Obvladovanje sufixnih tabel: Ultimativni vodnik za učinkovito obdelavo nizov in ujemanje vzorcev. Odkrijte, kako sufixne tabele revolucionirajo algoritme za obdelavo besedil.
- Uvod v sufixne tabele
- Kako delujejo sufixne tabele: Temeljni koncepti
- Izgradnja sufixne tabele: Korak za korakom
- Sufixne tabele vs. sufixna drevesa: Ključne razlike
- Uporaba sufixnih tabel v računalništvu
- Optimizacija iskanja in ujemanja vzorcev s sufixnimi tabelami
- Pogosti algoritmi, ki izkoriščajo sufixne tabele
- Upoštevanje zmogljivosti in omejitve
- Primeri uporabe v resničnem svetu
- Dodatno branje in napredne teme
- Viri in reference
Uvod v sufixne tabele
Sufixna tabela je močna podatkovna struktura, ki se uporablja pri obdelavi nizov, zlasti za učinkovito ujemanje vzorcev, poizvedbe podnizov in indeksiranje besedil. Predstavlja urejeno vrsto vseh sufixov danega niza, običajno kot tabelo začetnih indeksov. Ta struktura omogoča različne uporabe na področjih, kot so bioinformatika, stiskanje podatkov in pridobivanje informacij, kjer je hitro iskanje in analiza velikih besedil ključnega pomena.
Koncept sufixne tabele je bil uveden kot prostor-efficient alternativa sufixnemu drevesu, ki ponuja podobne funkcionalnosti, vendar z zmanjšanim pomnilniškim odhodkom. V nasprotju s sufixnimi drevesi, ki so lahko zapleteni za implementacijo in vzdrževanje, so sufixne tabele preprostejše in bolj kompaktne, kar jih naredi primerne za obsežne naloge obdelave besedil. Konstrukcija sufixne tabele vključuje razvrščanje vseh možnih sufixov niza, kar se lahko doseže v O(n log n) času z algoritmi, temelječimi na primerjavi, ali celo v linearni čas s spretnimi tehnikami, kot je metoda indukcijskega razvrščanja (American Mathematical Society).
Sufixne tabele se pogosto uporabljajo v kombinaciji z pomožnimi podatkovnimi strukturami, kot je tabela najdaljših skupnih predpon (LCP), kar še dodatno povečuje njihovo uporabnost pri reševanju težav, kot je iskanje najdaljšega ponovljenega podniza ali hitro leksikografsko primerjanje. Njihova učinkovitost in vsestranskost sta sufixne tabele naredila za temeljno orodje v sodobni algoritmični analizi nizov (Princeton University).
Kako delujejo sufixne tabele: Temeljni koncepti
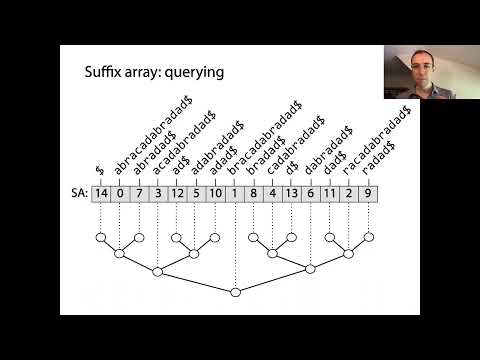
Sufixne tabele so močne podatkovne strukture, ki omogočajo učinkovito obdelavo nizov, zlasti za ujemanje vzorcev in indeksiranje besedil. V svojem jedru sufixne tabele predstavljajo urejeno vrsto vseh možnih sufixov danega niza. Konstrukcija se začne z generiranjem vsakega sufixa vhodnega niza, pri čemer vsak sufix začne na drugi poziciji. Ti sufixi so nato razvrščeni leksikografsko, sufixna tabela pa je sama po sebi tabela celih števil, kjer vsak vnos označuje začetni indeks sufixa v tem urejenem vrstnem redu.
