celih brojeva, gde svaki unos označava početni indeks suffixa u ovom sortiranom redosledu.
Ključna ideja iza suffix nizova je da, sortirajući sve suffixe, možete izvršiti brze binarne pretrage za lociranje podstringova ili šablona unutar originalnog teksta. Ovo je značajno poboljšanje u odnosu na naivne metode pretrage, koje mogu zahtevati skeniranje celog teksta za svaki upit. Suffix nizovi se često koriste zajedno sa nizom najdužih zajedničkih prefiksa (LCP), koji čuva dužine najdužih zajedničkih prefiksa između uzastopnih suffixa u sortiranom nizu. Ova kombinacija dodatno ubrzava razne operacije na stringovima, kao što su pronalaženje ponovljenih podstringova ili broja različitih podstringova.
Efikasni algoritmi za izgradnju, kao što su metoda indukovanog sortiranja ili korišćenje dupliranja prefikasa, smanjili su vremensku složenost izgradnje suffix nizova na linearno ili skoro linearno vreme, što ih čini praktičnim za primene velikih razmera. Suffix nizovi su široko korišćeni u bioinformatici, kompresiji podataka i preuzimanju informacija, gde je brza i efikasna obrada stringova od suštinskog značaja. Za sveobuhvatan pregled osnovnih principa i algoritama, konsultujte dokumentaciju Katedre za Računarske Nauke, Univerzitet Helsinki.
Izgradnja Suffix Niza: Korak po Korak
Izgradnja suffix niza obuhvata konstruisanje sortiranog niza svih suffixa datog stringa, predstavljenih njihovim početnim indeksima. Proces se može podeliti na nekoliko ključnih koraka:
- 1. Generisanje Svi Suffixi: Za string dužine n, nabrojati sve suffixe po njihovim početnim pozicijama. Na primer, string „banana“ daje suffixe koji počinju na indeksima 0 („banana“), 1 („anana“), 2 („nana“), i tako dalje.
- 2. Sortiranje Suffixa: Sortirajte ove suffixe leksikografski. Ovo se može postići naivno u O(n2 log n) vremenu direktnim poređenjem stringova, ali postoje i efikasniji algoritmi.
- 3. Čuvanje Indeksa: Umesto da čuvate stvarne stringove suffixa, čuvate njihove početne indekse u sortiranom redosledu. Ovaj niz indeksa je suffix niz.
- 4. Optimizacija: Napredni algoritmi, kao što je Manber-Myers algoritam, koriste tehniku dupliranja kako bi postigli O(n log n) vremensku složenost. Čak brži, Karkkainen-Sanders algoritam (poznat i kao Skew algoritam) može konstruisati suffix niz u linearnom vremenu O(n) za celobrojne abecede. Ove metode se oslanjaju na sortiranje po rangovima i rekurzivnim strategijama kako bi se izbeglo direktno poređenje stringova Asocijacija za Računarske Mašinstvo.
- 5. Konačni Izlaz: Rezultantni suffix niz omogućava efikasno pretraživanje šablona, upite za podstringove i osnova je za konstruisanje drugih struktura podataka kao što je LCP niz GeeksforGeeks.
Razumevanje svakog koraka i dostupnih optimizacija je ključno za korišćenje suffix nizova u primenama obrade stringova velikih razmera.
Suffix Nizovi vs. Suffix Drveće: Ključne Razlike
Suffix nizovi i suffix drveće su osnovne strukture podataka za efikasnu obradu stringova, posebno u primenama kao što su pretraga šablona, bioinformatika i kompresija podataka. Dok obavljaju slične svrhe, njihove strukture, zahtevi za memorijom i operativne karakteristike se značajno razlikuju.
Suffix drvo je kompresovana trie svih suffixa datog stringa, koje omogućava ekstremno brze upite na podstringovima, obično u linearno vreme u odnosu na dužinu šablona. Međutim, suffix drveće je kompleksno za implementaciju i zahteva značajnu memorijsku potrošnju — često nekoliko puta veličine originalnog stringa — zbog svoje strukture zasnovane na čvorovima i potrebe za čuvanjem pokazivača i oznaka ivica. Ovo ih čini manje praktičnim za veoma velike skupove podataka ili okruženja sa ograničenom memorijom.
