サフィックス配列のマスター:効率的な文字列処理とパターンマッチングの究極ガイド。サフィックス配列がテキストアルゴリズムに革命をもたらす方法を発見してください。
- サフィックス配列の紹介
- サフィックス配列の仕組み:基本概念
- サフィックス配列の構築:ステップバイステップ
- サフィックス配列とサフィックスツリーの違い:主要な違い
- コンピュータサイエンスにおけるサフィックス配列の応用
- サフィックス配列による検索とパターンマッチングの最適化
- サフィックス配列を活用した一般的なアルゴリズム
- 性能の考慮事項と制限事項
- 実世界のユースケースと例
- さらなる読み物および高度なトピック
- 参考文献および出典
サフィックス配列の紹介
サフィックス配列は、主に効率的なパターンマッチング、部分文字列クエリ、およびテキストインデックス作成に使用される強力なデータ構造です。これは、与えられた文字列のすべてのサフィックスの順序をソートしたもので、通常は開始インデックスの配列として表現されます。この構造は、迅速な検索と大規模なテキストの分析が重要なバイオインフォマティクス、データ圧縮、および情報検索などの分野でさまざまな応用を可能にします。
サフィックス配列の概念は、サフィックスツリーへの空間効率の良い代替手段として導入され、類似の機能を提供しますが、メモリオーバーヘッドが削減されています。サフィックスツリーは実装や維持が複雑になりがちですが、サフィックス配列はよりシンプルでコンパクトであるため、大規模なテキスト処理タスクに適しています。サフィックス配列の構築は、文字列のすべての可能なサフィックスをソートすることに関わり、比較ベースのアルゴリズムを使用してO(n log n)時間で達成できます。あるいは、誘導ソーティング法などのより高度な手法を使用して線形時間で達成することも可能です (アメリカ数学会)。
サフィックス配列は、最長共通接頭辞 (LCP) 配列などの補助データ構造と組み合わせて使用されることが多く、最長繰り返し部分文字列を見つけたり、迅速な辞書順比較を行ったりするために非常に便利です。その効率性と多才さから、サフィックス配列は現代のアルゴリズム的文字列分析の基礎ツールとなっています (プリンストン大学)。
サフィックス配列の仕組み:基本概念
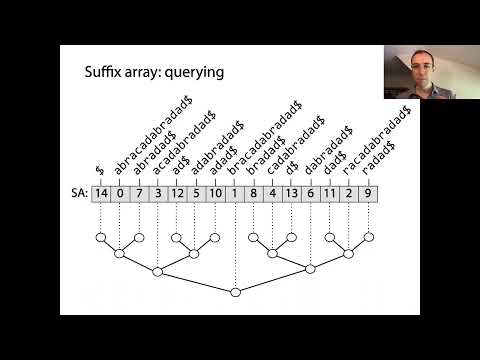
サフィックス配列は、効率的な文字列処理を可能にする強力なデータ構造であり、特にパターンマッチングやテキストインデックス作成に利用されます。サフィックス配列は、与えられた文字列のすべての可能なサフィックスのソートされた順序を表します。構築は、入力文字列のすべてのサフィックスを生成することから始まり、各サフィックスは異なる位置から始まります。これらのサフィックスは辞書順にソートされ、サフィックス配列自体は整数の配列で、各エントリはこのソートされた順序の中でのサフィックスの開始インデックスを示しています。
サフィックス配列の背後にある重要な概念は、すべてのサフィックスをソートすることによって、元のテキスト内で部分文字列やパターンを迅速に見つけるためのバイナリ検索を実行できるということです。これは、各クエリのためにテキスト全体をスキャンする必要があるかもしれないナイーブな検索方法に比べて大きな改善です。サフィックス配列は、通常、サフィックス配列の中で隣接するサフィックス間の最長共通接頭辞の長さを保存するLCP配列とペアにされ、さまざまな文字列操作を加速します。たとえば、繰り返し部分文字列の発見や異なる部分文字列の数を見つけるなどです。
誘導ソート法や接頭辞倍増法などの効率的な構築アルゴリズムにより、サフィックス配列の構築時間の計算量が線形またはほぼ線形に削減され、多くの大規模なアプリケーションに対して実用的です。サフィックス配列は、迅速かつメモリ効率の良い文字列処理が必須なバイオインフォマティクス、データ圧縮、情報検索の幅広い分野で広く使用されています。基礎原則やアルゴリズムについての包括的な概要については、ヘルシンキ大学コンピュータサイエンス学部のドキュメントを参照してください。
サフィックス配列の構築:ステップバイステップ
サフィックス配列の構築には、与えられた文字列のすべてのサフィックスのソートされた配列を作成し、その開始インデックスで表現することが含まれます。プロセスは、いくつかの主要なステップに分けることができます:
- 1. すべてのサフィックスを生成する:長さがnの文字列について、開始位置に基づいてすべてのサフィックスを列挙します。例えば、文字列「banana」は、インデックス0(「banana」)、1(「anana」)、2(「nana」)などで始まるサフィックスを生成します。
- 2. サフィックスをソートする:これらのサフィックスを辞書順にソートします。これは、文字列を直接比較するナイーブな方法でO(n2 log n)の時間で実行できますが、より効率的なアルゴリズムも存在します。
- 3. インデックスを保存する:実際のサフィックス文字列を保存する代わりに、ソートされた順序でその開始インデックスを保存します。このインデックスの配列がサフィックス配列です。
- 4. 最適化:Manber-Myersアルゴリズムなどの高度なアルゴリズムは、倍増法を使用してO(n log n)の時間計算量を達成します。さらに高速で、Karkkainen-Sandersアルゴリズム(Skewアルゴリズムとも呼ばれる)は、整数のアルファベットに対してO(n)の線形時間でサフィックス配列を構築できます。これらの手法は、ランクによるソートと再帰的な戦略に依存し、直接の文字列比較を避けることができます 計算機科学協会。
- 5. 最終出力:結果として得られるサフィックス配列は、効率的なパターンマッチングや部分文字列クエリを可能にし、LCP配列などの他のデータ構造を構築するための基礎となります GeeksforGeeks。
各ステップと利用可能な最適化を理解することは、大規模な文字列処理アプリケーションにおけるサフィックス配列の活用に不可欠です。
サフィックス配列とサフィックスツリーの違い:主要な違い
サフィックス配列とサフィックスツリーは、効率的な文字列処理のための基本的なデータ構造であり、特にパターンマッチング、バイオインフォマティクス、データ圧縮などのアプリケーションで使用されます。彼らは類似の目的を果たしますが、その構造、メモリ要件、および操作特性は大きく異なります。
サフィックスツリーは、与えられた文字列のすべてのサフィックスの圧縮トライであり、通常はパターンの長さに対して線形時間で非常に迅速な部分文字列クエリを可能にします。しかし、サフィックスツリーは実装が複雑で、ノードベースの構造とポインタやエッジラベルを保存する必要があるため、コストがかかります。これにより、非常に大規模なデータセットやメモリ制約のある環境では実用的ではありません。
対照的に、サフィックス配列は、はるかにシンプルでスペース効率の良いデータ構造です。これは、文字列のすべてのソートされたサフィックスの開始位置を表す整数の配列で構成されています。サフィックス配列は線形時間で構築でき、文字列の長さnに対してわずかO(n)のスペースしか必要としません。サフィックス配列を使用した部分文字列の検索は、サフィックスツリーに比べて通常は遅く(パターンの長さmに対してO(m log n)の計算量)、共同データ構造のようなLCP配列を使うことでO(m)に改善することができます。サフィックス配列のシンプルさと低メモリフットプリントは、大規模なテキストインデックスや検索タスクにおいて好まれる理由です。
詳細な比較やさらなる読み物については、計算機科学協会およびGeeksforGeeksをご覧ください。
コンピュータサイエンスにおけるサフィックス配列の応用
サフィックス配列は、特に文字列処理、バイオインフォマティクス、情報検索の分野でコンピュータサイエンスの基本的なデータ構造となっています。主な利用は、効率的なパターンマッチングおよび部分文字列クエリを可能にすることです。たとえば、サフィックス配列はフルテキスト検索エンジンで広く使用されており、大規模なテキストコーパス内のクエリ部分文字列のすべての出現を迅速に特定することを可能にしています。これは、辞書順にソートされたサフィックスの順序を活用することによって達成され、パターンマッチングのためのバイナリ検索操作をO(log n)の時間計算量でサポートします プリンストン大学。
バイオインフォマティクスでは、サフィックス配列がDNAおよびタンパク質配列の整列および比較を容易にします。次世代シーケンシングで使用されるゲノムアセンブリおよび配列アライメントツールは、しばしば巨大な生物学的データセットを効率的に扱うためにサフィックス配列に依存しています 国立生物工学情報センター。さらに、サフィックス配列は、bzip2などの人気のある圧縮ツールの基盤となるバロウズ-ウィーラー変換のようなデータ圧縮アルゴリズムにも不可欠です。ここで、サフィックス配列は、データを圧縮しやすい形に変換するために、類似の文字をまとめて配置します。
