Dominando Arrays de Sufixos: O Guia Definitivo para Processamento Eficiente de Strings e Correspondência de Padrões. Descubra como os Arrays de Sufixos Revolucionam os Algoritmos de Texto.
- Introdução aos Arrays de Sufixos
- Como os Arrays de Sufixos Funcionam: Conceitos Centrais
- Construindo um Array de Sufixos: Passo a Passo
- Arrays de Sufixos vs. Árvores de Sufixos: Principais Diferenças
- Aplicações dos Arrays de Sufixos na Ciência da Computação
- Otimizando Busca e Correspondência de Padrões com Arrays de Sufixos
- Algoritmos Comuns que Utilizam Arrays de Sufixos
- Considerações de Desempenho e Limitações
- Casos de Uso e Exemplos do Mundo Real
- Leitura Adicional e Tópicos Avançados
- Fontes & Referências
Introdução aos Arrays de Sufixos
Um array de sufixos é uma estrutura de dados poderosa usada no processamento de strings, particularmente para correspondência eficiente de padrões, consultas de substrings e indexação de textos. Ele representa a ordem classificada de todos os sufixos de uma string dada, tipicamente como um array de índices iniciais. Essa estrutura permite uma variedade de aplicações em campos como bioinformática, compressão de dados e recuperação de informações, onde a busca rápida e a análise de grandes textos são essenciais.
O conceito de array de sufixos foi introduzido como uma alternativa eficiente em espaço à árvore de sufixos, oferecendo funcionalidades semelhantes, mas com menor sobrecarga de memória. Ao contrário das árvores de sufixos, que podem ser complexas de implementar e manter, os arrays de sufixos são mais simples e compactos, tornando-os adequados para tarefas de processamento de texto em larga escala. A construção de um array de sufixos envolve a ordenação de todos os sufixos possíveis de uma string, o que pode ser alcançado em O(n log n) de tempo usando algoritmos baseados em comparação, ou até mesmo em tempo linear com técnicas mais avançadas, como o método de ordenação induzida (Sociedade Matemática Americana).
Arrays de sufixos são frequentemente usados em conjunto com estruturas de dados auxiliares, como o array do maior prefixo comum (LCP), que aumenta ainda mais sua utilidade para resolver problemas, como encontrar a substring repetida mais longa ou realizar comparações lexicográficas rápidas. Sua eficiência e versatilidade tornaram os arrays de sufixos uma ferramenta fundamental na análise de strings algorítmica moderna (Universidade de Princeton).
Como os Arrays de Sufixos Funcionam: Conceitos Centrais
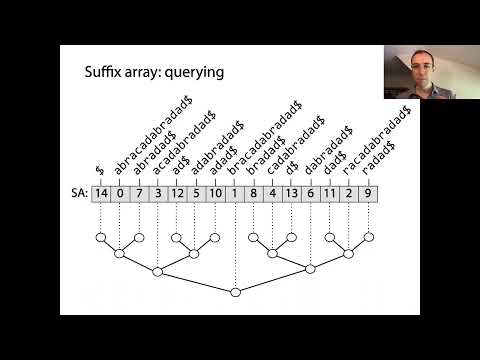
Os arrays de sufixos são estruturas de dados poderosas que permitem o processamento eficiente de strings, particularmente para correspondência de padrões e indexação de textos. Em sua essência, os arrays de sufixos representam a ordem classificada de todos os sufixos possíveis de uma string dada. A construção começa gerando cada sufixo da string de entrada, cada um começando em uma posição diferente. Esses sufixos são então ordenados lexicograficamente, e o próprio array de sufixos é um array de inteiros, onde cada entrada indica o índice inicial de um sufixo nesta ordem classificada.
