접미사 배열 마스터하기: 효율적인 문자열 처리 및 패턴 매칭을 위한 궁극적인 가이드. 접미사 배열이 텍스트 알고리즘을 어떻게 혁신하는지 알아보세요.
- 접미사 배열 소개
- 접미사 배열 작동 원리: 핵심 개념
- 접미사 배열 구축: 단계별
- 접미사 배열 vs. 접미사 트리: 주요 차이점
- 컴퓨터 과학에서의 접미사 배열 응용
- 접미사 배열을 통한 검색 및 패턴 매칭 최적화
- 접미사 배열을 활용하는 일반적인 알고리즘
- 성능 고려사항 및 한계
- 실세계 사용 사례 및 예시
- 추가 읽기 및 고급 주제
- 출처 및 참고문헌
접미사 배열 소개
접미사 배열은 문자열 처리에 사용되는 강력한 데이터 구조로, 특히 효율적인 패턴 매칭, 부분 문자열 쿼리 및 텍스트 인덱싱에 적합합니다. 주어진 문자열의 모든 접미사의 정렬된 순서를 나타내며, 일반적으로 시작 인덱스의 배열로 표현됩니다. 이 구조는 급속한 검색과 대규모 텍스트 분석이 필수적인 생물정보학, 데이터 압축 및 정보 검색과 같은 분야에서 다양한 응용 프로그램을 가능하게 합니다.
접미사 배열 개념은 메모리 오버헤드를 줄이면서 접미사 트리와 유사한 기능을 제공하는 공간 효율적인 대안으로 도입되었습니다. 접미사 트리와 달리 구현 및 유지 관리가 복잡할 수 있는 접미사 배열은 더 간단하고 컴팩트하여 대규모 텍스트 처리 작업에 적합합니다. 접미사 배열의 구성은 문자열의 모든 가능한 접미사를 정렬하는 과정을 포함하며, 이는 비교 기반 알고리즘을 사용하여 O(n log n) 시간에 달성할 수 있으며, 더 발전된 기법인 유도 정렬 방법을 사용하면 선형 시간에 달성할 수 있습니다 (American Mathematical Society).
접미사 배열은 종종 가장 긴 공통 접두사(LCP) 배열과 같은 보조 데이터 구조와 함께 사용되며, 이는 가장 긴 반복 부분 문자열을 찾거나 빠른 사전식 비교를 수행하는 문제를 해결하는 데 추가적인 유용성을 제공합니다. 이들의 효율성과 다재다능성 덕분에 접미사 배열은 현대 알고리즘 문자열 분석의 기본 도구가 되었습니다 (Princeton University).
접미사 배열 작동 원리: 핵심 개념
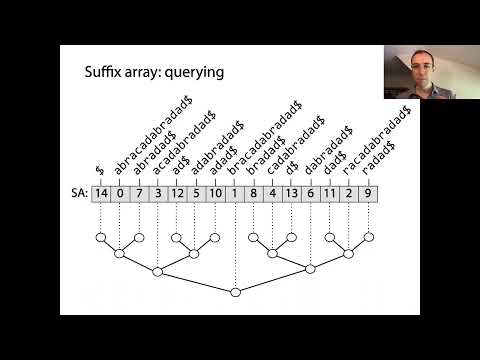
접미사 배열은 강력한 데이터 구조로, 효율적인 문자열 처리를 가능하게 합니다. 특히 패턴 매칭 및 텍스트 인덱싱에 중점을 둡니다. 기본적으로 접미사 배열은 주어진 문자열의 모든 가능한 접미사의 정렬된 순서를 나타냅니다. 구조는 입력 문자열의 모든 접미사를 생성하는 것에서 시작하며, 각 시작 위치에서 시작하게 됩니다. 이러한 접미사는 사전식으로 정렬되며, 접미사 배열 자체는 정렬된 순서에서 접미사의 시작 인덱스를 나타내는 정수 배열입니다.