これらに加えて、サフィックス配列は盗作検出、データ重複排除、および最長共通接頭辞(LCP)クエリのための効率的なデータ構造の構築にも使用されます。その多才さと効率性は、迅速かつスケーラブルな文字列処理が要求されるアプリケーションでは欠かせないものとなります。
サフィックス配列による検索とパターンマッチングの最適化
サフィックス配列は、文字列内の検索およびパターンマッチング操作を大幅に最適化する強力なデータ構造です。テキストのすべてのサフィックスの開始インデックスを辞書順に保存することで、サフィックス配列は効率的な部分文字列クエリを可能にします。これはフルテキスト検索、バイオインフォマティクス、データ圧縮などのアプリケーションで重要です。サフィックス配列をナイーブな検索方法と比較した場合の主な利点は、パターンマッチングの時間計算量を削減できることです。力任せのアプローチでは、長さnのテキストと長さmのパターンに対してO(nm)時間が必要ですが、サフィックス配列を使用することで、ソートされたサフィックス上でのバイナリ検索を活用し、O(m + log n)の時間でパターン検索が可能になります。
パフォーマンスをさらに向上させるために、サフィックス配列は最長共通接頭辞(LCP)配列などの補助データ構造とともに使用されることが多いです。LCP配列は、サフィックス配列内の隣接するサフィックス間の最長共通接頭辞の長さを保存し、部分文字列の数や最長の繰り返し部分文字列を線形時間で見つけるなどのタスクをさらに迅速にすることができます。さらに、誘導ソート法などのサフィックス配列の構築に関する現代のアルゴリズムは、線形時間計算量を達成し、大規模なテキストへの実用的な解決策を提供します (ヘルシンキ大学)。
サフィックス配列は、サフィックスツリーと比較してもスペース効率が良く、O(n)のスペースしか必要とせず、実装が容易です。その効率性と多才さは、迅速かつスケーラブルなテキストインデックスおよびパターンマッチングシステムの設計において基盤となっています (プリンストン大学)。
サフィックス配列を活用した一般的なアルゴリズム
サフィックス配列は、文字列処理における基本的なデータ構造であり、さまざまな複雑な問題に対する効率的な解決策を提供します。いくつかの一般的なアルゴリズムは、パターンマッチング、データ圧縮、バイオインフォマティクスの分野で最適またはほぼ最適なパフォーマンスを達成するためにサフィックス配列を活用します。
最も有名な応用の1つは、部分文字列検索です。サフィックス配列とバイナリ検索を組み合わせることで、テキスト内のパターンのすべての出現をO(m log n)の時間で見つけることができます。ここでmはパターンの長さ、nはテキストの長さです。このアプローチは、特に大規模なテキストに対してはナイーブな検索方法よりも大幅に高速です。さらに、最長共通接頭辞(LCP)配列は、繰り返されるパターンクエリを最適化し、複数の文字列間の最長繰り返し部分文字列や最長共通部分文字列を見つけるためのアルゴリズムを支援するために、しばしばサフィックス配列と同時に構築されます。
サフィックス配列は、データ圧縮アルゴリズムにも不可欠です。たとえば、バロウズ-ウィーラー変換(BWT)は、bzip2圧縮ツールの重要な要素であり、入力テキストを再配置するためにサフィックスのソート順を利用します。これにより、ランレングスエンコーディングや他の圧縮手法をより良く行うことができます(bzip2)。
バイオインフォマティクスにおいて、サフィックス配列は効率的な配列整列およびゲノム解析で使用されており、DNAシーケンスの迅速な検索と比較が不可欠となります (国立生物工学情報センター)。そのスペースの効率性と速度により、大規模なアプリケーションにおいてはサフィックスツリーに代わって好まれることが多いです。
性能の考慮事項と制限事項
サフィックス配列は、部分文字列検索、パターンマッチング、最長共通接頭辞の計算など、さまざまな文字列処理問題を解決するための非常に効率的なデータ構造です。しかしながら、その性能と適用性は、いくつかの考慮事項と固有の制約によって影響を受けます。
主な性能要因の1つは、構築時間です。サフィックス配列を構築するためのナイーブなアルゴリズムはO(n log2 n)で動作しますが、より高度なアルゴリズムは線形時間計算量を達成します(たとえば、SA-ISアルゴリズム)。それでも、これらの最適アルゴリズムは実装が複雑であったり、重要な定数因子を持つこともあるため、特に非常に大規模なテキストやメモリ制約のある環境では実際の性能に影響を及ぼすことがあります。また、スペースの計算量も重要な側面です;サフィックス配列は通常O(n)のスペースを必要としますが、最長共通接頭辞(LCP)配列や追加のインデックス構造などの補助構造は、メモリ使用量をさらに増加させる可能性があります ヘルシンキ大学。