Ključna zamisel za sufixne tabele je, da z razvrščanjem vseh sufixov lahko hitro izvajamo binarna iskanja za lociranje podnizov ali vzorcev znotraj originalnega besedila. To je vidna izboljšava v primerjavi z naivnimi metodami iskanja, ki morda zahtevajo skeniranje celotnega besedila za vsako poizvedbo. Sufixne tabele se pogosto uporabljajo v kombinaciji s tabelo najdaljših skupnih predpon (LCP), ki shranjuje dolžine najdaljših skupnih predpon med zaporednimi sufixi v razvrščeni tabeli. Ta povezava dodatno pospeši različne operacije z nizi, kot so iskanje ponovljenih podnizov ali število različnih podnizov.
Učinkoviti algoritmi konstrukcije, kot sta metoda indukcijskega razvrščanja ali uporaba podvajanja predpon, so zmanjšali časovno zapletenost pri gradnji sufixnih tabel na linearni ali skoraj-linearni čas, kar jih naredi praktične za obsežne aplikacije. Sufixne tabele se široko uporabljajo v bioinformatiki, stiskanju podatkov in pridobivanju informacij, kjer je hitra in pomnilniško učinkovita obdelava nizov ključnega pomena. Za celovit pregled osnovnih načel in algoritmov se sklicujte na dokumentacijo Oddelka za računalništvo na Universiteti v Helsinkih.
Izgradnja sufixne tabele: Korak za korakom
Izgradnja sufixne tabele vključuje konstrukcijo razvrščene tabele vseh sufixov danega niza, ki jih predstavljajo njihovi začetni indeksi. Proces lahko razdelimo na več ključnih korakov:
- 1. Generiranje vseh sufixov: Za niz dolžine n naštetje vse sufixe po njihovih začetnih pozicijah. Na primer, niz “banana” daje sufixe, ki se začnejo na indeksih 0 (“banana”), 1 (“anana”), 2 (“nana”) itd.
- 2. Razvrščanje sufixov: Razvrstite te sufixe leksikografsko. To se da naivno storiti v O(n2 log n) času z neposrednim primerjanjem nizov, vendar obstajajo bolj učinkoviti algoritmi.
- 3. Shranjevanje indeksov: Namesto shranjevanja dejanskih sufix nizov shranite njihove začetne indekse v razvrščenem vrstnem redu. Ta tabela indeksov je sufixna tabela.
- 4. Optimizacija: Napredni algoritmi, kot je Manber-Myers algoritem, uporabljajo tehniko podvajanja za dosego O(n log n) časovne zapletenosti. Še hitreje pa je Karkkainen-Sanders algoritem (znan tudi kot Skew algoritem), ki lahko konstruira sufixno tabelo v linearnem času O(n) za cele abecede. Te metode temeljijo na razvrščanju po rangih in rekurzivnih strategijah, da se izognejo neposrednim primerjavam nizov Association for Computing Machinery.
- 5. Končni izhod: Rezultantna sufixna tabela omogoča učinkovito ujemanje vzorcev, poizvedbe podnizov in je temeljna za konstrukcijo drugih podatkovnih struktur, kot je tabela LCP GeeksforGeeks.
Razumevanje vsakega koraka in razpoložljivih optimizacij je ključno za izkoriščanje sufixnih tabel v obsežnih apliciranih nalogah obdelave nizov.
Sufixne tabele vs. sufixna drevesa: Ključne razlike
Sufixne tabele in sufixna drevesa so osnovne podatkovne strukture za učinkovito obdelavo nizov, zlasti pri aplikacijah, kot so ujemanje vzorcev, bioinformatika in stiskanje podatkov. Medtem ko imata podobne namene, se njune strukture, zahteve po pomnilniku in operativne značilnosti znatno razlikujejo.
Sufixno drevo je stisnjen trie vseh sufixov danega niza, ki omogoča izjemno hitro poizvedbo podnizov, običajno v linearnem času glede na dolžino vzorca. Vendar pa so sufixna drevesa zapletena za implementacijo in zahtevajo znatno pomnilniško obremenitev—pogosto večkratno edina velikost originalnega niza—zaradi svoje strukture vozlišč in potrebe po shranjevanju kazalcev in oznak robov. To jih naredi manj praktične za zelo obsežne podatkovne nizove ali okolja s pomanjkanjem pomnilnika.