O conceito-chave por trás dos arrays de sufixos é que, ao ordenar todos os sufixos, é possível realizar pesquisas binárias rápidas para localizar substrings ou padrões dentro do texto original. Esta é uma melhoria significativa em relação aos métodos de busca ingênuos, que podem exigir a varredura de todo o texto para cada consulta. Os arrays de sufixos são frequentemente combinados com o array do maior prefixo comum (LCP), que armazena os comprimentos dos maiores prefixos comuns entre sufixos consecutivos no array classificado. Essa combinação acelera ainda mais várias operações de string, como encontrar substrings repetidas ou o número de substrings distintas.
Algoritmos de construção eficientes, como o método de ordenação induzida ou o uso de duplicação de prefixos, reduziram a complexidade de tempo de construção dos arrays de sufixos para tempo linear ou quase linear, tornando-os práticos para aplicações em larga escala. Os arrays de sufixos são amplamente utilizados em bioinformática, compressão de dados e recuperação de informações, onde o processamento de strings rápido e eficiente em memória é essencial. Para uma visão abrangente dos princípios e algoritmos subjacentes, consulte a documentação do Departamento de Ciência da Computação, Universidade de Helsinque.
Construindo um Array de Sufixos: Passo a Passo
Construir um array de sufixos envolve a construção de um array classificado de todos os sufixos de uma string dada, representada por seus índices iniciais. O processo pode ser dividido em várias etapas principais:
- 1. Gerar Todos os Sufixos: Para uma string de comprimento n, enumere todos os sufixos por suas posições de início. Por exemplo, a string “banana” gera sufixos começando nos índices 0 (“banana”), 1 (“anana”), 2 (“nana”), e assim por diante.
- 2. Ordenar os Sufixos: Ordene esses sufixos lexicograficamente. Isso pode ser feito ingênuamente em O(n2 log n) de tempo comparando strings diretamente, mas existem algoritmos mais eficientes.
- 3. Armazenar os Índices: Em vez de armazenar as strings de sufixo reais, armazene seus índices iniciais na ordem classificada. Este array de índices é o array de sufixos.
- 4. Otimização: Algoritmos avançados, como o algoritmo Manber-Myers, usam uma técnica de duplicação para alcançar uma complexidade de tempo de O(n log n). Ainda mais rápido, o algoritmo Karkkainen-Sanders (também conhecido como algoritmo Skew) pode construir o array de sufixos em tempo linear O(n) para alfabetos inteiros. Esses métodos se baseiam na ordenação por classificações e estratégias recursivas para evitar comparações diretas de strings Associação para a Computação.
- 5. Saída Final: O array de sufixos resultante permite correspondência de padrões eficiente, consultas de substrings e é fundamental para a construção de outras estruturas de dados, como o array LCP GeeksforGeeks.
Compreender cada etapa e as otimizações disponíveis é crucial para aproveitar os arrays de sufixos em aplicações de processamento de strings em grande escala.
Arrays de Sufixos vs. Árvores de Sufixos: Principais Diferenças
Arrays de sufixos e árvores de sufixos são ambas estruturas de dados fundamentais para o processamento eficiente de strings, particularmente em aplicações como correspondência de padrões, bioinformática e compressão de dados. Embora sirvam a propósitos semelhantes, suas estruturas, requisitos de memória e características operacionais diferem significativamente.
Uma árvore de sufixos é um trie comprimido de todos os sufixos de uma string dada, permitindo consultas de substrings extremamente rápidas, tipicamente em tempo linear em relação ao comprimento do padrão. No entanto, as árvores de sufixos são complexas de implementar e exigem uma sobrecarga de memória substancial – muitas vezes várias vezes o tamanho da string original – devido à sua estrutura baseada em nós e à necessidade de armazenar ponteiros e rótulos de borda. Isso as torna menos práticas para conjuntos de dados muito grandes ou ambientes com restrições de memória.
