Ovládanie suffixových polí: Konečný sprievodca efektívnym spracovaním reťazca a vyhľadávaním vzorov. Objavte, ako suffixové polia revolučne menia algoritmy textu.
- Úvod do suffixových polí
- Ako fungujú suffixové polia: základné koncepty
- Vytvorenie suffixového poľa: krok za krokom
- Suffixové polia vs. Suffixové stromy: kľúčové rozdiely
- Aplikácie suffixových polí v počítačovej vede
- Optimalizácia vyhľadávania a vyhľadávania vzorov pomocou suffixových polí
- Bežné algoritmy využívajúce suffixové polia
- Výkonové úvahy a obmedzenia
- Reálne použitia a príklady
- Ďalšie čítanie a pokročilé témy
- Zdroje a odkazy
Úvod do suffixových polí
Suffixové pole je mocná dátová štruktúra používaná pri spracovaní reťazcov, najmä pre efektívne vyhľadávanie vzorov, dotazy podreťazcov a indexovanie textu. Reprezentuje zoradený poradie všetkých suffixov daného reťazca, typicky ako pole počiatočných indexov. Táto štruktúra umožňuje množstvo aplikácií v oblastiach, ako je bioinformatika, dátová kompresia a vyhľadávanie informácií, kde je rýchle vyhľadávanie a analýza veľkých textov nevyhnutná.
Koncept suffixového poľa bol predstavený ako priestorovo efektívna alternatíva k suffixovému stromu, ponúkajúca podobné funkcie, ale s menšou pamäťovou náročnosťou. Na rozdiel od suffixových stromov, ktoré môžu byť zložitým na implementáciu a údržbu, suffixové polia sú jednoduchšie a kompaktnejšie, čo ich robí vhodnými pre spracovanie veľkých textov. Skladanie suffixového poľa zahŕňa triedenie všetkých možných suffixov reťazca, čo môže byť dosiahnuté v O(n log n) čase pomocou algoritmov založených na porovnávaní, alebo dokonca v lineárnom čase s pokročilejšími technikami, ako je metóda indukovaného triedenia (Americká matematická spoločnosť).
Suffixové polia sa často používajú spolu s pomocnými dátovými štruktúrami, ako je pole najdlhších spoločných prefixov (LCP), ktoré ďalej zvyšujú ich užitočnosť pri riešení problémov, ako je vyhľadávanie najdlhšieho opakujúceho sa podreťazca alebo vykonávanie rýchlych lexikografických porovnaní. Ich efektívnosť a univerzálnosť urobili z suffixových polí základný nástroj v modernej algoritmickej analýze reťazcov (Princeton University).
Ako fungujú suffixové polia: základné koncepty
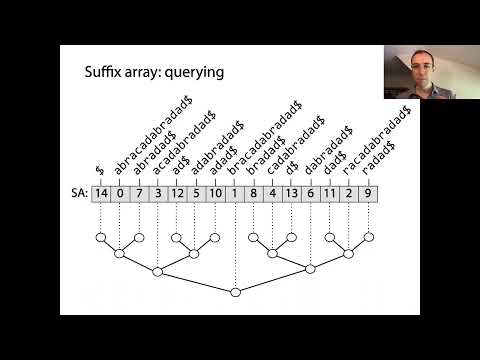
Suffixové polia sú mocné dátové štruktúry, ktoré umožňujú efektívne spracovanie reťazcov, najmä pre vyhľadávanie vzorov a indexovanie textu. V jadre predstavujú suffixové polia zoradené poradie všetkých možných suffixov daného reťazca. Skladanie začína generovaním každého suffixu vstupného reťazca, pričom každý začína na inej pozícii. Tieto suffixy sú potom triedené lexikograficky, a samotné suffixové pole je pole celých čísel, kde každý záznam označuje počiatočný index suffixu v tomto zoradenom poradí.
Kľúčovým konceptom za suffixovými poliami je, že triedením všetkých suffixov je možné vykonávať rýchle binárne vyhľadávania na lokalizáciu podreťazcov alebo vzorov v pôvodnom texte. Toto je významné zlepšenie v porovnaní s naivnými vyhľadávacími metódami, ktoré môžu vyžadovať skenovanie celého textu pre každý dotaz. Suffixové polia sa často spájajú s poľom najdlhších spoločných prefixov (LCP), ktoré uchováva dĺžky najdlhších spoločných prefixov medzi po sebe idúcimi suffixami v zoradenom poli. Toto párovanie ďalej urýchľuje rôzne operácie reťazcov, ako je vyhľadávanie opakujúcich sa podreťazcov alebo počtu rôznych podreťazcov.
