Stăpânirea Tabelor de Sufixe: Ghidul Definitiv pentru Procesarea Eficientă a Stringurilor și Potrivirea de Tipare. Descoperiți Cum Tabelele de Sufixe Revoluționează Algoritmii Textuali.
- Introducere în Tabelele de Sufixe
- Cum Funcționează Tabelele de Sufixe: Concepe de Bază
- Construirea unei Tabele de Sufix: Pas cu Pas
- Tabele de Sufixe vs. Arbori de Sufix: Diferențe Cheie
- Aplicațiile Tabelor de Sufixe în Știința Computerelor
- Optimizarea Căutării și a Potrivirii de Tipare cu Tabele de Sufixe
- Algoritmi Comuni Ce Utilizează Tabele de Sufixe
- Considerații de Performanță și Limitări
- Cazuri și Exemple din Lumea Reală
- Cărți de Citit și Subiecte Avansate
- Sursă & Referințe
Introducere în Tabelele de Sufixes
O tabelă de sufixe este o structură de date puternică utilizată în procesarea stringurilor, în special pentru potrivirea eficientă a tiparelor, interogările subșirurilor și indexarea textelor. Aceasta reprezintă ordineaua sortată a tuturor sufixelor unui string dat, de obicei ca un array de indici de început. Această structură permite o varietate de aplicații în domenii precum bioinformatică, compresia datelor și recuperarea informațiilor, unde căutarea rapidă și analiza textelor mari sunt esențiale.
Conceptul de tabelă de sufixe a fost introdus ca o alternativă eficientă din punct de vedere al spațiului la arborele de sufix, oferind funcționalități similare, dar cu un overhead de memorie redus. Spre deosebire de arborii de sufixe, care pot fi complexi de implementat și de întreținut, tabelele de sufixe sunt mai simple și mai compacte, făcându-le potrivite pentru sarcini de procesare textuale pe scară largă. Construirea unei tabele de sufixe implică sortarea tuturor posibilelor sufixe ale unui string, ceea ce poate fi realizat în O(n log n) timp folosind algoritmi bazati pe comparație, sau chiar în timp liniar cu tehnici mai avansate cum ar fi metoda de sortare indusă (Societatea Americană de Matematică).
Tabelele de sufixe sunt adesea folosite în combinație cu structuri de date auxiliare precum array-ul de Prefix Comun Maxim (LCP), care îmbunătățește și mai mult utilitatea lor pentru rezolvarea problemelor cum ar fi găsirea celui mai lung subșir repetat sau realizarea unor comparații lexicografice rapide. Eficiența și versatilitatea lor au făcut din tabelele de sufixe un instrument fundamental în analiza modernă a stringurilor algoritmice (Universitatea Princeton).
Cum Funcționează Tabelele de Sufixes: Concepe de Bază
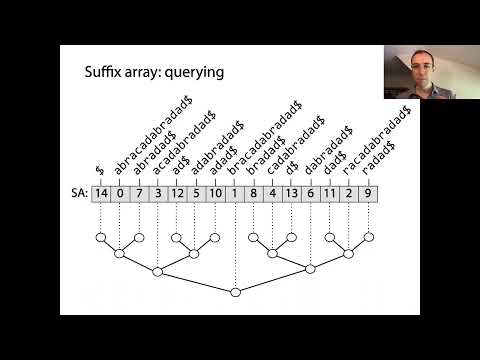
Tabelele de sufixe sunt structuri de date puternice care permit procesarea eficientă a stringurilor, în special pentru potrivirea tiparelor și indexarea textelor. La baza lor, tabelele de sufixe reprezintă ordinea sortată a tuturor sufixelor posibile ale unui string dat. Construirea începe prin generarea fiecărui sufix al stringului de intrare, fiecare începând de la o poziție diferită. Aceste sufixe sunt apoi sortate lexicografic, iar tabela de sufixe în sine este un array de numere întregi, unde fiecare intrare indică indexul de început al unui sufix în această ordine sortată.
