Mistrzostwo w Tablicach Nadrzędnych: Ostateczny Przewodnik po Efektywnym Przetwarzaniu Ciągów i Dopasowywaniu Wzorów. Odkryj, jak tablice nadrzędne rewolucjonizują algorytmy tekstowe.
- Wprowadzenie do Tablic Nadrzędnych
- Jak Działają Tablice Nadrzędne: Kluczowe Koncepcje
- Budowanie Tablicy Nadrzędnej: Krok po Kroku
- Tablice Nadrzędne vs. Drzewa Nadrzędne: Kluczowe Różnice
- Zastosowania Tablic Nadrzędnych w Informatyce
- Optymalizacja Wyszukiwania i Dopasowywania Wzorów przy Pomocy Tablic Nadrzędnych
- Powszechne Algorytmy Wykorzystujące Tablice Nadrzędne
- Rozważania na Temat Wydajności i Ograniczenia
- Przykłady i Zastosowania w Rzeczywistości
- Dalsza Lektura i Tematy Zaawansowane
- Źródła i Bibliografia
Wprowadzenie do Tablic Nadrzędnych
Tablica nadrzędna to potężna struktura danych używana w przetwarzaniu ciągów, szczególnie do efektywnego dopasowywania wzorów, zapytań podciągów i indeksowania tekstów. Reprezentuje posortowaną kolejność wszystkich suffixów danego ciągu, zazwyczaj jako tablicę indeksów początkowych. Ta struktura umożliwia różnorodne zastosowania w dziedzinach takich jak bioinformatyka, kompresja danych i wyszukiwanie informacji, gdzie szybkie przeszukiwanie i analiza dużych tekstów są niezbędne.
Koncepcja tablicy nadrzędnej została wprowadzona jako efektywna pod względem pamięci alternatywa dla drzewa nadrzędnego, oferując podobne funkcjonalności, ale z mniejszym narzutem pamięciowym. W przeciwieństwie do drzew nadrzędnych, które mogą być złożone w implementacji i utrzymaniu, tablice nadrzędne są prostsze i bardziej kompaktowe, co czyni je odpowiednimi do zadań przetwarzania dużych tekstów. Budowa tablicy nadrzędnej polega na sortowaniu wszystkich możliwych suffixów ciągu, co można osiągnąć w czasie O(n log n) przy użyciu algorytmów opartych na porównaniach lub nawet w czasie liniowym z wykorzystaniem zaawansowanych technik, takich jak metoda sortowania indukowanego (American Mathematical Society).
Tablice nadrzędne są często używane w połączeniu z pomocniczymi strukturami danych, takimi jak tablica Najdłuższego Wspólnego Prefiksu (LCP), co dodatkowo zwiększa ich użyteczność w rozwiązywaniu problemów takich jak znajdowanie najdłuższego powtarzającego się podciągu czy wykonywanie szybkich porównań leksykograficznych. Ich wydajność i wszechstronność sprawiły, że tablice nadrzędne stały się podstawowym narzędziem w nowoczesnej analizie algorytmicznej ciągów (Princeton University).
Jak Działają Tablice Nadrzędne: Kluczowe Koncepcje
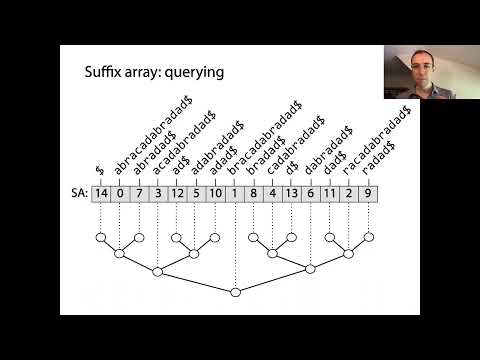
Tablice nadrzędne to potężne struktury danych, które umożliwiają efektywne przetwarzanie ciągów, szczególnie w kontekście dopasowywania wzorów i indeksowania tekstów. W swojej istocie tablice nadrzędne reprezentują posortowaną kolejność wszystkich możliwych suffixów danego ciągu. Budowa rozpoczyna się od generowania każdego suffixu z ciągu wejściowego, każdy rozpoczynający się w innej pozycji. Następnie te suffixy są sortowane leksykograficznie, a sama tablica nadrzędna to tablica liczb całkowitych, gdzie każdy wpis wskazuje indeks początkowy suffixu w tej posortowanej kolejności.