Nasuprot tome, suffix niz je mnogo jednostavnija i prostor-efikasnija struktura podataka. Sadrži niz celih brojeva koji predstavljaju početne pozicije svih sortiranih suffixa stringa. Suffix nizovi se mogu konstruisati u linearnom vremenu i zahtevaju samo O(n) prostora, gde je n dužina stringa. Dok su pretrage podstringova korišćenjem suffix niza obično sporije nego sa suffix drvetom (O(m log n) za šablon dužine m), ovo se može poboljšati na O(m) uz pomoć pomoćnih struktura podataka kao što je niz najdužih zajedničkih prefiksa (LCP). Jednostavnost i manji trošak memorije suffix nizova čine ih pogodnijim za velike zadatke indeksiranja teksta i pretrage.
Za detaljno poređenje i dalje čitanje, pogledajte Asocijaciju za Računarske Mašinstvo i GeeksforGeeks.
Primena Suffix Nizova u Računarskoj Nauci
Suffix nizovi su postali osnovna struktura podataka u računarstvu, posebno u oblastima obrade stringova, bioinformatike i preuzimanja informacija. Njihova primarna korisnost leži u omogućavanju efikasnog pretraživanja šablona i upita na podstringovima. Na primer, suffix nizovi se široko koriste u pretraživačima punog teksta, gde omogućavaju brzo identifikovanje svih pojavljivanja upitnog podstringa unutar velikog korpusa teksta. Ovo se postiže korišćenjem leksikografski sortiranog reda suffixa, koji podržava binarne pretrage za pretragu šablona u logaritamskoj vremenskoj složenosti Princeton University.
U bioinformatici, suffix nizovi olakšavaju poravnavanje i upoređivanje DNK i proteinskih sekvenci. Alati za sastavljanje genoma i poravnavanje sekvenci, kao što su oni koji se koriste u sekvenciranju nove generacije, često se oslanjaju na suffix nizove kako bi efikasno obrađivali ogromne biološke skupove podataka Nacionalni centar za biotehnološke informacije. Pored toga, suffix nizovi su ključni za algoritme kompresije podataka kao što je Burrows-Wheeler transformacija, koja je osnova popularnih alata za kompresiju kao što je bzip2. Ovde, suffix niz omogućava transformaciju ulaznih podataka u oblik koji je pogodniji za kompresiju grupisanjem sličnih karaktera zajedno bzip2.
Pored ovoga, suffix nizovi se takođe koriste u detekciji plagijata, duplikaciji podataka i konstrukciji efikasnih struktura podataka za upite najdužeg zajedničkog prefiksa (LCP). Njihova svestranost i efikasnost čine ih nezamenljivim u primenama gde su potrebni brza i skalabilna obrada stringova.
Optimizacija Pretrage i Pretrage Šablona uz Suffix Nizove
Suffix nizovi su moćne strukture podataka koje značajno optimizuju operacije pretrage i pretrage šablona u stringovima. Čuvajući početne indekse svih suffixa teksta u leksikografskom redosledu, suffix nizovi omogućavaju efikasne upite na podstringovima, što je osnovno u primenama kao što su pretraga punog teksta, bioinformatika i kompresija podataka. Primarna prednost korišćenja suffix niza u odnosu na naivne metode pretrage je smanjen vremenski složenost za pretragu šablona. Dok bi pristup silom mogao zahtevati O(nm) vremena za tekst dužine n i šablon dužine m, suffix nizovi omogućavaju pretragu šablona u O(m + log n) vremenu koristeći binarnu pretragu na sortiranih suffixima.
Da bi se dodatno poboljšala performansa, suffix nizovi se često koriste zajedno sa pomoćnim strukturama podataka kao što je niz najdužih zajedničkih prefiksa (LCP). LCP niz čuva dužine najdužih zajedničkih prefiksa između uzastopnih suffixa u suffix nizu, omogućavajući još bržu pretragu šablona i olakšavajući zadatke poput pronalaženja broja različitih podstringova ili najdužeg ponovljenog podstringa u linearnom vremenu. Pored toga, moderni algoritmi za konstrukciju suffix nizova, kao što je metoda indukovanog sortiranja, postižu linearnu vremensku složenost, što ih čini praktičnim za tekstove velikih razmera (Univerzitet Helsinki).