Efektívne algoritmy skladania, ako metóda indukovaného triedenia alebo použitie zdvojenia prefixov, znížili časovú komplexnosť skladania suffixových polí na lineárny alebo takmer lineárny čas, čo ich robí praktickými pre aplikácie vo veľkom meradle. Suffixové polia sú široko používané v bioinformatike, dátovej kompresii a vyhľadávaní informácií, kde je rýchle a pamäťovo efektívne spracovanie reťazcov nevyhnutné. Pre komplexný prehľad základných princípov a algoritmov sa pozrite na dokumentáciu od Katedry informatiky, Helsinskej univerzity.
Vytvorenie suffixového poľa: krok za krokom
Vytvorenie suffixového poľa zahŕňa zostavenie zoradeného poľa všetkých suffixov daného reťazca, reprezentovaných ich počiatočnými indexmi. Proces sa dá rozdeliť do niekoľkých kľúčových krokov:
- 1. Generujte všetky suffixy: Pre reťazec dĺžky n vypíšte všetky suffixy podľa ich počiatočných pozícií. Napríklad reťazec „banana“ vytvára suffixy začínajúce na indexoch 0 („banana“), 1 („anana“), 2 („nana“) a tak ďalej.
- 2. Zoradťe suffixy: Zoradťe tieto suffixy lexikograficky. To sa môže urobiť naivným spôsobom v O(n2 log n) čase priamym porovnávaním reťazcov, ale existujú efektívnejšie algoritmy.
- 3. Uložte indexy: Namiesto ukladania samotných suffixových reťazcov uložte ich počiatočné indexy v zoradenom poradí. Toto pole indexov je suffixové pole.
- 4. Optimalizácia: Pokročilé algoritmy, ako algoritmus Manber-Myers, používajú techniku zdvojenia na dosiahnutie časovej zložitosti O(n log n). Ešte rýchlejšie, algoritmus Karkkainen-Sanders (tiež známy ako Skew algorithm) dokáže konštruovať suffixové pole v lineárnom čase O(n) pre celé čísla. Tieto metódy sú založené na triedení podľa hodnotenia a rekurzívnych stratégiách, ktoré sa vyhýbajú priamemu porovnávaniu reťazcov Združenie pre výpočtovú techniku.
- 5. Finálny výstup: Výsledné suffixové pole umožňuje efektívne vyhľadávanie vzorov, dotazy na podreťazce a je základom pre konštrukciu iných dátových štruktúr, ako je pole LCP GeeksforGeeks.
Pochopenie každého kroku a dostupných optimalizácií je kľúčové pre využívanie suffixových polí v aplikáciách spracovania reťazcov vo veľkom meradle.
Suffixové polia vs. Suffixové stromy: kľúčové rozdiely
Suffixové polia a suffixové stromy sú obidve základné dátové štruktúry pre efektívne spracovanie reťazcov, najmä v aplikáciách ako je vyhľadávanie vzorov, bioinformatika a dátová kompresia. Hoci plnia podobné účely, ich štruktúry, požiadavky na pamäť a operačné charakteristiky sa výrazne líšia.
Suffixový strom je komprimovaný trie všetkých suffixov daného reťazca, čo umožňuje extrémne rýchle dotazy na podreťazce, typicky v lineárnom čase vzhľadom na dĺžku vzoru. Avšak, suffixové stromy sú zložité na implementáciu a vyžadujú podstatnú pamäťovú náročnosť – často niekoľkonásobok veľkosti pôvodného reťazca – kvôli ich uzlovým štruktúram a potrebe uchovávať ukazovatele a popisy hrán. To ich robí menej praktickými pre veľmi veľké súbory údajov alebo prostredia obmedzené na pamäť.