Kluczową koncepcją stojącą za tablicami nadrzędnymi jest to, że poprzez sortowanie wszystkich suffixów można przeprowadzać szybkie wyszukiwania binarne w celu lokalizacji podciągów lub wzorów w oryginalnym tekście. To znacząca poprawa w porównaniu do naiwnych metod wyszukiwania, które mogą wymagać przeszukania całego tekstu dla każdego zapytania. Tablice nadrzędne są często połączone z tablicą Najdłuższego Wspólnego Prefiksu (LCP), która przechowuje długości najdłuższych wspólnych prefiksów między kolejnymi suffixami w posortowanej tablicy. To połączenie przyspiesza różne operacje na ciągach, takie jak znajdowanie powtarzających się podciągów czy liczba różnych podciągów.
Efektywne algorytmy budowy, takie jak metoda sortowania indukowanego lub stosowanie podwajania prefiksów, zmniejszyły złożoność czasową budowy tablic nadrzędnych do czasu liniowego lub bliskiego liniowego, co czyni je praktycznymi w zastosowaniach na dużą skalę. Tablice nadrzędne są szeroko stosowane w bioinformatyce, kompresji danych i wyszukiwaniu informacji, gdzie szybkie i wydajne przetwarzanie ciągów jest niezbędne. Aby uzyskać szczegółowy przegląd podstawowych zasad i algorytmów, zapoznaj się z dokumentacją Wydziału Informatyki Uniwersytetu Helsińskiego.
Budowanie Tablicy Nadrzędnej: Krok po Kroku
Budowanie tablicy nadrzędnej polega na skonstruowaniu posortowanej tablicy wszystkich suffixów danego ciągu, reprezentowanych przez ich indeksy początkowe. Proces ten można podzielić na kilka kluczowych kroków:
- 1. Generowanie Wszystkich Suffixów: Dla ciągu o długości n, należy wyliczyć wszystkie suffixy według ich pozycji początkowych. Na przykład ciąg „banana” daje suffixy zaczynające się na indeksach 0 („banana”), 1 („anana”), 2 („nana”) itd.
- 2. Sortowanie Suffixów: Sortuj te suffixy leksykograficznie. To można zrobić naiwnie w czasie O(n2 log n) poprzez porównanie ciągów bezpośrednio, ale istnieją bardziej efektywne algorytmy.
- 3. Przechowywanie Indeksów: Zamiast przechowywać rzeczywiste ciągi suffixów, przechowuj ich indeksy początkowe w posortowanej kolejności. Ta tablica indeksów to tablica nadrzędna.
- 4. Optymalizacja: Zaawansowane algorytmy, takie jak algorytm Manber-Myers, używają techniki podwajania, aby osiągnąć złożoność czasową O(n log n). Jeszcze szybciej, algorytm Karkkainen-Sanders (znany także jako algorytm Skew) może skonstruować tablicę nadrzędną w czasie liniowym O(n) dla alfabetów całkowitych. Te metody opierają się na sortowaniu według rang i strategiach rekurencyjnych, aby uniknąć bezpośrednich porównań ciągów Association for Computing Machinery.
- 5. Ostateczny Wynik: Otrzymana tablica nadrzędna umożliwia efektywne dopasowywanie wzorów, zapytania podciągów i jest podstawowa do konstruowania innych struktur danych, takich jak tablica LCP GeeksforGeeks.
