Освоение массивов суффиксов: Полное руководство по эффективной обработке строк и поиску шаблонов. Узнайте, как массивы суффиксов революционизируют текстовые алгоритмы.
- Введение в массивы суффиксов
- Как работают массивы суффиксов: Основные концепции
- Создание массива суффиксов: Шаг за шагом
- Массивы суффиксов и деревья суффиксов: Ключевые различия
- Применение массивов суффиксов в информатике
- Оптимизация поиска и сопоставления шаблонов с помощью массивов суффиксов
- Общие алгоритмы, использующие массивы суффиксов
- Учёт производительности и ограничения
- Примеры и реальные случаи использования
- Дополнительная литература и продвинутые темы
- Источники и ссылки
Введение в массивы суффиксов
Массив суффиксов — это мощная структура данных, используемая для обработки строк, в частности, для эффективного сопоставления шаблонов, запросов подстрок и индексирования текста. Он представляет собой отсортированный порядок всех суффиксов данной строки, обычно в виде массива начальных индексов. Эта структура позволяет использовать различные приложения в таких областях, как биоинформатика, сжатие данных и извлечение информации, где важны быстрый поиск и анализ больших текстов.
Концепция массива суффиксов была представлена как экономически эффективная альтернатива дереву суффиксов, предлагая аналогичные функциональные возможности, но с уменьшенными затратами памяти. В отличие от деревьев суффиксов, которые могут быть сложны для реализации и поддержки, массивы суффиксов проще и компактнее, что делает их пригодными для задач обработки больших текстов. Конструирование массива суффиксов включает сортировку всех возможных суффиксов строки, что можно достичь за O(n log n) времени, используя алгоритмы на основе сравнения, или даже за линейное время с помощью более современных техник, таких как метод индуктивной сортировки (Американское математическое общество).
Массивы суффиксов часто используются в сочетании с вспомогательными структурами данных, такими как массив наибольших общих префиксов (LCP), что еще больше увеличивает их утилиту для решения таких задач, как нахождение самой длинной повторяющейся подстроки или выполнение быстрых лексикографических сравнений. Их эффективность и универсальность сделали массивы суффиксов основным инструментом в современной алгоритмической строковой аналитике (Принстонский университет).
Как работают массивы суффиксов: Основные концепции
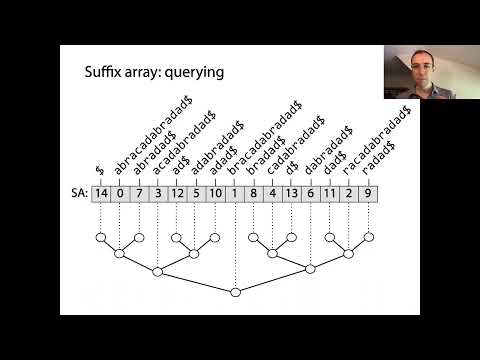
Массивы суффиксов — это мощные структуры данных, которые позволяют эффективно обрабатывать строки, в частности, для сопоставления шаблонов и индексирования текста. В своей основе массивы суффиксов представляют собой отсортированный порядок всех возможных суффиксов данной строки. Конструкция начинается с генерации каждого суффикса входной строки, каждый из которых начинается с другой позиции. Эти суффиксы затем сортируются лексикографически, а сам массив суффиксов представляет собой массив целых чисел, где каждая запись указывает на начальный индекс суффикса в этом отсортированном порядке.
Ключевое понятие, лежащее в основе массивов суффиксов, заключается в том, что, сортируя все суффиксы, можно выполнять быстрые бинарные поиски для локализации подстрок или шаблонов в оригинальном тексте. Это является значительным улучшением по сравнению с наивными методами поиска, которые могут требовать сканирования всего текста для каждого запроса. Массивы суффиксов часто сочетаются с массивом наибольших общих префиксов (LCP), который хранит длины наибольших общих префиксов между последовательными суффиксами в отсортированном массиве. Это сочетание еще больше ускоряет различные строковые операции, такие как нахождение повторяющихся подстрок или количества различных подстрок.
Эффективные алгоритмы конструкций, такие как метод индуктивной сортировки или использование удвоения префиксов, снизили временную сложность построения массивов суффиксов до линейного или почти линейного времени, что делает их практичными для крупных приложений. Массивы суффиксов широко используются в биоинформатике, сжатии данных и извлечении информации, где необходима быстрая и экономная по памяти обработка строк. Для всестороннего обзора основополагающих принципов и алгоритмов см. документацию Кафедры компьютерных наук, Университет Хельсинки.