Na druhej strane, suffixové pole je oveľa jednoduchšia a priestorovo efektívnejšia dátová štruktúra. Skladá sa z poľa celých čísel, ktoré predstavujú počiatočné pozície všetkých zoradených suffixov reťazca. Suffixové polia môžu byť konštruované v lineárnom čase a vyžadujú iba O(n) priestoru, kde n je dĺžka reťazca. Hoci vyhľadávanie podreťazcov pomocou suffixového poľa je typicky pomalšie ako so suffixovým stromom (O(m log n) pre vzor dĺžky m), toto sa môže zlepšiť na O(m) s pomocnými dátovými štruktúrami, ako je pole najdlhších spoločných prefixov (LCP). Jednoduchosť a menšia pamäťová náročnosť suffixových polí ich robí preferovanými pre indexovanie textu v veľkom meradle a úlohy vyhľadávania.
Pre podrobné porovnanie a ďalšie čítanie sa pozrite na Združenie pre výpočtovú techniku a GeeksforGeeks.
Aplikácie suffixových polí v počítačovej vede
Suffixové polia sa stali základnou dátovou štruktúrou v počítačovej vede, najmä v oblastiach spracovania reťazcov, bioinformatiky a vyhľadávania informácií. Ich primárna úžitkovosť spočíva v umožnení efektívneho vyhľadávania vzorov a dotazovania podreťazcov. Napríklad, suffixové polia sú široko používané v full-textových vyhľadávačoch, kde umožňujú rýchlu identifikáciu všetkých výskytov dotazovaného podreťazca v rámci veľkého textového korpusu. To sa dosahuje využitím lexikograficky zoradeného poradia suffixov, ktoré podporuje binárne vyhľadávacie operácie pre vyhľadávanie vzorov v logaritmickej časovej komplexnosti Princeton University.
V bioinformatike, suffixové polia uľahčujú zarovnávanie a porovnávanie sekvencií DNA a proteínov. Nástroje na zostavovanie genómov a zarovnávanie sekvencií, ako tie, ktoré sa používajú v sekvenovaní novej generácie, často spoliehajú na suffixové polia na efektívne spracovanie obrovských biologických súborov údajov Národné centrum pre biotechnologické informácie. Okrem toho sú suffixové polia neoddeliteľnou súčasťou algoritmov na kompresiu dát, ako je Burrows-Wheelerova transformácia, ktorá je základom populárnych nástrojov na kompresiu, ako je bzip2. Tu suffixové pole umožňuje transformáciu vstupných údajov do formy, ktorá je lepšie prispôsobená na kompresiu zoskupením podobných znakov dohromady bzip2.
Okrem toho sa suffixové polia používajú aj v systémoch na detekciu plagiátorstva, deduplikáciu dát a konštrukciu efektívnych dátových štruktúr pre dotazy na najdlhší spoločný prefix (LCP). Ich univerzálnosť a efektívnosť ich robia nevyhnutnými v aplikáciách, kde je potrebné rýchle a škálovateľné spracovanie reťazcov.
Optimalizácia vyhľadávania a vyhľadávania vzorov pomocou suffixových polí
Suffixové polia sú mocné dátové štruktúry, ktoré výrazne optimalizujú operácie vyhľadávania a vyhľadávania vzorov v reťazcoch. Ukladáním počiatočných indexov všetkých suffixov textu v lexikografickom poradí umožňujú suffixové polia efektívne dotazy na podreťazce, čo je základné v aplikáciách ako full-textové vyhľadávanie, bioinformatika a dátová kompresia. Hlavnou výhodou použitia suffixového poľa oproti naivným vyhľadávacím metódam je zníženie časovej komplexnosti pre vyhľadávanie vzorov. Kým brutálny prístup môže vyžadovať O(nm) čas pre text dĺžky n a vzor dĺžky m, suffixové polia umožňujú vyhľadávanie vzorov v O(m + log n) čase využitím binárneho vyhľadávania na zoradených suffixoch.
Na ďalšie zlepšenie výkonu sa suffixové polia často používajú spolu s pomocnými dátovými štruktúrami, ako je pole najdlhších spoločných prefixov (LCP). Pole LCP uchováva dĺžky najdlhších spoločných prefixov medzi po sebe idúcimi suffixami v suffixovom poli, čo umožňuje ešte rýchlejšie vyhľadávanie vzorov a uľahčuje úlohy ako zistenie počtu rôznych podreťazcov alebo najdlhšieho opakujúceho sa podreťazca v lineárnom čase. Okrem toho moderné algoritmy na konštrukciu suffixových polí, ako je metóda indukovaného triedenia, dosahujú lineárnu časovú komplexnosť, čo ich robí praktickými pre veľké texty (Helsinská univerzita).