Nasprotno pa je sufixna tabela precej preprostejša in bolj prostorsko učinkovita podatkovna struktura. Sestavljena je iz tabele celih števil, ki predstavljajo začetne pozicije vseh razvrščenih sufixov niza. Sufixne tabele je mogoče konstruirati v linearnem času in zahtevajo le O(n) prostora, kjer je n dolžina niza. Medtem ko so iskanja podnizov s sufixno tabelo običajno počasnejša kot s sufixnim drevesom (O(m log n) za vzorec dolžine m), se to lahko izboljša na O(m) z uporabo pomožnih podatkovnih struktur, kot je tabela LCP. Preprostost in nižji pomnilniški odtis sufixnih tabel jih naredi zaželeno izbiro za naloge indeksiranja besedil in iskanja v velikem obsegu.
Za podrobno primerjavo in dodatno branje si oglejte Association for Computing Machinery in GeeksforGeeks.
Uporaba sufixnih tabel v računalništvu
Sufixne tabele so postale temeljna podatkovna struktura v računalništvu, zlasti na področju obdelave nizov, bioinformatike in pridobivanja informacij. Njihova glavna uporabnost leži v omogočanju učinkovitega ujemanja vzorcev in poizvedb podnizov. Na primer, sufixne tabele se široko uporabljajo v iskalnikih, kjer omogočajo hitro identifikacijo vseh pojavitev poizvedbenega podniza znotraj velikega besedilnega korpusa. To se doseže z izkoriščanjem leksikografsko razvrščenega reda sufixov, ki podpira binarne iskalne operacije za ujemanje vzorcev v logaritmični časovni zapletenosti Princeton University.
V bioinformatiki sufixne tabele olajšajo usklajevanje in primerjavo DNA in proteinskih sekvenc. Orodja za sestavljanje genoma in usklajevanje sekvenc, kot so tista, ki se uporabljajo pri naslednji generaciji sekvenciranja, pogosto zanašajo na sufixne tabele za učinkovito obravnavo obsežnih bioloških podatkov National Center for Biotechnology Information. Poleg tega so sufixne tabele integralni del algoritmov za stiskanje podatkov, kot je Burrows-Wheeler Transform, ki predstavlja osnovo za priljubljena orodja za stiskanje, kot je bzip2. Tukaj sufixna tabela omogoča transformacijo vhodnih podatkov v obliko, ki je bolj prijazna za stiskanje z zgoščevanjem podobnih znakov skupaj bzip2.
Poleg tega se sufixne tabele uporabljajo tudi pri odkrivanju plagiatov, deduplikaciji podatkov in konstrukciji učinkovitih podatkovnih struktur za poizvedbe LCP. Njihova vsestranskost in učinkovitost jih naredijo nepogrešljive v aplikacijah, kjer je potrebno hitro in skalabilno obdelovanje nizov.
Optimizacija iskanja in ujemanja vzorcev s sufixnimi tabelami
Sufixne tabele so močne podatkovne strukture, ki znatno optimizirajo iskanje in operacije ujemanja vzorcev v nizih. Z shranjevanjem začetnih indeksov vseh sufixov besedila v leksikografskem vrstnem redu omogočajo sufixne tabele učinkovite poizvedbe podnizov, ki so temeljne v aplikacijah, kot so iskanje celotnega besedila, bioinformatika in stiskanje podatkov. Glavna prednost uporabe sufixne tabele pred naivnimi metodami iskanja je zmanjšanje časovne zapletenosti pri ujemanju vzorcev. Medtem ko lahko pristop z ‘brute-force’ morda zahteva O(nm) časa za besedilo dolžine n in vzorec dolžine m, sufixne tabele omogočajo iskanje vzorcev v O(m + log n) času z izkoriščanjem binarnega iskanja na razvrščenih sufixih.
Za nadaljnje izboljšanje zmogljivosti se sufixne tabele pogosto uporabljajo v kombinaciji s pomožnimi podatkovnimi strukturami, kot je tabela najdaljših skupnih predpon (LCP). LCP tabela shranjuje dolžine najdaljših skupnih predpon med zaporednimi sufixi v sufixni tabeli, kar omogoča še hitrejše ujemanje vzorcev in poenostavi naloge, kot je iskanje števila različnih podnizov ali najdaljšega ponovljenega podniza v linearnem času. Poleg tega sodobni algoritmi za konstrukcijo sufixnih tabel, kot je metoda indukcijskega razvrščanja, dosežejo linearno časovno zapletenost, kar jih naredi praktične za obsežna besedila (Universiteti v Helsinkih).