Zrozumienie każdego kroku i dostępnych optymalizacji jest kluczowe dla wykorzystania tablic nadrzędnych w zastosowaniach przetwarzania ciągów na dużą skalę.
Tablice Nadrzędne vs. Drzewa Nadrzędne: Kluczowe Różnice
Tablice nadrzędne i drzewa nadrzędne to obie podstawowe struktury danych umożliwiające efektywne przetwarzanie ciągów, szczególnie w zastosowaniach takich jak dopasowywanie wzorów, bioinformatyka i kompresja danych. Choć służą podobnym celom, ich struktury, wymagania pamięciowe i charakterystyka operacyjna różnią się znacznie.
Drzewo nadrzędne to skompresowane drzewo trie wszystkich suffixów danego ciągu, co umożliwia niezwykle szybkie zapytania podciągów, zazwyczaj w czasie liniowym w stosunku do długości wzoru. Jednak drzewa nadrzędne są skomplikowane w implementacji i wymagają znacznego nadmiaru pamięci—często kilka razy więcej niż oryginalny ciąg—z powodu swojej struktury opartej na węzłach i potrzeby przechowywania wskaźników i etykiet krawędzi. To czyni je mniej praktycznymi w przypadku bardzo dużych zbiorów danych lub środowisk o ograniczonej pamięci.
W przeciwieństwie do tego, tablica nadrzędna to znacznie prostsza i bardziej oszczędna pod względem pamięci struktura danych. Składa się z tablicy liczb całkowitych reprezentujących pozycje początkowe wszystkich posortowanych suffixów ciągu. Tablice nadrzędne można skonstruować w czasie liniowym i wymagają tylko O(n) pamięci, gdzie n to długość ciągu. Chociaż wyszukiwania podciągów przy użyciu tablicy nadrzędnej są zazwyczaj wolniejsze niż przy użyciu drzewa nadrzędnego (O(m log n) dla wzoru o długości m), to można to poprawić do O(m) z pomocą struktur danych pomocniczych, takich jak tablica Najdłuższego Wspólnego Prefiksu (LCP). Prostota i mniejszy rozmiar pamięci tablic nadrzędnych sprawiają, że są one preferowane do zadań indeksowania i wyszukiwania w dużych tekstach.
Dla szczegółowego porównania i dalszej lektury, zobacz Association for Computing Machinery oraz GeeksforGeeks.
Zastosowania Tablic Nadrzędnych w Informatyce
Tablice nadrzędne stały się podstawową strukturą danych w informatyce, szczególnie w dziedzinach takich jak przetwarzanie ciągów, bioinformatyka i wyszukiwanie informacji. Ich główna użyteczność polega na umożliwieniu efektywnego dopasowywania wzorów i zapytań podciągów. Na przykład, tablice nadrzędne są szeroko stosowane w wyszukiwarkach pełnotekstowych, gdzie pozwalają na szybką identyfikację wszystkich wystąpień podciągu zapytania w dużym zbiorze tekstów. Umożliwia to wykorzystanie leksykograficznie posortowanej kolejności suffixów, co wspiera operacje wyszukiwania binarnego w celu dopasowania wzorów przy złożoności czasowej logarytmicznej Princeton University.
W bioinformatyce, tablice nadrzędne ułatwiają wyrównywanie i porównywanie sekwencji DNA i białek. Narzędzia do składania genomu i wyrównywania sekwencji, takie jak te stosowane w sekwencjonowaniu następnej generacji, często opierają się na tablicach nadrzędnych, aby skutecznie obsługiwać ogromne zbiory danych biologicznych National Center for Biotechnology Information. Dodatkowo, tablice nadrzędne są integralną częścią algorytmów kompresji danych, takich jak Transformata Burrowsa-Wheelera, która stanowi podstawę popularnych narzędzi kompresji, takich jak bzip2. W tym przypadku tablica nadrzędna umożliwia przekształcenie danych wejściowych w formę bardziej odpowiednią do kompresji, grupując podobne znaki razem bzip2.