Suffix nizovi su takođe prostor-efikasni u poređenju sa suffix stablima, jer zahtevaju samo O(n) prostora i lakši su za implementaciju. Njihova efikasnost i svestranost čine ih kamen-temeljac u dizajnu brzih i skalabilnih sistema za indeksiranje teksta i pretragu šablona (Princeton University).
Uobičajeni Algoritmi koji Iskorišćavaju Suffix Nizove
Suffix nizovi su osnovna struktura podataka u obradi stringova, omogućavajući efikasna rešenja za razne složene probleme. Nekoliko uobičajenih algoritama iskorišćava suffix nizove kako bi postiglo optimalne ili skoro optimalne performanse, posebno u oblastima pretrage šablona, kompresije podataka i bioinformatike.
Jedna od najistaknutijih primena je u pretrazi podstringova. Kombinovanjem suffix niza sa binarnom pretragom, moguće je locirati sve pojave šablona u tekstu u O(m log n) vremenu, gde je m dužina šablona a n dužina teksta. Ovaj pristup je značajno brži od naivnih metoda pretrage, posebno za velike tekstove. Pored toga, niz najdužih zajedničkih prefiksa (LCP) se često konstruira zajedno sa suffix nizom da bi dodatno optimizovao upite o ponovljenim šablonima i olakšao algoritme za pronalaženje najdužeg ponovljenog podstringa ili najdužeg zajedničkog podstringa između više stringova.
Suffix nizovi su takođe integralni za algoritme kompresije podataka kao što je Burrows-Wheeler transformacija (BWT), koja je ključna komponenta alata za kompresiju bzip2. BWT se oslanja na sortirani redosled suffixa za preuređivanje ulaznog teksta, čineći ga pogodnijim za kodiranje dužine trčanja i druge tehnike kompresije (bzip2).
U bioinformatici, suffix nizovi se koriste za efikasno poravnavanje sekvenci i analizu genoma, gde su brza pretraga i poređenje DNK sekvenci od suštinskog značaja (Nacionalni centar za biotehnološke informacije). Njihova efikasnost u korišćenju prostora i brzina čine ih pogodnijim od suffix stabala u mnogim primenama velikih razmera.
Razmatranja o Performansama i Ograničenja
Suffix nizovi su vrlo efikasne strukture podataka za rešavanje raznih problema obrade stringova, kao što su pretraga podstringova, pretraga šablona i proračun najdužeg zajedničkog prefiksa. Međutim, njihova performansa i primenljivost utiču na nekoliko razmatranja i inherentnih ograničenja.
Jedan od glavnih faktora performansi je vreme konstrukcije. Dok naivni algoritmi za izgradnju suffix nizova funkcionišu u O(n log2 n) vremenu, napredniji algoritmi postižu linearnu vremensku složenost, kao što je SA-IS algoritam. Ipak, ovi optimalni algoritmi mogu biti složeni za implementaciju i mogu imati značajne konstantne faktore, što može uticati na praktičnu performansu, posebno za veoma velike tekstove ili u okruženjima sa ograničenom memorijom. Složenost memorije je još jedan važan aspekt; suffix niz obično zahteva O(n) prostora, ali pomoćne strukture poput niza najdužih zajedničkih prefiksa (LCP) ili dodatne strukture indeksiranja mogu dodatno povećati potrošnju memorije Univerzitet Helsinki.
Suffix nizovi su manje fleksibilni od suffix stabala kada je reč o dinamičkim ažuriranjima, kao što su umetanja ili brisanja unutar teksta. Izmene suffix niza nakon njegove izgradnje nisu trivijalne i često zahtevaju ponovnu izgradnju cele strukture, čineći ih manje pogodnim za primene gde se osnovni tekst često menja Carnegie Mellon University. Pored toga, dok su suffix nizovi efikasniji u korišćenju prostora od suffix stabala, mogu i dalje biti nepraktični za ekstremno velike skupove podataka, poput celine genetskih sekvenci, bez daljih tehnika kompresije ili spoljnog memorijskog rešenja Nacionalni centar za biotehnološke informacije.