Sufixne tabele so tudi prostorsko učinkovite v primerjavi s sufixnimi drevesi, saj zahtevajo le O(n) prostora in so lažje za implementacijo. Njihova učinkovitost in vsestranskost jih naredijo za temelj pri oblikovanju hitrih in skalabilnih sistemov indeksiranja besedil in ujemanja vzorcev (Princeton University).
Pogosti algoritmi, ki izkoriščajo sufixne tabele
Sufixne tabele so temeljna podatkovna struktura v obdelavi nizov, ki omogoča učinkovite rešitve za različne zapletene probleme. Številni skupni algoritmi izkoriščajo sufixne tabele za dosego optimalne ali skoraj optimalne zmogljivosti, zlasti na področju ujemanja vzorcev, stiskanja podatkov in bioinformatike.
Ena izmed najbolj vidnih aplikacij je iskanje podnizov. S kombinacijo sufixne tabele z binarnim iskanjem je mogoče locirati vse pojavnosti vzorca v besedilu v O(m log n) času, kjer je m dolžina vzorca in n dolžina besedila. Ta pristop je bistveno hitrejši od naivnih metod iskanja, zlasti pri velikih besedilih. Poleg tega se tabela najdaljših skupnih predpon (LCP) pogosto gradi skupaj s sufixno tabelo, da dodatno optimizira poizvedbe o ponovljenih vzorcih in olajša algoritme za iskanje najdaljšega ponovljenega podniza ali najdaljšega skupnega podniza med več nizi.
Sufixne tabele so tudi integralne za algoritme stiskanja podatkov, kot je Burrows-Wheeler Transform (BWT), ki je ključna komponenta orodja za stiskanje bzip2. BWT se zanaša na razvrščen vrstni red sufixov, da preuredi vhodno besedilo, kar ga naredi bolj primernega za kodiranje dolžine ponovitev in druge tehnike stiskanja (bzip2).
V bioinformatiki se sufixne tabele uporabljajo za učinkovito usklajevanje sekvenc in analizo genoma, kjer so hitra iskanja in primerjave sekvenc DNA ključnega pomena (National Center for Biotechnology Information). Njihova prostorska učinkovitost in hitrost ju naredijo zaželeno izbiro pred sufixnimi drevesi v mnogih velikoprospeh aplikacijah.
Upoštevanje zmogljivosti in omejitve
Sufixne tabele so zelo učinkovite podatkovne strukture za reševanje različnih problemov obdelave nizov, kot so iskanje podnizov, ujemanje vzorcev in izračun najdaljših skupnih predpon. Vendar pa na njihovo zmogljivost in uporabnost vplivajo različni dejavniki in notranje omejitve.
Eden od glavnih dejavnikov zmogljivosti je čas konstrukcije. Medtem ko naivne metode za gradnjo sufixnih tabel delujejo v O(n log2 n) času, bolj napredni algoritmi dosegajo linearno časovno zapletenost, kot je algoritem SA-IS. Kljub temu so ti optimalni algoritmi lahko zapleteni za implementacijo in imajo lahko znatne konstantne dejavnike, kar lahko vpliva na praktično zmogljivost, zlasti za zelo velika besedila ali v okoljih s pomanjkanjem pomnilnika. Prostorovna kompleksnost je še en pomemben vidik; sufixna tabela običajno zahteva O(n) prostora, vendar lahko pomožne strukture, kot je tabela LCP ali dodatne indeksne strukture, še dodatno povečajo porabo pomnilnika Universiteti v Helsinkih.
Sufixne tabele so manj prilagodljive kot sufixna drevesa, ko gre za dinamične posodobitve, kot so vstavljanja ali brisanja v besedilu. Spreminjanje sufixne tabele po njeni konstrukciji ni trivialno in pogosto zahteva obnovitev celotne strukture, kar jo naredi manj primerno za aplikacije, kjer se osnovno besedilo pogosto spreminja Carnegie Mellon University. Poleg tega, čeprav so sufixne tabele bolj prostorsko učinkovite od sufixnih dreves, so lahko še vedno nepraktične za izjemno velike podatkovne nizove, kot so celotne genomske sekvence, brez dodatne kompresije ali zunanjih pomnilniških tehnik National Center for Biotechnology Information.