Concepția cheie din spatele tabelelor de sufixe este că, prin sortarea tuturor sufixelor, se pot efectua căutări binare rapide pentru a localiza subșirurile sau tiparele în textul original. Aceasta este o îmbunătățire semnificativă față de metodele naive de căutare, care pot necesita scanning-ul întregului text pentru fiecare interogare. Tabelele de sufixe sunt adesea asociate cu array-ul de Prefix Comun Maxim (LCP), care stochează lungimile prefixelor comune cele mai lungi între sufixele consecutive din tabela sortată. Această asociere accelerează și mai mult diversele operații cu stringuri, cum ar fi găsirea subșirurilor repetate sau a numărului de subșiruri distincte.
Algoritmi de construcție eficienți, cum ar fi metoda de sortare indusă sau utilizarea dublării prefixului, au redus complexitatea temporală a construirii tabelelor de sufixe la timp liniar sau aproape liniar, făcându-le practice pentru aplicații la scară largă. Tabelele de sufixe sunt folosite pe scară largă în bioinformatică, compresia datelor și recuperarea informațiilor, unde procesarea rapidă și eficientă din punct de vedere al memoriei a stringurilor este esențială. Pentru o prezentare generală cuprinzătoare a principiilor și algoritmilor subiacenți, consultați documentația de la Departamentul de Informatică, Universitatea din Helsinki.
Construirea unei Tabele de Sufix: Pas cu Pas
Construirea unei tabele de sufixe implică construirea unui array sortat al tuturor sufixelor unui string dat, reprezentat prin indecșii săi de început. Procesul poate fi desfășurat în câțiva pași cheie:
- 1. Generați Toate Sufixele: Pentru un string de lungime n, enumerați toate sufixele după pozițiile lor de început. De exemplu, stringul „banana” produce sufixe ce încep la indicele 0 („banana”), 1 („anana”), 2 („nana”), și așa mai departe.
- 2. Setați Sufixele: Sortează aceste sufixe lexicografic. Aceasta poate fi realizată în mod naive în O(n2 log n) timp prin compararea directă a stringurilor, dar există algoritmi mai eficienți.
- 3. Stocați Indecșii: În loc să stocați efectiv stringurile sufix, stocați indecșii lor de început în ordinea sortată. Acest array de indecși este tabela de sufixe.
- 4. Optimizare: Algoritmi avansați, precum algoritmul Manber-Myers, folosesc o tehnică de dublare pentru a obține complexitate temporală O(n log n). Chiar mai rapid, algoritmul Karkkainen-Sanders (cunoscut și sub numele de algoritmul Skew) poate construi tabela de sufixe în timp liniar O(n) pentru alfabete întregi. Aceste metode se bazează pe sortarea după ranguri și strategii recursive pentru a evita comparațiile directe ale stringurilor Asociația pentru Calcul.
- 5. Rezultatul Final: Tabela de sufixe rezultantă permite potrivirea eficientă a tiparelor, interogarea subșirurilor și este fundamentală pentru construirea altor structuri de date, cum ar fi tabela LCP GeeksforGeeks.
Înțelegerea fiecărui pas și a optimizărilor disponibile este crucială pentru a profita de tabelele de sufixe în aplicațiile de procesare a stringurilor la scară largă.
Tabele de Sufixe vs. Arbori de Sufix: Diferențe Cheie
Tabelele de sufixe și arborii de sufixe sunt ambele structuri de date fundamentale pentru procesarea eficientă a stringurilor, în special în aplicații precum potrivirea tiparelor, bioinformatica și compresia datelor. Deși servesc scopuri similare, structurile lor, cerințele de memorie și caracteristicile operaționale diferă semnificativ.
Un arbore de sufix este un trie comprimat al tuturor sufixelor unui string dat, permițând interogări extrem de rapide ale subșirurilor, de obicei în timp liniar în raport cu lungimea tiparului. Cu toate acestea, arborii de sufixe sunt complexi de implementat și necesită un overhead de memorie substanțial—de multe ori de câteva ori dimensiunea stringului original—din cauza structurii lor bazate pe noduri și necesitatea de a stoca pointeri și etichete de margini. Acest lucru îi face mai puțin practici pentru seturi de date foarte mari sau medii cu resurse de memorie limitate.