U zaključku, dok suffix nizovi nude značajne prednosti u smislu brzine i efikasnosti memorije za statične tekstove, njihova ograničenja u dinamičkim scenarijima i aplikacijama velikih razmera moraju se pažljivo razmotriti tokom dizajna sistema.
Praktične Upotrebe i Primeri
Suffix nizovi se široko koriste u raznim praktičnim aplikacijama koje zahtevaju efikasnu obradu stringova i pretragu šablona. Jedna od najistaknutiijih oblasti primene je u bioinformatici, posebno u sekvenciranju i analizi genoma. Alati kao što su Burrows-Wheeler Aligner koriste suffix nizove za brzo poravnavanje kratkih DNK očitavanja sa referentnim genomima, omogućavajući velika genomska istraživanja i personalizovanu medicinu.
U pretrazi informacija, suffix nizovi su osnovni za implementaciju brzih pretraživača punog teksta. Na primer, Apache Lucene projekat koristi suffix nizove i srodne strukture podataka za obezbeđivanje efikasnih mogućnosti pretrage podstringova, koje su od suštinskog značaja za indeksiranje i upite velikih tekstualnih korpusa.
Suffix nizovi takođe igraju ključnu ulogu u algoritmima kompresije podataka. Alat za kompresiju bzip2, na primer, koristi Burrows-Wheeler transformaciju, koja se oslanja na konstrukciju suffix niza kako bi preuredila ulazne podatke i poboljšala kompresibilnost.
Pored toga, suffix nizovi se koriste u sistemima za detekciju plagijata, kao što je Turnitin, za identifikaciju sličnosti između dokumenata efikasnim poređenjem podstringova. U obradi prirodnog jezika, koriste se za zadatke poput identifikacije ponavljajućih fraza, vađenja ključnih reči i izrade konkordanasa.
Ovi primeri ističu svestranost i efikasnost suffix nizova u rukovanju zadacima obrade stringova velikih razmera u raznim domenima, od kompjuterske biologije do pretraživača i kompresije podataka.
Dalje Čitanje i Napredne Teme
Za čitaoce koji su zainteresovani da dublje istraže suffix nizove, dostupne su brojne napredne teme i resursi. Jedna značajna oblast je proučavanje poboljšanih suffix nizova, koji nadograđuju osnovnu strukturu dodatnim podacima kao što je niz najdužih zajedničkih prefiksa (LCP), omogućavajući efikasnije pretrage šablona i upite na podstringovima. Interakcija između suffix nizova i suffix stabala je takođe bogato polje, jer obe strukture rešavaju slične probleme ali sa različitim kompromisima u pogledu prostora i vremena konstrukcije.
Nedavna istraživanja su se fokusirala na algoritme konstrukcije u linearno vreme za suffix nizove, kao što su SA-IS i DC3 (Skew) algoritmi, koji su ključni za obradu velikih genetskih ili tekstualnih podataka. Ovi algoritmi se detaljno razmatraju u literaturi, uključujući osnovni rad Grupe za funkcionalne suffix nizove Univerziteta Helsinki.
Primene suffix nizova se protežu dalje od pretrage stringova u oblasti kao što su kompresija podataka (npr. Burrows-Wheeler transformacija), bioinformatika (sastavljanje i poravnavanje genoma) i preuzimanje informacija. Za sveobuhvatan pregled, knjiga Algoritmi na Stringovima, Stablima i Sekvencama autora Dana Gusfield-a je toplo preporučena.
- Suffix Nizovi: Nova Metoda za Online Pretrage Stringova (originalni rad Manber & Myers)
- Izgradnja Suffix Niza u Linearnom Vremenu Korišćenjem Indukovanog Sortiranja (SA-IS algoritam)
- Wikipedia: Suffix Niz (pregled i dalje veze)
Izvori i Reference
- Američko matematičko društvo
- Princeton University
- Katedra za Računarske Nauke, Univerzitet Helsinki
- GeeksforGeeks
- Nacionalni centar za biotehnološke informacije
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algoritmi na Stringovima, Stablima i Sekvencama
- Wikipedia: Suffix Niz