Em contrapartida, um array de sufixos é uma estrutura de dados muito mais simples e eficiente em espaço. Ele consiste em um array de inteiros representando as posições de início de todos os sufixos classificados da string. Os arrays de sufixos podem ser construídos em tempo linear e requerem apenas O(n) de espaço, onde n é o comprimento da string. Embora as buscas de substrings usando um array de sufixos sejam tipicamente mais lentas do que com uma árvore de sufixos (O(m log n) para um padrão de comprimento m), isso pode ser melhorado para O(m) com estruturas de dados auxiliares, como o array do maior prefixo comum (LCP). A simplicidade e menor consumo de memória dos arrays de sufixos os tornam preferíveis para tarefas de indexação e busca de texto em larga escala.
Para uma comparação detalhada e leitura adicional, veja Associação para a Computação e GeeksforGeeks.
Aplicações dos Arrays de Sufixos na Ciência da Computação
Os arrays de sufixos se tornaram uma estrutura de dados fundamental na ciência da computação, particularmente nos campos de processamento de strings, bioinformática e recuperação de informações. Sua principal utilidade reside em permitir correspondência de padrões eficiente e consultas de substrings. Por exemplo, os arrays de sufixos são amplamente utilizados em motores de busca de texto completo, onde permitem a identificação rápida de todas as ocorrências de uma substring de consulta dentro de um grande corpus de texto. Isso é alcançado aproveitando a ordem classificada lexicograficamente dos sufixos, que suporta operações de busca binária para correspondência de padrões em complexidade de tempo logarítmica Universidade de Princeton.
Na bioinformática, os arrays de sufixos facilitam o alinhamento e a comparação de sequências de DNA e proteínas. Ferramentas para montagem de genomas e alinhamento de sequências, como as usadas em sequenciamento de nova geração, frequentemente dependem de arrays de sufixos para lidar eficientemente com imensos conjuntos de dados biológicos Centro Nacional de Informações Biotecnológicas. Além disso, os arrays de sufixos são integrais para algoritmos de compressão de dados, como a Transformação de Burrows-Wheeler, que fundamenta ferramentas de compressão populares, como o bzip2. Aqui, o array de sufixos permite a transformação dos dados de entrada em uma forma mais propensa à compressão, agrupando caracteres semelhantes bzip2.
Além disso, os arrays de sufixos também são usados em detecção de plágio, deduplicação de dados e na construção de estruturas de dados eficientes para consultas de maior prefixo comum (LCP). Sua versatilidade e eficiência os tornam indispensáveis em aplicações onde processamento rápido e escalável de strings é necessário.
Otimizando Busca e Correspondência de Padrões com Arrays de Sufixos
Os arrays de sufixos são estruturas de dados poderosas que otimizam significativamente operações de busca e correspondência de padrões em strings. Ao armazenar os índices iniciais de todos os sufixos de um texto na ordem lexicográfica, os arrays de sufixos permitem consultas de substrings eficientes, que são fundamentais em aplicações como busca de texto completo, bioinformática e compressão de dados. A principal vantagem de usar um array de sufixos sobre métodos de busca ingênuos é a redução na complexidade de tempo para correspondência de padrões. Enquanto uma abordagem de força bruta pode exigir O(nm) de tempo para um texto de comprimento n e um padrão de comprimento m, os arrays de sufixos permitem buscas de padrões em O(m + log n) de tempo, aproveitando a busca binária nos sufixos classificados.
Para melhorar ainda mais o desempenho, os arrays de sufixos são frequentemente usados em conjunto com estruturas de dados auxiliares, como o array do maior prefixo comum (LCP). O array LCP armazena os comprimentos dos maiores prefixos comuns entre sufixos consecutivos no array de sufixos, permitindo correspondência de padrões ainda mais rápida e facilitando tarefas como encontrar o número de substrings distintas ou a substrings repetida mais longa em tempo linear. Além disso, algoritmos modernos para construir arrays de sufixos, como o método de ordenação induzida, alcançam complexidade de tempo linear, tornando-os práticos para textos em larga escala (Universidade de Helsinque).