V povzetku, medtem ko sufixne tabele ponujajo pomembne prednosti v smislu hitrosti in učinkovitosti pomnilnika za statična besedila, je treba njihove omejitve v dinamičnih scenarijih in obsežnih aplikacijah natančno upoštevati pri načrtovanju sistema.
Primeri uporabe v resničnem svetu
Sufixne tabele se široko uporabljajo v različnih realnih aplikacijah, ki zahtevajo učinkovito obdelavo nizov in ujemanje vzorcev. Eden izmed bolj izstopajočih primerov je v bioinformatiki, zlasti pri sekvenciranju in analizi genoma. Orodja, kot je Burrows-Wheeler Aligner, uporabljajo sufixne tabele za hitro usklajevanje kratkih DNA branja z referenčnimi genom, kar omogoča obsežne genomske študije in personalizirano medicino.
V pridobivanju informacij so sufixne tabele temeljne za implementacijo hitrih iskalnikov celotnega besedila. Na primer, projekt Apache Lucene izkorišča sufixne tabele in sorodne podatkovne strukture za zagotavljanje učinkovitih sposobnosti iskanja podnizov, kar je nujno za indeksiranje in poizvedovanje velikih besedilnih korpusov.
Sufixne tabele igrajo tudi ključno vlogo v algoritmih za stiskanje podatkov. Orodje za stiskanje bzip2 na primer uporablja Burrows-Wheeler Transform, ki se zanaša na konstrukcijo sufixne tabele, da preuredi vhodne podatke in izboljša stiskanje.
Poleg tega se sufixne tabele uporabljajo v sistemih za odkrivanje plagiatov, kot je Turnitin, za identifikacijo podobnosti med dokumenti z učinkovitim primerjanjem podnizov. V obdelavi naravnega jezika se uporabljajo za naloge, kot je prepoznavanje ponovljenih fraz, ekstrakcija ključnih besed in izdelava konkordanc.
Ti primeri poudarjajo vsestranskost in učinkovitost sufixnih tabel pri obravnavi obsežnih nalog obdelave nizov v različnih domenah, od računalniške biologije do iskalnikov in stiskanja podatkov.
Dodatno branje in napredne teme
Za bralce, ki jih zanima bolj poglobljeno spoznavanje sufixnih tabel, je na voljo več naprednih tem in virov. Ena pomembna področja je študij izboljšanih sufixnih tabel, ki osnovno strukturo dopolnjujejo z dodatnimi podatki, kot je tabela najdaljših skupnih predpon (LCP), kar omogoča bolj učinkovito ujemanje vzorcev in poizvedbe podnizov. Medsebojno delovanje med sufixnimi tabelami in sufixnimi drevesi je prav tako bogato področje, saj obe strukturi rešujeta podobne probleme, a z različnimi kompromisi v zvezi s prostorom in časom konstrukcije.
Sodobne raziskave se osredotočajo na algoritme za konstrukcijo v linearnem času za sufixne tabele, kot sta SA-IS in DC3 (Skew) algoritmi, ki so ključni za obravnavo obsežnih genomski ali besedilnih podatkov. Ti algoritmi so podrobno opisani v literaturi, vključno z osnovnimi deli skupine za funkcionalne sufixne tabele na Universiteti v Helsinkih.
Uporabe sufixnih tabel segajo čez iskanje nizov na področja, kot so stiskanje podatkov (npr. Burrows-Wheeler Transform), bioinformatika (sestavljanje in usklajevanje genoma) in pridobivanje informacij. Za celovit pregled je zelo priporočena knjiga Algorithms on Strings, Trees, and Sequences avtorja Dana Gusfielda.
- Sufixne tabele: nova metoda za spletne iskanje nizov (originalni članek avtorjev Manber & Myers)
- Učinkovita konstrukcija sufixne tabele v linearni čas z uporabo indukcijskega razvrščanja (SA-IS algoritem)
- Wikipedia: Sufixna tabela (pregled in dodatne povezave)
Viri in reference
- American Mathematical Society
- Princeton University
- Oddelek za računalništvo, Univerza v Helsinkih
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Sufixna tabela