サフィックス配列は、テキスト内での挿入や削除などの動的な更新に関してサフィックスツリーよりも柔軟性がありません。構築後にサフィックス配列を変更することは容易ではなく、構造全体を再構築する必要がある場合が多いので、基礎となるテキストが頻繁に変化するアプリケーションには不向きです カーネギーメロン大学。さらに、サフィックス配列はサフィックスツリーよりもメモリ効率が良いですが、非常に大規模なデータセット(たとえば、全ゲノム配列)には、さらなる圧縮や外部メモリ技術が必要になる場合があります 国立生物工学情報センター。
要するに、サフィックス配列は静的テキストに対する速度とメモリ効率の面で重要な利点を提供しますが、動的シナリオや大規模なアプリケーションにおける限界は、システム設計の際に慎重に考慮する必要があります。
実世界のユースケースと例
サフィックス配列は、効率的な文字列処理やパターンマッチングが求められるさまざまな実世界のアプリケーションで広く使用されています。最も顕著なユースケースの1つはバイオインフォマティクス、特にゲノムシーケンシングと分析です。バロウズ-ウィーラーアライナのようなツールは、サフィックス配列を利用して短いDNAリードを参照ゲノムと迅速にアラインし、大規模なゲノム研究や個別化医療を可能にしています。
情報検索において、サフィックス配列は高速なフルテキスト検索エンジンの実装に不可欠です。たとえば、Apache Luceneプロジェクトは、サフィックス配列や関連データ構造を活用して、テキストコーパスのインデックス作成およびクエリに必要な効率的な部分文字列検索機能を提供します。
サフィックス配列は、データ圧縮アルゴリズムにも重要な役割を果たしています。たとえば、bzip2圧縮ツールは、入力データを再規則化し圧縮を改善するためにサフィックス配列を利用します。
また、サフィックス配列は、文書間の類似性を特定するために部分文字列を効率的に比較する盗作検出システム(たとえば、Turnitin)で使用されます。自然言語処理では、繰り返しフレーズの特定、キーワードの抽出、およびココードの作成などのタスクでも使用されます。
これらの例は、計算生物学から検索エンジン、データ圧縮まで、多様な分野にわたる大規模な文字列処理タスクにおけるサフィックス配列の柔軟性と効率性を強調しています。
さらなる読み物および高度なトピック
サフィックス配列についてさらに深く掘り下げたい読者のために、いくつかの高度なトピックとリソースが利用可能です。重要な領域の1つは、基本構造を最長共通接頭辞(LCP)配列などの追加データで強化する拡張サフィックス配列の研究です。これにより、パターンマッチングや部分文字列クエリをさらに効率的に実行できます。サフィックス配列とサフィックスツリーとの相互作用も豊富な分野であり、どちらの構造も類似の問題を解決しますが、空間と構築時間の観点で異なるトレードオフがあります。
最近の研究は、サフィックス配列の線形時間構築アルゴリズムに焦点を当てており、これは大規模なゲノムまたはテキストデータを扱うために重要です。これらのアルゴリズムは、ヘルシンキ大学の機能的サフィックス配列グループによる基礎的な作業など、文献で詳細に議論されています。
サフィックス配列の応用は、文字列マッチングだけでなく、データ圧縮(バロウズ-ウィーラー変換など)、バイオインフォマティクス(ゲノムアセンブリおよびアライメント)、情報検索の領域にも拡がっています。包括的な概要については、ダン・ガスフィールドによる書籍「文字列、木、配列に関するアルゴリズム」を強くお勧めします。
- サフィックス配列:オンライン文字列検索の新しい方法(マウンバー&マイヤーズによる原論文)
- 誘導ソートを使用した線形時間のサフィックス配列構築(SA-ISアルゴリズム)
- ウィキペディア:サフィックス配列(概要およびさらなるリンク)
参考文献および出典
- アメリカ数学会
- プリンストン大学
- ヘルシンキ大学コンピュータサイエンス学部
- GeeksforGeeks
- 国立生物工学情報センター
- カーネギーメロン大学
- Apache Lucene
- Turnitin
- 文字列、木、配列に関するアルゴリズム
- ウィキペディア:サフィックス配列