접미사 배열의 핵심 개념은 모든 접미사를 정렬함으로써 원본 텍스트 내에서 부분 문자열이나 패턴을 찾기 위해 빠른 이진 검색을 수행할 수 있다는 것입니다. 이는 각 쿼리마다 전체 텍스트를 스캔해야 할 수도 있는 단순 검색 방법에 비해 큰 개선입니다. 접미사 배열은 종종 접미사 배열에서 연속 접미사 간의 가장 긴 공통 접두사 길이를 저장하는 LCP 배열과 함께 사용되어 다양한 문자열 작업을 더욱 가속화합니다. 반복되는 부분 문자열을 찾거나 고유한 부분 문자열의 개수를 세는 등의 작업이 이를 통해 가능합니다.
유도 정렬 방법이나 접두사 배가와 같은 효율적인 구성 알고리즘은 접미사 배열 구축의 시간 복잡도를 선형 또는 거의 선형 시간으로 줄여 대규모 응용에서 실용적이게 만듭니다. 접미사 배열은 생물정보학, 데이터 압축 및 정보 검색 분야에서 빠르고 메모리 효율적인 문자열 처리가 필수적이기 때문에 널리 사용됩니다. 기본 원리와 알고리즘에 대한 포괄적인 개요는 헬싱키 대학교 컴퓨터 과학부의 문서를 참조하십시오.
접미사 배열 구축: 단계별
접미사 배열을 구축하는 것은 주어진 문자열의 모든 접미사의 정렬된 배열을 시작 인덱스 형태로 구성하는 작업이 포함됩니다. 이 과정은 여러 핵심 단계로 나눌 수 있습니다:
- 1. 모든 접미사 생성: 길이 n의 문자열에 대해 시작 위치에 따라 모든 접미사를 열거합니다. 예를 들어, 문자열 “banana”는 인덱스 0에서 시작하는 접미사(“banana”), 인덱스 1에서 시작하는 접미사(“anana”), 인덱스 2에서 시작하는 접미사(“nana”) 등을 생성합니다.
- 2. 접미사 정렬: 이러한 접미사를 사전식으로 정렬합니다. 이는 문자열을 직접 비교하여 O(n2 log n) 시간에 단순하게 수행할 수 있지만, 더 효율적인 알고리즘도 존재합니다.
- 3. 인덱스 저장: 실제 접미사 문자열을 저장하는 대신, 정렬된 순서에서 시작 인덱스만 저장합니다. 이 인덱스 배열이 바로 접미사 배열입니다.
- 4. 최적화: Manber-Myers 알고리즘과 같은 고급 알고리즘은 배가 기법을 사용하여 O(n log n)의 시간 복잡도를 달성합니다. 더 나아가 Karkkainen-Sanders 알고리즘(또는 Skew 알고리즘)은 정수 알파벳에 대해 선형 시간 O(n)으로 접미사 배열을 구성할 수 있습니다. 이러한 방법들은 직접 문자열 비교를 피하기 위해 순위 정렬 및 재귀적 접근 방식을 활용합니다 Association for Computing Machinery.
- 5. 최종 출력: 생성된 접미사 배열은 효율적인 패턴 매칭, 부분 문자열 쿼리를 가능하게 하며, LCP 배열과 같은 다른 데이터 구조 구축의 기초가 됩니다 GeeksforGeeks.
각 단계와 사용 가능한 최적화를 이해하는 것은 대규모 문자열 처리 응용 프로그램에서 접미사 배열을 활용하는 데 매우 중요합니다.
접미사 배열 vs. 접미사 트리: 주요 차이점
접미사 배열과 접미사 트리는 효율적인 문자열 처리를 위한 기본적인 데이터 구조로, 특히 패턴 매칭, 생물정보학 및 데이터 압축과 같은 응용에 사용됩니다. 두 구조는 유사한 목적을 가지고 있지만, 그 구조, 메모리 요구 사항 및 운영 특성에는 상당한 차이가 있습니다.
접미사 트리는 주어진 문자열의 모든 접미스로 구성된 압축 트라이로, 보통 패턴 길이에 비례하여 선형 시간에서 매우 빠른 부분 문자열 쿼리를 가능하게 합니다. 하지만, 접미사 트리는 구현이 복잡하고 포인터와 엣지 레이블을 저장하기 위해 원래 문자열의 크기의 여러 배에 달하는 상당한 메모리 오버헤드를 필요로 합니다. 이는 매우 큰 데이터 세트나 메모리가 제한된 환경에서 실용적이지 않게 만듭니다.