Создание массива суффиксов: Шаг за шагом
Создание массива суффиксов включает в себя конструирование отсортированного массива всех суффиксов данной строки, представленных их начальными индексами. Процесс можно разбить на несколько ключевых шагов:
- 1. Сгенерируйте все суффиксы: Для строки длины n перечислите все суффиксы по их начальным позициям. Например, строка «banana» дает суффиксы, начинающиеся с индексов 0 («banana»), 1 («anana»), 2 («nana») и так далее.
- 2. Отсортируйте суффиксы: Отсортируйте эти суффиксы лексикографически. Это можно сделать наивно за O(n2 log n) времени, сравнивая строки непосредственно, но существуют более эффективные алгоритмы.
- 3. Храните индексы: Вместо хранения фактических строк суффиксов храните их начальные индексы в отсортированном порядке. Этот массив индексов и будет массивом суффиксов.
- 4. Оптимизация: Современные алгоритмы, такие как алгоритм Манбера-Майерса, используют технику удвоения для достижения временной сложности O(n log n). Еще более быстрый, алгоритм Карккайнена-Сандерса (также известный как алгоритм Skew) может построить массив суффиксов за линейное время O(n) для целочисленных алфавитов. Эти методы полагаются на сортировку по рангам и рекурсивные стратегии, чтобы избежать прямых сравнений строк Ассоциация вычислительных машин.
- 5. Итоговый результат: Полученный массив суффиксов позволяет эффективно сопоставлять шаблоны, выполнять запросы подстрок и является основополагающим для построения других структур данных, таких как массив LCP GeeksforGeeks.
Понимание каждого шага и доступных оптимизаций является важным для эффективного использования массивов суффиксов в приложениях обработки строк в большом масштабе.
Массивы суффиксов и деревья суффиксов: Ключевые различия
Массивы суффиксов и деревья суффиксов являются основными структурами данных для эффективной обработки строк, особенно в таких приложениях, как сопоставление шаблонов, биоинформатика и сжатие данных. Хотя они служат схожим целям, их структуры, требования к памяти и операционные характеристики значительно различаются.
Дерево суффиксов представляет собой сжатое дерево trie всех суффиксов данной строки, позволяющее выполнять чрезвычайно быстрые запросы подстрок, как правило, за линейное время относительно длины шаблона. Однако деревья суффиксов сложны для реализации и требуют значительных затрат памяти, часто в несколько раз превышающих размер исходной строки, из-за их узловой структуры и необходимости хранения указателей и меток рёбер. Это делает их менее практичными для очень больших наборов данных или в условиях ограниченной памяти.
В отличие от этого, массив суффиксов — это гораздо более простая и более экономически эффективная структура данных. Он состоит из массива целых чисел, представляющих начальные позиции всех отсортированных суффиксов строки. Массивы суффиксов могут быть построены за линейное время и требуют только O(n) памяти, где n — это длина строки. Хотя поиск подстрок с использованием массива суффиксов обычно медленнее, чем с деревом суффиков (O(m log n) для шаблона длиной m), это можно улучшить до O(m) с помощью вспомогательных структур данных, таких как массив наибольших общих префиксов (LCP). Простота и меньшая потребность в памяти делают массивы суффиксов предпочтительными для задач индексирования и поиска больших текстов.
Для детального сравнения и дальнейшего чтения см. Ассоциация вычислительных машин и GeeksforGeeks.
Применение массивов суффиксов в информатике
Массивы суффиксов стали основными структурами данных в информатике, особенно в области обработки строк, биоинформатики и извлечения информации. Их основная полезность заключается в обеспечении эффективного сопоставления шаблонов и запросов подстрок. Например, массивы суффиксов широко используются в поисковых системах полного текста, где они позволяют быстро идентифицировать все вхождения подстроки запроса в большом текстовом корпусе. Это достигается за счет использования лексикографически отсортированного порядка суффиксов, что поддерживает операции бинарного поиска для сопоставления шаблонов с логарифмической временной сложностью Принстонский университет.
В биоинформатике массивы суффиксов облегчают выравнивание и сравнение последовательностей ДНК и белков. Инструменты для сборки геномов и выравнивания последовательностей, такие как те, которые используются в секвенировании следующего поколения, часто полагаются на массивы суффиксов для эффективной обработки массивных биологических наборов данных Национальный центр биотехнологической информации. Кроме того, массивы суффиксов являются неотъемлемой частью алгоритмов сжатия данных, таких как преобразование Бурроуза-Уилера, которое лежит в основе популярных инструментов сжатия, таких как bzip2. Здесь массив суффиксов позволяет преобразовать входные данные в форму, которая лучше поддается сжатию, группируя схожие символы вместе bzip2.