În contrast, o tabelă de sufixe este o structură de date mult mai simplă și mai eficientă din punct de vedere al spațiului. Aceasta constă dintr-un array de numere întregi reprezentând pozițiile de început ale tuturor sufixelor sortate ale stringului. Tabelele de sufixe pot fi construite în timp liniar și necesită doar O(n) spațiu, unde n este lungimea stringului. Deși căutările de subșiruri folosind o tabelă de sufixe sunt de obicei mai lente decât cu un arbore de sufix (O(m log n) pentru un tipar de lungime m), acest lucru poate fi îmbunătățit la O(m) cu structuri de date auxiliare precum tabela de Prefix Comun Maxim (LCP). Simplitatea și cerințele de memorie mai mici ale tabelelor de sufixe le fac preferabile pentru sarcini de indexare și căutare textuale pe scară largă.
Pentru o comparație detaliată și lecturi suplimentare, consultați Asociația pentru Calcul și GeeksforGeeks.
Aplicațiile Tabelor de Sufixe în Știința Computerelor
Tabelele de sufixe au devenit o structură de date fundamentală în știința computerelor, în special în domeniile procesării stringurilor, bioinformaticii și recuperării informațiilor. Principala lor utilitate constă în facilitarea potrivirii eficiente a tiparelor și a interogărilor subșirurilor. De exemplu, tabelele de sufixe sunt utilizate pe scară largă în motoarele de căutare full-text, unde permit identificarea rapidă a tuturor aparițiilor unui subșir de interogare într-un corp text mare. Acest lucru se realizează prin valorificarea ordinii lexicografice sortate a sufixelor, care susține operațiunile de căutare binară pentru potrivirea tiparelor în complexitate temporală logarithmică Universitatea Princeton.
În bioinformatică, tabelele de sufixe facilitează alinierea și compararea secvențelor de ADN și proteine. Instrumente pentru asamblarea genomului și alinierea secvenței, cum ar fi cele utilizate în secvențierea de generație următoare, se bazează adesea pe tabele de sufixe pentru a gestiona eficient seturi mari de date biologice Centrul Național pentru Informații Biotehnologice. În plus, tabelele de sufixe sunt integrate în algoritmi de compresie a datelor precum Transformarea Burrows-Wheeler, care stă la baza unor instrumente populare de compresie precum bzip2. Aici, tabela de sufixe permite transformarea datelor de intrare într-o formă mai propice compresiei prin gruparea caracterelor similare împreună bzip2.
Dincolo de acestea, tabelele de sufixe sunt folosite și în detectarea plagiatului, deduplicarea datelor și construirea de structuri de date eficiente pentru interogările de prefix comun maxim (LCP). Versatilitatea și eficiența lor le fac indispensabile în aplicații unde se cer procesări rapide și scalabile ale stringurilor.
Optimizarea Căutării și a Potrivirii de Tipare cu Tabele de Sufixe
Tabelele de sufixe sunt structuri de date puternice care optimizează semnificativ operațiile de căutare și potrivire a tiparelor în stringuri. Prin stocarea indecșilor de început ai tuturor sufixelor unui text în ordinea lexicografică, tabelele de sufixe permit interogări eficiente pentru subșiruri, care sunt fundamentale în aplicații precum căutarea full-text, bioinformatica și compresia datelor. Principalul avantaj al utilizării unei tabele de sufixe față de metodele naive de căutare este reducerea complexității temporale pentru potrivirea tiparelor. În timp ce o abordare de forță brută poate necesita O(nm) timp pentru un text de lungime n și un tipar de lungime m, tabelele de sufixe permit căutări de tipar în O(m + log n) timp prin valorificarea căutării binare pe sufixele sortate.
Pentru a îmbunătăți și mai mult performanța, tabelele de sufixe sunt adesea utilizate împreună cu structuri de date auxiliare precum array-ul de Prefix Comun Maxim (LCP). Tabela LCP stochează lungimile celor mai lungi prefixe comune între sufixele consecutive din tabela de sufixe, permițând potriviri de tipare și mai rapide și facilitând sarcini precum găsirea numărului de subșiruri distincte sau celui mai lung subșir repetat în timp liniar. În plus, algoritmii moderni pentru construirea tabelelor de sufixe, cum ar fi metoda de sortare indusă, realizează o complexitate temporală liniară, făcându-le practice pentru texte de mari dimensiuni (Universitatea din Helsinki).