Suffixové polia sú tiež priestorovo efektívne v porovnaní so suffixovými stromami, pretože vyžadujú iba O(n) priestoru a sú jednoduchšie na implementáciu. Ich efektívnosť a univerzálnosť ich robia základným pilierom pri navrhovaní rýchlych a škálovateľných systémov indexovania textu a vyhľadávania vzorov (Princeton University).
Bežné algoritmy využívajúce suffixové polia
Suffixové polia sú základnou dátovou štruktúrou v spracovaní reťazcov, umožňujú efektívne riešenia rôznych zložitých problémov. Niekoľko bežných algoritmov využíva suffixové polia na dosiahnutie optimálneho alebo takmer optimálneho výkonu, najmä v oblastiach vyhľadávania vzorov, dátovej kompresie a bioinformatiky.
Jednou z najvýznamnejších aplikácií je vyhľadávanie podreťazcov. Kombinovaním suffixového poľa s binárnym vyhľadávaním je možné lokalizovať všetky výskyty vzoru v texte v O(m log n) čase, kde m je dĺžka vzoru a n je dĺžka textu. Tento prístup je omnoho rýchlejší ako naivné vyhľadávacie metódy, najmä pre veľké texty. Okrem toho je pole najdlhších spoločných prefixov (LCP) často konštruované spolu s suffixovým poľom na ďalšiu optimalizáciu opakujúcich sa dotazov a na uľahčenie algoritmov na nájdenie najdlhšieho opakujúceho sa podreťazca alebo najdlhšieho spoločného podreťazca medzi viacerými reťazcami.
Suffixové polia sú tiež neoddeliteľné pre algoritmy dátovej kompresie, ako je Burrows-Wheelerova transformácia (BWT), ktorá je kľúčovým prvkom nástroja na kompresiu bzip2. BWT sa spolieha na zoradené poradie suffixov na preusporiadanie vstupného textu, čo ho robí viac prispôsobeným na kódovanie behových dĺžok a ďalšie kompresné techniky (bzip2).
V bioinformatike sa suffixové polia používajú na efektívne zarovnávanie sekvencií a analýzu genómov, kde sú rýchle vyhľadávanie a porovnávanie sekvencií DNA nevyhnutné (Národné centrum pre biotechnologické informácie). Ich priestorová efektívnosť a rýchlosť ich robia preferovanými pred suffixovými stromami v mnohých aplikáciách vo veľkom meradle.
Výkonové úvahy a obmedzenia
Suffixové polia sú veľmi efektívne dátové štruktúry na riešenie rôznych problémov spracovania reťazcov, ako je vyhľadávanie podreťazcov, vyhľadávanie vzorov a výpočet najdlhšieho spoločného prefixu. Ich výkon a aplikabilita sú však ovplyvnené niekoľkými faktormi a inherentnými obmedzeniami.
Jedným z hlavných faktorov výkonu je čas konštrukcie. Hoci naivné algoritmy na zostavovanie suffixových polí pracujú v O(n log2 n) čase, pokročilejšie algoritmy dosahujú lineárnu časovú komplexnosť, ako napríklad algoritmus SA-IS. Napriek tomu môžu byť tieto optimálne algoritmy zložité na implementáciu a môžu mať značné konštantné faktory, čo môže ovplyvniť praktický výkon, najmä pre veľmi veľké texty alebo v prostrediach obmedzených na pamäť. Priestorová zložitost je ďalším dôležitým aspektom; suffixové pole zvyčajne vyžaduje O(n) pamäte, ale pomocné štruktúry, ako pole najdlhších spoločných prefixov (LCP) alebo ďalšie indexovacie štruktúry, môžu zvyšovať nároky na pamäť Helsinská univerzita.
Suffixové polia sú menej flexibilné ako suffixové stromy, pokiaľ ide o dynamické aktualizácie, ako sú vloženia alebo vymazania v texte. Zmena suffixového poľa po jeho zostavení nie je triviálna a často si vyžaduje opätovné zostavenie celej štruktúry, čo z neho robí menej vhodné pre aplikácie, kde sa základný text často mení Carnegie Mellon University. Okrem toho, aj keď sú suffixové polia priestorovo efektívnejšie ako suffixové stromy, môžu byť stále nepraktické pre extrémne veľké súbory údajov, ako sú celé genómové sekvencie, bez ďalšej kompresie alebo techník vonkajšej pamäte Národné centrum pre biotechnologické informácie.