Poza tym, tablice nadrzędne są także stosowane w detekcji plagiatów, deduplikacji danych oraz budowie wydajnych struktur danych do zapytań o najdłuższy wspólny prefiks (LCP). Ich wszechstronność i wydajność sprawiają, że są niezastąpione w zastosowaniach, gdzie wymagane jest szybkie i skalowalne przetwarzanie ciągów.
Optymalizacja Wyszukiwania i Dopasowywania Wzorów przy Pomocy Tablic Nadrzędnych
Tablice nadrzędne to potężne struktury danych, które znacząco optymalizują operacje wyszukiwania i dopasowywania wzorów w ciągach. Przechowując indeksy początkowe wszystkich suffixów tekstu w kolejności leksykograficznej, tablice nadrzędne umożliwiają efektywne zapytania podciągów, które są podstawowe w zastosowaniach takich jak wyszukiwanie pełnotekstowe, bioinformatyka i kompresja danych. Główną zaletą korzystania z tablicy nadrzędnej nad naiwnymi metodami wyszukiwania jest zmniejszenie złożoności czasowej dla dopasowania wzorów. Podczas gdy podejście brutalne może wymagać O(nm) czasu dla tekstu o długości n i wzoru o długości m, tablice nadrzędne umożliwiają wyszukiwanie wzorów w czasie O(m + log n), wykorzystując wyszukiwanie binarne na posortowanych suffixach.
Aby dodatkowo zwiększyć wydajność, tablice nadrzędne często są używane w połączeniu z pomocniczymi strukturami danych, takimi jak tablica Najdłuższego Wspólnego Prefiksu (LCP). Tablica LCP przechowuje długości najdłuższych wspólnych prefiksów między kolejnymi suffixami w tablicy nadrzędnej, co umożliwia jeszcze szybsze dopasowywanie wzorów i ułatwia takie zadania jak znajdowanie liczby różnych podciągów czy najdłuższego powtarzającego się podciągu w czasie liniowym. Dodatkowo, nowoczesne algorytmy do budowy tablic nadrzędnych, takie jak metoda sortowania indukowanego, osiągają liniową złożoność czasową, co czyni je praktycznymi dla dużych tekstów (Uniwersytet Helsiński).
Tablice nadrzędne są także oszczędne pod względem pamięci w porównaniu do drzew nadrzędnych, ponieważ wymagają tylko O(n) pamięci i są łatwiejsze w implementacji. Ich wydajność i wszechstronność czynią je fundamentem w projektowaniu szybkich i skalowalnych systemów indeksowania tekstów i dopasowywania wzorów (Princeton University).
Powszechne Algorytmy Wykorzystujące Tablice Nadrzędne
Tablice nadrzędne to podstawowa struktura danych w przetwarzaniu ciągów, umożliwiająca efektywne rozwiązania różnorodnych złożonych problemów. Several common algorithms leverage suffix arrays to achieve optimal or near-optimal performance, particularly in the domains of pattern matching, data compression, and bioinformatics.
Jednym z najbardziej prominentnych zastosowań jest wyszukiwanie podciągów. Łącząc tablicę nadrzędną z wyszukiwaniem binarnym, można zlokalizować wszystkie wystąpienia wzoru w tekście w O(m log n) czasie, gdzie m to długość wzoru, a n to długość tekstu. To podejście jest znacznie szybsze niż naiwną metodą wyszukiwania, szczególnie dla dużych tekstów. Dodatkowo, tablica Najdłuższego Wspólnego Prefiksu (LCP) jest często tworzona równolegle z tablicą nadrzędną, aby dodatkowo zoptymalizować zapytania o powtarzające się wzory i ułatwić algorytmy do znajdowania najdłuższego powtarzającego się podciągu lub najdłuższego wspólnego podciągu między wieloma ciągami.