반대로, 접미사 배열은 훨씬 더 간단하고 공간 효율적인 데이터 구조입니다. 이는 문자열의 모든 정렬된 접미사의 시작 위치를 나타내는 정수 배열로 구성됩니다. 접미사 배열은 선형 시간에 구축할 수 있으며, 문자열의 길이 n에 대해 단지 O(n)의 메모리만 요구합니다. 접미사 배열을 사용할 때의 부분 문자열 검색은 일반적으로 접미사 트리보다 느리지만 (O(m log n)), 가장 긴 공통 접두사(LCP) 배열과 같은 보조 데이터 구조에 의해 개선될 수 있습니다. 접미사 배열의 단순성과 더 낮은 메모리 요구량 때문에 대규모 텍스트 인덱싱 및 검색 작업에 더 바람직합니다.
자세한 비교와 추가 읽기를 위해 Association for Computing Machinery 및 GeeksforGeeks를 참고하세요.
컴퓨터 과학에서의 접미사 배열 응용
접미사 배열은 컴퓨터 과학의 기본 데이터 구조로 자리 잡았으며, 특히 문자열 처리, 생물정보학 및 정보 검색 분야에서 중요한 역할을 합니다. 주요 유틸리티는 효율적인 패턴 매칭 및 부분 문자열 쿼리를 가능하게 한다는 점입니다. 예를 들어, 접미사 배열은 전체 텍스트 검색 엔진에서 널리 사용되며, 대규모 텍스트 말뭉치 내의 쿼리 부분 문자열의 모든 발생을 신속하게 식별할 수 있게 해줍니다. 이는 접미사의 사전식 정렬 순서를 활용하여 패턴 매칭을 위한 이진 검색 작업을 로그 시간 복잡도로 지원합니다 Princeton University.
생물정보학에서는 접미사 배열이 DNA 및 단백질 서열의 정렬 및 비교를 용이하게 합니다. 유전체 조립 및 서열 정렬 도구, 특히 차세대 시퀀싱에 사용되는 도구들은 대규모 생물학적 데이터를 효율적으로 처리하기 위해 접미사 배열에 의존합니다 National Center for Biotechnology Information. 또한, 접미사 배열은 버로우스-휠러 변환(BWT)과 같은 데이터 압축 알고리즘에 필수적이며, 이는 bzip2와 같은 인기 있는 압축 도구의 기초가 됩니다. 이 경우 접미사 배열은 입력 데이터를 더 압축하기 쉬운 형태로 변환하는 데 도움을 줍니다.
그 외에도 접미사 배열은 표절 탐지, 데이터 중복 제거 및 가장 긴 공통 접두사(LCP) 쿼리를 위한 효율적인 데이터 구조 구축에 사용됩니다. 이들의 다재다능성과 효율성 덕분에 빠르고 확장 가능한 문자열 처리가 필요한 응용에서 가장 중요한 도구로 자리 잡았습니다.
접미사 배열을 통한 검색 및 패턴 매칭 최적화
접미사 배열은 문자열에서 검색 및 패턴 매칭 작업을 크게 최적화하는 강력한 데이터 구조입니다. 텍스트의 모든 접미사의 시작 인덱스를 사전식 순서로 저장함으로써, 접미사 배열은 효율적인 부분 문자열 쿼리를 가능하게 하며, 이는 전체 텍스트 검색, 생물정보학 및 데이터 압축과 같은 응용의 기본입니다. 접미사 배열을 사용하는 주요 이점은 패턴 매칭 시 시간 복잡도를 감소시키는 것입니다. 강제적인 접근은 길이 n의 텍스트와 길이 m의 패턴에 대해 O(nm) 시간을 요구할 수 있지만, 접미사 배열을 사용하면 정렬된 접미사에서 이진 검색을 활용하여 O(m + log n) 시간 내에 패턴 검색이 가능합니다.
성능을 더욱 향상시키기 위해 접미사 배열은 종종 LCP 배열과 같은 보조 데이터 구조와 함께 사용됩니다. LCP 배열은 접미사 배열에서 연속 접미사 간의 가장 긴 공통 접두사 길이를 저장하여 패턴 매칭을 더욱 빠르게 하고, 고유한 부분 문자열 개수 세기 또는 가장 긴 반복 부분 문자열 찾기와 같은 작업을 선형 시간 내에 가능하게 합니다. 또한, 유도 정렬 방법과 같은 현대 접미사 배열 구성 알고리즘은 선형 시간 복잡도를 달성하여 대규모 텍스트에 실용적입니다 (헬싱키 대학교).