Na záver, hoci suffixové polia ponúkajú významné výhody z hľadiska rýchlosti a efektívnosti pamäte pre statické texty, ich obmedzenia v dynamických scénaroch a aplikáciách vo veľkom meradle musia byť starostlivo zvážené počas návrhu systému.
Reálne použitia a príklady
Suffixové polia sú široko využívané v rôznych reálnych aplikáciách, ktoré si vyžadujú efektívne spracovanie reťazcov a vyhľadávanie vzorov. Jednou z najvýznamnejších aplikácií je v bioinformatike, najmä v sekvenovaní a analýze genómov. Nástroje, ako Burrows-Wheeler Aligner, využívajú suffixové polia na rýchle zarovnávanie krátkych DNA čítaní k referenčným genómom, čím umožňujú veľkoobjemové genómové štúdie a personalizovanú medicínu.
V oblasti vyhľadávania informácií sú suffixové polia základné pre implementáciu rýchlych full-textových vyhľadávačov. Napríklad projekt Apache Lucene využíva suffixové polia a príbuzné dátové štruktúry na poskytovanie efektívnych kapacít vyhľadávania podreťazcov, čo je nevyhnutné na indexovanie a dotazovanie veľkých textových korpusov.
Suffixové polia tiež zohrávajú kľúčovú úlohu v algoritmoch na kompresiu dát. Nástroj na kompresiu bzip2, napríklad, používa Burrows-Wheelerovu transformáciu, ktorá sa spolieha na konštrukciu suffixového poľa na preusporiadanie vstupných údajov a zlepšenie kompresibility.
Okrem toho sa suffixové polia používajú v systémoch na detekciu plagiátov, ako je Turnitin, na identifikáciu podobností medzi dokumentmi efektívnym porovnávaním podreťazcov. V oblasti spracovania prirodzeného jazyka sa používajú na úlohy, ako je identifikácia opakujúcich sa fráz, extrakcia kľúčových slov a budovanie koncordancií.
Tieto príklady zdôrazňujú univerzálnosť a efektívnosť suffixových polí pri zvládaní úloh spracovania reťazcov vo veľkom meradle v rôznych oblastiach, od výpočtovej biológie po vyhľadávače a kompresiu dát.
Ďalšie čítanie a pokročilé témy
Pre čitateľov, ktorí majú záujem o hlbšie preskúmanie suffixových polí, je k dispozícii niekoľko pokročilých tém a zdrojov. Jednou významnou oblasťou je štúdium zlepšených suffixových polí, ktoré obohacujú základnú štruktúru o ďalšie dáta, ako je pole najdlhších spoločných prefixov (LCP), čo umožňuje efektívnejšie vyhľadávanie vzorov a dotazy na podreťazce. Interakcia medzi suffixovými poliami a suffixovými stromami je tiež bohatým políčkom, pretože obidve štruktúry riešia podobné problémy, ale s rôznymi výhodami z hľadiska priestoru a času konštrukcie.
Recentný výskum sa zameriava na algoritmy konštrukcie v lineárnom čase pre suffixové polia, ako sú algoritmy SA-IS a DC3 (Skew), ktoré sú kľúčové pre spracovanie veľkých genómových alebo textových údajov. Tieto algoritmy sú podrobne diskutované v literatúre, vrátane základnej práce od Skupiny funkčných suffixových polí Helsinskej univerzity.
Aplikácie suffixových polí sa rozširujú nad rámec vyhľadávania reťazcov do oblastí, ako je kompresia dát (napr. Burrows-Wheelerova transformácia), bioinformatika (zostavovanie genómov a zarovnávanie) a vyhľadávanie informácií. Pre komplexný prehľad sa odporúča kniha Algoritmy na reťazce, stromy a sekvencie od Dana Gusfielda.
- Suffixové polia: Nová metóda pre online vyhľadávanie reťazcov (originálny článok od Manbera & Myersa)
- Konštrukcia suffixového poľa v lineárnom čase pomocou indukovaného triedenia (algoritmus SA-IS)
- Wikipedia: Suffix Array (prehľad a ďalšie odkazy)
Zdroje a odkazy
- Americká matematická spoločnosť
- Princeton University
- Katedra informatiky, Helsinská univerzita
- GeeksforGeeks
- Národné centrum pre biotechnologické informácie
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algoritmy na reťazce, stromy a sekvencie
- Wikipedia: Suffix Array