Tablice nadrzędne są także integralną częścią algorytmów kompresji danych, takich jak Transformata Burrowsa-Wheelera (BWT), która jest kluczowym komponentem narzędzia kompresji bzip2. BWT opiera się na posortowanej kolejności suffixów, aby przearanżować tekst wejściowy, co czyni go bardziej odpowiednim do kodowania długości biegów i innych technik kompresji (bzip2).
W bioinformatyce, tablice nadrzędne są wykorzystywane do efektywnego wyrównywania sekwencji i analizy genomu, gdzie szybkie wyszukiwanie i porównywanie sekwencji DNA jest niezbędne (National Center for Biotechnology Information). Ich oszczędność pamięci i szybkość sprawiają, że są preferowane w porównaniu z drzewami nadrzędnymi w wielu zastosowaniach na dużą skalę.
Rozważania na Temat Wydajności i Ograniczenia
Tablice nadrzędne to wysoko wydajne struktury danych do rozwiązywania różnorodnych problemów związanych z przetwarzaniem ciągów, takich jak wyszukiwanie podciągów, dopasowywanie wzorów i obliczanie najdłuższego wspólnego prefiksu. Jednak ich wydajność i zastosowanie są wpływane przez kilka rozważań i wrodzonych ograniczeń.
Jednym z podstawowych czynników wydajności jest czas konstrukcji. Podczas gdy naiwnе algorytmy do budowy tablic nadrzędnych działają w czasie O(n log2 n), bardziej zaawansowane algorytmy osiągają liniową złożoność czasową, takie jak algorytm SA-IS. Niemniej jednak, te optymalne algorytmy mogą być złożone w implementacji i mogą mieć znaczne czynniki stałe, co może wpłynąć na wydajność praktyczną, szczególnie dla bardzo dużych tekstów lub w środowiskach o ograniczonej pamięci. Złożoność przestrzenna to kolejny ważny aspekt; tablica nadrzędna zazwyczaj wymaga O(n) pamięci, ale struktury pomocnicze, takie jak tablica Najdłuższego Wspólnego Prefiksu (LCP) lub dodatkowe struktury indeksujące, mogą znacznie zwiększyć wykorzystanie pamięci Uniwersytet Helsiński.
Tablice nadrzędne są mniej elastyczne niż drzewa nadrzędne w kontekście dynamicznych aktualizacji, takich jak wstawianie lub usuwanie w obrębie tekstu. Modyfikowanie tablicy nadrzędnej po jej konstrukcji jest skomplikowane i często wymaga odbudowania całej struktury, co czyni ją mniej odpowiednią do zastosowań, w których podstawowy tekst zmienia się często Carnegie Mellon University. Dodatkowo, podczas gdy tablice nadrzędne są bardziej oszczędne pod względem przestrzeni niż drzewa nadrzędne, mogą być nadal niepraktyczne dla ekstremalnie dużych zbiorów danych, takich jak pełne sekwencje genomowe, bez dodatkowej kompresji lub technik pamięci zewnętrznej National Center for Biotechnology Information.
Podsumowując, podczas gdy tablice nadrzędne oferują znaczące zalety pod względem szybkości i efektywności pamięci dla statycznych tekstów, ich ograniczenia w dynamicznych scenariuszach i zastosowaniach na dużą skalę muszą być starannie rozważone podczas projektowania systemu.
Przykłady i Zastosowania w Rzeczywistości
Tablice nadrzędne są szeroko stosowane w różnych rzeczywistych zastosowaniach, które wymagają efektywnego przetwarzania ciągów i dopasowywania wzorów. Jednym z najbardziej znaczących zastosowań jest bioinformatyka, szczególnie w sekwencjonowaniu i analizie genomu. Narzędzia takie jak Burrows-Wheeler Aligner wykorzystują tablice nadrzędne, aby szybko wyrównywać krótkie odczyty DNA do genomów odniesienia, umożliwiając duże badania genomowe i medycynę spersonalizowaną.