접미사 배열은 접미사 트리에 비해 공간 효율적이며, 오히려 O(n) 공간만 요구하고 구현이 쉽습니다. 이들의 효율성과 다재다능성 덕분에 빠르고 확장 가능한 텍스트 인덱싱 및 패턴 매칭 시스템 설계에서 핵심 요소가 되고 있습니다 (Princeton University).
접미사 배열을 활용하는 일반적인 알고리즘
접미사 배열은 문자열 처리의 기본 데이터 구조로, 다양한 복잡한 문제에 대해 효율적인 솔루션을 가능하게 합니다. 여러 일반적인 알고리즘이 접미사 배열을 활용하여 패턴 매칭, 데이터 압축 및 생물정보학 분야에서 최적 또는 근사 최적 성능에 도달하고 있습니다.
가장 두드러진 응용 중 하나는 부분 문자열 검색입니다. 접미사 배열과 이진 검색을 결합하면 텍스트 내에서 패턴의 모든 발생을 O(m log n) 시간 내에 찾을 수 있으며, 여기서 m은 패턴 길이, n은 텍스트 길이입니다. 이 방법은 대규모 텍스트에 대해 단순 검색 방법보다 훨씬 빠릅니다. 또한, Longest Common Prefix (LCP) 배열은 일반적으로 접미사 배열과 함께 구성되어 반복 패턴 쿼리를 더욱 최적화하고, 여러 문자열 간의 가장 긴 반복된 부분 문자열이나 가장 긴 공통 부분 문자열을 찾는 알고리즘을 더 쉽게 합니다.
접미사 배열은 데이터 압축 알고리즘인 버로우스-휠러 변환(BWT)에도 필수적이며, 이는 bzip2 압축 도구의 핵심 구성 요소입니다. BWT는 접미사의 정렬된 순서를 활용하여 입력 텍스트를 재배열하여 런 길이 인코딩 및 다른 압축 기술에 더욱 적합하게 만듭니다 (bzip2).
생물정보학에서, 접미사 배열은 효율적인 서열 정렬 및 유전체 분석에 사용되며, 빠른 DNA 서열 검색 및 비교가 필수적입니다 (National Center for Biotechnology Information). 이들의 공간 효율성과 속도 덕분에 많은 대규모 응용에서 접미사 트리보다 선호됩니다.
성능 고려사항 및 한계
접미사 배열은 부분 문자열 검색, 패턴 매칭 및 가장 긴 공통 접두사 계산과 같은 다양한 문자열 처리 문제를 해결하기 위한 매우 효율적인 데이터 구조입니다. 하지만, 이들의 성능 및 적용 가능성은 여러 고려 사항 및 내재된 한계에 영향을 받습니다.
주요 성능 요소 중 하나는 구성 시간입니다. 단순 알고리즘은 O(n log2 n) 시간에 작동하지만, 보다 발전된 알고리즘은 선형 시간 복잡도를 달성합니다, 예를 들어 SA-IS 알고리즘처럼요. 그럼에도 불구하고 이러한 최적 알고리즘은 구현하기 복잡할 수 있으며 상당한 상수 요소를 가질 수 있어, 특히 매우 큰 텍스트나 메모리가 제한된 환경에서는 실질적인 성능에 영향을 줄 수 있습니다. 공간 복잡성 또한 중요한 측면이며; 접미사 배열은 일반적으로 O(n)의 공간을 요구하지만, LCP 배열이나 추가 인덱스 구조와 같은 보조 구조는 메모리 사용량을 더욱 증가시킬 수 있습니다 헬싱키 대학교.
접미사 배열은 텍스트 내에서 삽입이나 삭제와 같은 동적 업데이트 시에는 접미사 트리보다 유연성이 떨어집니다. 접미사 배열을 구축한 후 수정하는 것은 비간단하며 전체 구조를 재구성해야 할 수도 있어, 텍스트가 자주 변경되는 응용에는 적합하지 않습니다 Carnegie Mellon University. 또한, 접미사 배열은 접미사 트리보다 더 공간 효율적이지만, 전체 유전체 서열과 같은 매우 큰 데이터세트에 대해서는 추가 압축이나 외부 메모리 기술이 없이는 여전히 비실용적일 수 있습니다 National Center for Biotechnology Information.