Tabelele de sufixe sunt, de asemenea, eficiente din punct de vedere al spațiului comparativ cu arborii de sufixe, deoarece necesită doar O(n) spațiu și sunt mai ușor de implementat. Eficiența și versatilitatea lor fac din ele o piatră de temelie în proiectarea sistemelor de indexare a textului rapide și scalabile și a potrivirii tiparelor (Universitatea Princeton).
Algoritmi Comuni Ce Utilizează Tabele de Sufixe
Tabelele de sufixe sunt o structură de date fundamentală în procesarea stringurilor, permițând soluții eficiente la o varietate de probleme complexe. Mai mulți algoritmi comuni valorifică tabelele de sufixe pentru a obține performanțe optime sau aproape optime, în special în domeniile potrivirii tiparelor, compresiei datelor și bioinformaticii.
Una dintre cele mai proeminente aplicații este în căutarea subșirurilor. Prin combinarea unei tabele de sufixe cu o căutare binară, este posibil să localizăm toate aparițiile unui tipar într-un text în O(m log n) timp, unde m este lungimea tiparului iar n este lungimea textului. Această abordare este semnificativ mai rapidă decât metodele naive de căutare, mai ales pentru texte mari. În plus, array-ul de Prefix Comun Maxim (LCP) este adesea construit împreună cu tabela de sufixe pentru a optimiza în continuare interogările de tipare repeatate și pentru a facilita algoritmi pentru găsirea celui mai lung subșir repetat sau a celui mai lung subșir comun între mai multe stringuri.
Tabelele de sufixe sunt, de asemenea, esențiale pentru algoritmi de compresie a datelor, cum ar fi Transformarea Burrows-Wheeler (BWT), care este un component cheie al instrumentului de compresie bzip2. BWT se bazează pe ordinea sortată a sufixelor pentru a reorganiza textul de intrare, făcându-l mai propice pentru codarea lungimilor de repetare și alte tehnici de compresie (bzip2).
În bioinformatică, tabelele de sufixe sunt utilizate pentru alinierea eficientă a secvențelor și analiza genomului, unde căutarea rapidă și compararea secvențelor de ADN sunt esențiale (Centrul Național pentru Informații Biotehnologice). Eficiența lor în spațiu și viteza le fac preferabile arborilor de sufixe în multe aplicații pe scară largă.
Considerații de Performanță și Limitări
Tabelele de sufixe sunt structuri de date extrem de eficiente pentru rezolvarea unei varietăți de probleme de procesare a stringurilor, cum ar fi căutarea subșirurilor, potrivirea tiparelor și calculul prefixului comun maxim. Cu toate acestea, performanța și aplicabilitatea lor sunt influențate de mai multe considerații și limitări inerente.
Unul din principalii factori de performanță este timpul de construcție. Deși algoritmii naivi pentru construirea tabelelor de sufixe operează în O(n log2 n) timp, algoritmi mai avansați ating complexitate liniară, cum ar fi algoritmul SA-IS. Cu toate acestea, acești algoritmi optimi pot fi complecși de implementat și pot avea factori constanți semnificativi, ceea ce poate afecta performanța practică, în special pentru texte foarte mari sau în medii cu resurse de memorie limitate. Complexitatea spațială este un alt aspect important; o tabelă de sufixe necesită de obicei O(n) spațiu, dar structuri auxiliare precum tabela de Prefix Comun Maxim (LCP) sau structuri de indexare suplimentare pot crește și mai mult utilizarea memoriei Universitatea din Helsinki.
Tabelele de sufixe sunt mai puțin flexibile decât arborii de sufixe când vine vorba de actualizări dinamice, cum ar fi inserțiile sau ștergerile în text. Modificarea unei tabele de sufixe după construcția sa nu este trivială și adesea necesită reconstruirea întregii structuri, făcându-le mai puțin potrivite pentru aplicații unde textul de bază se schimbă frecvent Universitatea Carnegie Mellon. În plus, deși tabelele de sufixe sunt mai eficiente din punct de vedere al spațiului decât arborii de sufixe, acestea pot fi totuși impractice pentru seturi de date extrem de mari, cum ar fi întregi secvențe genomice, fără tehnici suplimentare de compresie sau memorie externă Centrul Național pentru Informații Biotehnologice.
În concluzie, în timp ce tabelele de sufixe oferă avantaje semnificative în ceea ce privește viteza și eficiența spațială pentru texte statice, limitările lor în scenarii dinamice și aplicații pe scară largă trebuie să fie atent considerate în timpul proiectării sistemului.