W wyszukiwaniu informacji tablice nadrzędne są fundamentalne dla wdrażania szybkich wyszukiwarek pełnotekstowych. Na przykład projekt Apache Lucene wykorzystuje tablice nadrzędne i pokrewne struktury danych do zapewnienia efektywnych możliwości wyszukiwania podciągów, które są niezbędne do indeksowania i zapytań w dużych zbiorach tekstowych.
Tablice nadrzędne odgrywają również kluczową rolę w algorytmach kompresji danych. Narzędzie kompresji bzip2, na przykład, wykorzystuje Transformację Burrowsa-Wheelera, która polega na skonstruowaniu tablicy nadrzędnej, aby przearanżować dane wejściowe i poprawić ich kompresyjność.
Dodatkowo, tablice nadrzędne są wykorzystywane w systemach detekcji plagiatów, takich jak Turnitin, aby identyfikować podobieństwa między dokumentami poprzez efektywne porównywanie podciągów. W przetwarzaniu języka naturalnego są używane do zadań takich jak identyfikacja powtarzających się fraz, ekstrakcja słów kluczowych i budowa konkordancji.
Te przykłady podkreślają wszechstronność i efektywność tablic nadrzędnych w obsłudze zadań przetwarzania ciągów na dużą skalę w różnych dziedzinach, od biologii obliczeniowej po silniki wyszukujące i kompresję danych.
Dalsza Lektura i Tematy Zaawansowane
Dla czytelników zainteresowanych zgłębieniem tematu tablic nadrzędnych dostępnych jest kilka zaawansowanych tematów i zasobów. Jednym z istotnych obszarów jest badanie wzbogaconych tablic nadrzędnych, które rozszerzają podstawową strukturę o dodatkowe dane, takie jak tablica Najdłuższego Wspólnego Prefiksu (LCP), co umożliwia bardziej efektywne dopasowywanie wzorów i zapytania podciągów. Współzależność między tablicami nadrzędnymi a drzewami nadrzędnymi to także bogaty temat, ponieważ obie struktury rozwiązują podobne problemy, ale z różnymi kompromisami w zakresie pamięci i czasu budowy.
Najnowsze badania koncentrują się na algorytmach budowy w czasie liniowym dla tablic nadrzędnych, takich jak algorytmy SA-IS i DC3 (Skew), które są kluczowe do obsługi dużych zbiorów danych genomicznych lub tekstowych. Te algorytmy są szczegółowo omawiane w literaturze, w tym w pracach fundamentowych Grupy Funkcyjnej Tablic Nadrzędnych Uniwersytetu Helsińskiego.
Zastosowanie tablic nadrzędnych wykracza poza dopasowywanie ciągów, obejmując takie obszary jak kompresja danych (np. Transformata Burrowsa-Wheelera), bioinformatyka (składanie i wyrównywanie genomów) oraz wyszukiwanie informacji. Aby uzyskać kompleksowy przegląd, książka Algorytmy na Ciągach, Drzewach i Sekwencjach autorstwa Dana Gusfielda jest niezwykle polecana.
- Tablice Nadrzędne: Nowa Metoda dla Wyszukiwań On-Line Ciągów (oryginalny artykuł autorstwa Manbera i Myersa)
- Budowa Tablic Nadrzędnych w Czasie Liniowym przy Użyciu Sortowania Indukowanego (algorytm SA-IS)
- Wikipedia: Tablica Nadrzędna (przegląd i dalsze linki)
Źródła i Bibliografia
- American Mathematical Society
- Princeton University
- Wydział Informatyki Uniwersytetu Helsińskiego
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorytmy na Ciągach, Drzewach i Sekwencjach
- Wikipedia: Tablica Nadrzędna