요약하자면, 접미사 배열은 정적 텍스트에 대한 속도와 메모리 효율성 면에서 중요한 이점을 제공하지만, 동적 시나리오 및 대규모 응용에서의 한계는 시스템 설계 시 신중하게 고려해야 합니다.
실세계 사용 사례 및 예시
접미사 배열은 효율적인 문자열 처리 및 패턴 매칭이 요구되는 다양한 실세계 응용에서 널리 사용되고 있습니다. 가장 두드러진 사용 사례 중 하나는 생물정보학 분야에서 유전체 서열 분석입니다. Burrows-Wheeler Aligner와 같은 도구는 접미사 배열을 이용하여 짧은 DNA 리드를 참조 유전체에 신속하게 정렬함으로써 대규모 유전체 연구 및 개인 맞춤 의료를 가능하게 합니다.
정보 검색 분야에서는 접미사 배열이 빠른 전체 텍스트 검색 엔진 구현의 기본입니다. 예를 들어, Apache Lucene 프로젝트는 접미사 배열과 관련 데이터 구조를 활용하여 대규모 텍스트 말뭉치에 대한 효율적인 부분 문자열 검색 기능을 제공합니다.
접미사 배열은 데이터 압축 알고리즘에도 중요한 역할을 합니다. 예를 들어, bzip2 압축 도구는 버로우스-휠러 변환을 사용하여 입력 데이터를 재정렬하고 압축 가능성을 향상시킵니다.
또한, 접미사 배열은 문서 간의 유사성을 식별하기 위해 효율적으로 부분 문자열을 비교하는 Turnitin과 같은 표절 탐지 시스템에 사용됩니다. 자연어 처리에서는 반복 구문 식별, 키워드 추출 및 색인 구축과 같은 작업에 사용됩니다.
이러한 예시들은 생물 정보학에서 검색 엔진 및 데이터 압축에 이르기까지 다양한 분야에서 대규모 문자열 처리 작업을 처리하는 데 있어 접미사 배열의 다재다능성과 효율성을 강조합니다.
추가 읽기 및 고급 주제
접미사 배열에 대해 더 깊이 탐구하고자 하는 독자를 위해 여러 고급 주제와 자원이 있습니다. 중요한 분야 중 하나는 강화된 접미사 배열의 연구로, 이는 기본 구조에 가장 긴 공통 접두사(LCP) 배열과 같은 추가 데이터를 추가하여 더욱 효율적인 패턴 매칭 및 부분 문자열 쿼리를 가능하게 합니다. 접미사 배열과 접미사 트리 간의 상호 작용도 풍부한 분야입니다. 두 구조는 유사한 문제를 해결하지만 공간 및 구축 시간 측면에서 서로 다른 trade-offs를 가지고 있습니다.
최근 연구는 대규모 유전체 또는 텍스트 데이터를 처리하는 데 필수적인 선형 시간 구성 알고리즘인 SA-IS 및 DC3 (Skew) 알고리즘에 중점을 두었습니다. 이러한 알고리즘은 문헌에서 자세히 논의되고 있으며, 헬싱키 대학교 기능 접미사 배열 그룹의 기초 작업이 포함되어 있습니다.
접미사 배열의 응용은 문자열 매칭을 넘어 데이터 압축(예: 버로우스-휠러 변환), 생물정보학(유전체 조립 및 정렬) 및 정보 검색 분야로 확장됩니다. 포괄적인 개요를 원하신다면 Dan Gusfield의 Algorithms on Strings, Trees, and Sequences라는 책을 강력히 추천합니다.
- 접미사 배열: 온라인 문자열 검색을 위한 새로운 방법 (Manber & Myers의 원본 논문)
- 유도 정렬을 사용한 선형 시간 접미사 배열 구축 (SA-IS 알고리즘)
- Wikipedia: 접미사 배열 (개요 및 추가 링크)
출처 및 참고문헌
- American Mathematical Society
- Princeton University
- Department of Computer Science, University of Helsinki
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: 접미사 배열