Кроме того, массивы суффиксов также используются в системах обнаружения плагиата, дедупликации данных и для построения эффективных структур данных для запросов наибольшего общего префикса (LCP). Их универсальность и эффективность делают их незаменимыми в приложениях, где требуется быстрая и масштабируемая обработка строк.
Оптимизация поиска и сопоставления шаблонов с помощью массивов суффиксов
Массивы суффиксов — это мощные структуры данных, которые значительно оптимизируют операции поиска и сопоставления шаблонов в строках. Храня начальные индексы всех суффиксов текста в лексикографическом порядке, массивы суффиксов обеспечивают эффективные запросы подстрок, что является основополагающим в таких приложениях, как полнотекстовый поиск, биоинформатика и сжатие данных. Основное преимущество использования массива суффиксов по сравнению с наивными методами поиска заключается в снижении временной сложности для сопоставления шаблонов. В то время как грубый подход может потребовать O(nm) времени для текста длиной n и шаблона длиной m, массивы суффиксов позволяют выполнять поиск шаблонов за O(m + log n) времени, используя бинарный поиск по отсортированным суффиксам.
Для дальнейшего повышения производительности массивы суффиксов часто используются вместе с вспомогательными структурами данных, такими как массив наибольших общих префиксов (LCP). Массив LCP хранит длины наибольших общих префиксов между последовательными суффиксами в массиве суффиксов, что позволяет повысить скорость сопоставления шаблонов и облегчить задачи, такие как нахождение количества различных подстрок или самой длинной повторяющейся подстроки за линейное время. Кроме того, современные алгоритмы для построения массивов суффиксов, такие как метод индуктивной сортировки, достигают линейной временной сложности, что делает их практичными для крупных текстов (Университет Хельсинки).
Массивы суффиксов также пространственно эффективнее по сравнению с деревьями суффиксов, так как они требуют только O(n) памяти и проще в реализации. Их эффективность и универсальность делают их основой для проектирования быстрого и масштабируемого индексирования текста и систем сопоставления шаблонов (Принстонский университет).
Общие алгоритмы, использующие массивы суффиксов
Массивы суффиксов являются основополагающей структурой данных в обработке строк, позволяя эффективно решать различные сложные задачи. Несколько распространённых алгоритмов используют массивы суффиксов для достижения оптимальной или почти оптимальной производительности, особенно в областях сопоставления шаблонов, сжатия данных и биоинформатики.
Одним из наиболее известных приложений является поиск подстроки. Скомбинировав массив суффиксов с бинарным поиском, можно найти все вхождения шаблона в тексте за O(m log n) времени, где m — это длина шаблона, а n — длина текста. Этот подход значительно быстрее наивных методов поиска, особенно для больших текстов. Кроме того, массив наибольших общих префиксов (LCP) часто создается вместе с массивом суффиксов для дальнейшей оптимизации запросов на повторяющиеся шаблоны и для облегчения алгоритмов нахождения самой длинной повторяющейся подстроки или самой длинной общей подстроки между несколькими строками.
Массивы суффиксов также являются неотъемлемой частью алгоритмов сжатия данных, таких как преобразование Бурроуза-Уилера (BWT), которое является ключевым компонентом инструмента сжатия bzip2. BWT опирается на отсортированный порядок суффиксов для переработки входного текста, что делает его более удобным для кодирования длины пробелов и других методов сжатия (bzip2).
В биоинформатике массивы суффиксов используются для эффективного выравнивания последовательностей и анализа геномов, где быстрая проверка и сравнение последовательностей ДНК имеют важное значение (Национальный центр биотехнологической информации). Их пространственная эффективность и скорость делают их предпочтительными по сравнению с деревьями суффиксов во многих крупных приложениях.
Учёт производительности и ограничения
Массивы суффиксов являются высокоэффективными структурами данных для решения различных задач обработки строк, таких как поиск подстрок, сопоставление шаблонов и вычисление наибольшего общего префикса. Однако их производительность и применимость зависят от нескольких факторов и неотъемлемых ограничений.
Одним из основных факторов производительности является время построения. В то время как наивные алгоритмы для построения массивов суффиксов работают за O(n log2 n) времени, более продвинутые алгоритмы достигают линейной временной сложности, такие как алгоритм SA-IS. Тем не менее, эти оптимальные алгоритмы могут быть сложны для реализации и могут иметь значительные постоянные факторы, что может повлиять на практическую производительность, особенно для очень больших текстов или в условиях ограниченной памяти. Временная сложность — еще один важный аспект; массив суффиксов обычно требует O(n) пространства, но вспомогательные структуры, такие как массив наибольших общих префиксов (LCP) или дополнительные индексы, могут еще больше увеличить использование памяти Университет Хельсинки.