Os arrays de sufixos também são eficientes em termos de espaço em comparação com árvores de sufixos, pois requerem apenas O(n) de espaço e são mais fáceis de implementar. Sua eficiência e versatilidade os tornam uma pedra angular no design de sistemas de indexação de textos rápidos e escaláveis e correspondência de padrões (Universidade de Princeton).
Algoritmos Comuns que Utilizam Arrays de Sufixos
Os arrays de sufixos são uma estrutura de dados fundamental no processamento de strings, permitindo soluções eficientes para uma variedade de problemas complexos. Vários algoritmos comuns aproveitam os arrays de sufixos para alcançar um desempenho ótimo ou quase ótimo, particularmente nos domínios de correspondência de padrões, compressão de dados e bioinformática.
Uma das aplicações mais proeminentes é na busca de substrings. Ao combinar um array de sufixos com uma busca binária, é possível localizar todas as ocorrências de um padrão em um texto em O(m log n) de tempo, onde m é o comprimento do padrão e n é o comprimento do texto. Essa abordagem é significativamente mais rápida do que métodos de busca ingênuos, especialmente para textos grandes. Além disso, o array do maior prefixo comum (LCP) é frequentemente construído juntamente com o array de sufixos para otimizar ainda mais consultas de padrões repetidos e facilitar algoritmos para encontrar a substring repetida mais longa ou a substring comum mais longa entre várias strings.
Os arrays de sufixos também são integrais para algoritmos de compressão de dados, como a Transformação de Burrows-Wheeler (BWT), que é um componente chave da ferramenta de compressão bzip2. A BWT depende da ordem classificada dos sufixos para reorganizar o texto de entrada, tornando-o mais apropriado para codificação de comprimento de execução e outras técnicas de compressão (bzip2).
Na bioinformática, os arrays de sufixos são usados para alinhamento de sequências e análise de genomas eficientes, onde a busca rápida e a comparação de sequências de DNA são essenciais (Centro Nacional de Informações Biotecnológicas). Sua eficiência em espaço e velocidade os tornam preferíveis a árvores de sufixos em muitas aplicações em larga escala.
Considerações de Desempenho e Limitações
Os arrays de sufixos são estruturas de dados altamente eficientes para resolver uma variedade de problemas de processamento de strings, como busca de substrings, correspondência de padrões e o cálculo do maior prefixo comum. No entanto, seu desempenho e aplicabilidade são influenciados por várias considerações e limitações inerentes.
Um dos principais fatores de desempenho é o tempo de construção. Enquanto algoritmos ingênuos para construir arrays de sufixos operam em O(n log2 n) de tempo, algoritmos mais avançados conseguem uma complexidade de tempo linear, como o algoritmo SA-IS. No entanto, esses algoritmos ótimos podem ser complexos de implementar e podem ter fatores constantes significativos, que podem afetar o desempenho prático, especialmente para textos muito grandes ou em ambientes com restrições de memória. A complexidade de espaço é outro aspecto importante; um array de sufixos tipicamente requer O(n) de espaço, mas estruturas auxiliares como o array do maior prefixo comum (LCP) ou estruturas de indexação adicionais podem aumentar ainda mais o uso de memória Universidade de Helsinque.
Os arrays de sufixos são menos flexíveis do que árvores de sufixos quando se trata de atualizações dinâmicas, como inserções ou exclusões dentro do texto. Modificar um array de sufixos após sua construção não é trivial e muitas vezes requer a reconstrução de toda a estrutura, tornando-o menos adequado para aplicações onde o texto subjacente muda frequentemente Universidade Carnegie Mellon. Além disso, embora os arrays de sufixos sejam mais eficientes em termos de espaço do que árvores de sufixos, eles ainda podem ser impráticos para conjuntos de dados extremamente grandes, como sequências genômicas inteiras, sem técnicas adicionais de compressão ou memória externa Centro Nacional de Informações Biotecnológicas.