Cazuri și Exemple din Lumea Reală
Tabelele de sufixe sunt utilizate pe scară largă în diverse aplicații din lumea reală care necesită procesarea eficientă a stringurilor și potrivirea tiparelor. Unul dintre cele mai proeminente cazuri de utilizare este în bioinformatică, în special în secvențierea și analiza genomului. Instrumentele precum Aligner-ul Burrows-Wheeler utilizează tabele de sufixe pentru a alinia rapid citiri scurte de ADN la genomuri de referință, facilitând studii genomice de mari dimensiuni și medicina personalizată.
În recuperarea informațiilor, tabelele de sufix sunt fundamentale pentru implementarea motoarelor de căutare full-text rapide. De exemplu, proiectul Apache Lucene valorifică tabele de sufix și structuri de date conexe pentru a oferi capabilități eficiente de căutare a subșirurilor, care sunt esențiale pentru indexarea și interogarea unor corpuri text mari.
Tabelele de sufixe joacă de asemenea un rol crucial în algoritmii de compresie a datelor. Instrumentul de compresie bzip2, de exemplu, folosește Transformarea Burrows-Wheeler, care se bazează pe construcția unei tabele de sufixe pentru a reordona datele de intrare și a îmbunătăți compresibilitatea.
În plus, tabelele de sufixe sunt utilizate în sistemele de detectare a plagiatului, cum ar fi Turnitin, pentru a identifica similitudinile între documente prin compararea eficientă a subșirurilor. În procesarea limbajului natural, acestea sunt utilizate pentru sarcini precum identificarea frazelor repetate, extragerea cuvintelor cheie și construirea concordanțelor.
Aceste exemple evidențiază versatilitatea și eficiența tabelelor de sufixe în gestionarea sarcinilor de procesare a stringurilor la scară largă în domenii diverse, de la biologia computațională la motoarele de căutare și compresia datelor.
Cărți de Citit și Subiecte Avansate
Pentru cititorii interesați să aprofundeze subiectul tabelelor de sufixe, există mai multe subiecte avansate și resurse disponibile. Un domeniu semnificativ este studiul tabelelor de sufixe îmbunătățite, care completează structura de bază cu date suplimentare precum array-ul de Prefix Comun Maxim (LCP), permițând potriviri mai eficiente ale tiparelor și interogări subșir. Interacțiunea dintre tabelele de sufixe și arborii de sufixe este de asemenea un câmp bogat, deoarece ambele structuri rezolvă probleme similare, dar cu trade-offs diferite în ceea ce privește spațiul și timpul de construcție.
Cercetările recente s-au concentrat pe algoritmi de construcție în timp liniar pentru tabelele de sufixe, precum algoritmii SA-IS și DC3 (Skew), care sunt cruciali pentru gestionarea datelor genomice sau textuale la scară largă. Acești algoritmi sunt discutați în detaliu în literatura de specialitate, inclusiv în lucrările fundamentale ale Grupului Funcțional de Tabele de Sufixe, Universitatea din Helsinki.
Aplicațiile tabelelor de sufixe se extind dincolo de potrivirea stringurilor în domenii precum compresia datelor (de exemplu, Transformarea Burrows-Wheeler), bioinformatica (asamblarea și alinierea genomului) și recuperarea informațiilor. Pentru o prezentare generală cuprinzătoare, cartea Algoritmi pe Stringuri, Arbori și Secvențe de Dan Gusfield este foarte recomandată.
- Tabelele de Sufixe: O Nouă Metodă Pentru Căutările Online de Stringuri (lucrare originală de Manber & Myers)
- Construcția Tabelei de Sufixe în Timp Liniar Folosind Sortarea Indusă (algoritmul SA-IS)
- Wikipedia: Tablă de Sufixe (prezentare generală și linkuri suplimentare)
Sursă & Referințe
- Societatea Americană de Matematică
- Universitatea Princeton
- Departamentul de Informatică, Universitatea din Helsinki
- GeeksforGeeks
- Centrul Național pentru Informații Biotehnologice
- Universitatea Carnegie Mellon
- Apache Lucene
- Turnitin
- Algoritmi pe Stringuri, Arbori și Secvențe
- Wikipedia: Tablă de Sufixe