Массивы суффиксов меньше гибки, чем деревья суффиксов, когда речь идет о динамических обновлениях, таких как вставка или удаление в тексте. Изменение массива суффиксов после его создания является нетривиальным и часто требует полной перестройки всей структуры, что делает их менее подходящими для приложений, в которых изменяемый текст меняется часто Университет Карнеги-Меллона. Кроме того, хотя массивы суффиксов более экономичны по памяти, чем деревья суффиксов, они могут оказаться непрактичными для чрезвычайно больших наборов данных, таких как целые геномные последовательности, без дальнейшего сжатия или внешних методов памяти Национальный центр биотехнологической информации.
В заключение, хотя массивы суффиксов предлагают значительные преимущества в отношении скорости и экономии памяти для статических текстов, их ограничения в динамических сценариях и крупных приложениях должны быть тщательно учтены при проектировании систем.
Примеры и реальные случаи использования
Массивы суффиксов широко используются в различных реальных приложениях, которые требуют эффективной обработки строк и сопоставления шаблонов. Одним из наиболее заметных случаев является биоинформатика, особенно в секвенировании и анализе геномов. Инструменты, такие как Burrows-Wheeler Aligner, используют массивы суффиксов для быстрого выравнивания коротких ДНК-ридов к референсным геномам, что позволяет проводить крупномасштабные геномные исследования и персонализированную медицину.
В извлечении информации массивы суффиксов являются основой для реализации быстрых полнотекстовых поисковых систем. Например, проект Apache Lucene использует массивы суффиксов и связанные структуры данных для обеспечения эффективных возможностей поиска подстрок, что имеет решающее значение для индексирования и запросов к большим текстовым корпусам.
Массивы суффиксов также играют важную роль в алгоритмах сжатия данных. Инструмент сжатия bzip2, например, использует преобразование Бурроуза-Уилера, которое полагается на построение массива суффиксов для реорганизации входных данных и улучшения сжимаемости.
Кроме того, массивы суффиксов используются в системах обнаружения плагиата, таких как Turnitin, для выявления сходств между документами путем эффективного сравнения подстрок. В обработке естественного языка они используются для выполнения задач, таких как идентификация повторяющихся фраз, извлечение ключевых слов и создание конкордансов.
Эти примеры подчеркивают универсальность и эффективность массивов суффиксов в выполнении задач по обработке строк в большом масштабе в различных областях, от вычислительной биологии до поисковых систем и сжатия данных.
Дополнительная литература и продвинутые темы
Для читателей, заинтересованных в более глубоком изучении массивов суффиксов, есть несколько продвинутых тем и ресурсов. Одной значительной областью является исследование расширенных массивов суффиксов, которые обогащают базовую структуру дополнительными данными, такими как массив наибольших общих префиксов (LCP), что позволяет более эффективно производить сопоставление шаблонов и запросы подстрок. Взаимодействие между массивами суффиксов и деревьями суффиксов также является богатой областью, так как обе структуры решают схожие задачи, но с различными компромиссами в отношении пространства и времени построения.
Недавние исследования сосредоточены на алгоритмах линейной конструкции для массивов суффиксов, таких как SA-IS и DC3 (Skew), которые имеют ключевое значение для обработки крупных геномных или текстовых данных. Эти алгоритмы подробно обсуждаются в литературе, в том числе в основополагающей работе Функциональной группы по массивам суффиксов Университета Хельсинки.
Приложения массивов суффиксов выходят за пределы сопоставления строк в области, такие как сжатие данных (например, преобразование Бурроуза-Уилера), биоинформатика (сборка и выравнивание геномов) и извлечение информации. Для всестороннего обзора книга Algorithms on Strings, Trees, and Sequences Дэна Гасфилда настоятельно рекомендуется.
- Массивы суффиксов: Новый метод для онлайн-поиска строк (оригинальная работа Манбера и Майерса)
- Линейное время построения массива суффиксов с использованием индуктивной сортировки (алгоритм SA-IS)
- Wikipedia: Массив суффиксов (обзор и дальнейшие ссылки)
Источники и ссылки
- Американское математическое общество
- Принстонский университет
- Кафедра компьютерных наук Университета Хельсинки
- GeeksforGeeks
- Национальный центр биотехнологической информации
- Университет Карнеги-Меллона
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Массив суффиксов