Em resumo, embora os arrays de sufixos ofereçam vantagens significativas em termos de velocidade e eficiência de memória para textos estáticos, suas limitações em cenários dinâmicos e aplicações em larga escala devem ser cuidadosamente consideradas durante o design do sistema.
Casos de Uso e Exemplos do Mundo Real
Os arrays de sufixos são amplamente utilizados em várias aplicações do mundo real que requerem processamento eficiente de strings e correspondência de padrões. Um dos casos de uso mais proeminentes é na bioinformática, particularmente no sequenciamento e análise de genomas. Ferramentas como o Alinhador de Burrows-Wheeler utilizam arrays de sufixos para alinhar rapidamente leituras curtas de DNA a genomas de referência, permitindo estudos genômicos em larga escala e medicina personalizada.
Na recuperação de informações, os arrays de sufixos são fundamentais para implementar motores de busca de texto completo rápidos. Por exemplo, o projeto Apache Lucene utiliza arrays de sufixos e estruturas de dados relacionadas para fornecer capacidades eficientes de busca de substrings, que são essenciais para indexação e consulta de grandes corpora de texto.
Os arrays de sufixos também desempenham um papel crucial em algoritmos de compressão de dados. A ferramenta de compressão bzip2, por exemplo, usa a Transformação de Burrows-Wheeler, que depende da construção de um array de sufixos para reorganizar os dados de entrada e melhorar a compressibilidade.
Além disso, os arrays de sufixos são empregados em sistemas de detecção de plágio, como o Turnitin, para identificar semelhanças entre documentos comparando substrings de forma eficiente. Em processamento de linguagem natural, eles são utilizados para tarefas como identificar frases repetidas, extrair palavras-chave e construir concordâncias.
Esses exemplos destacam a versatilidade e eficiência dos arrays de sufixos na execução de tarefas de processamento de strings em grande escala em diversos domínios, desde biologia computacional até motores de busca e compressão de dados.
Leitura Adicional e Tópicos Avançados
Para leitores interessados em se aprofundar mais nos arrays de sufixos, vários tópicos avançados e recursos estão disponíveis. Uma área significativa é o estudo de arrays de sufixos aprimorados, que aumentam a estrutura básica com dados adicionais, como o array do maior prefixo comum (LCP), permitindo correspondência de padrões e consultas de substrings mais eficientes. A interação entre arrays de sufixos e árvores de sufixos também é um campo rico, pois ambas as estruturas solucionam problemas semelhantes, mas com diferentes compensações em termos de espaço e tempo de construção.
Pesquisas recentes se concentraram em algoritmos de construção em tempo linear para arrays de sufixos, como os algoritmos SA-IS e DC3 (Skew), que são cruciais para lidar com dados genômicos ou textuais em grande escala. Esses algoritmos são discutidos em detalhes na literatura, incluindo o trabalho fundamental do Grupo Funcional de Arrays de Sufixos da Universidade de Helsinque.
As aplicações dos arrays de sufixos se estendem além da correspondência de strings para áreas como compressão de dados (por exemplo, a Transformação de Burrows-Wheeler), bioinformática (montagem e alinhamento de genomas) e recuperação de informações. Para uma visão abrangente, o livro Algoritmos em Strings, Árvores e Sequências de Dan Gusfield é altamente recomendável.
- Arrays de Sufixos: Um Novo Método para Buscas de Strings Online (artigo original de Manber & Myers)
- Construção de Arrays de Sufixos em Tempo Linear Usando Ordenação Induzida (algoritmo SA-IS)
- Wikipedia: Array de Sufixos (visão geral e links adicionais)
Fontes & Referências
- Sociedade Matemática Americana
- Universidade de Princeton
- Departamento de Ciência da Computação, Universidade de Helsinque
- GeeksforGeeks
- Centro Nacional de Informações Biotecnológicas
- Universidade Carnegie Mellon
- Apache Lucene
- Turnitin
- Algoritmos em Strings, Árvores e Sequências
- Wikipedia: Array de Sufixos