Padroneggiare gli Array di Suffissi: La Guida Definitiva per un Elaborazione Efficiente delle Stringhe e il Matching dei Pattern. Scopri Come gli Array di Suffissi Rivoluzionano gli Algoritmi Testuali.
- Introduzione agli Array di Suffissi
- Come Funzionano gli Array di Suffissi: Concetti Base
- Costruire un Array di Suffissi: Passaggio Dopo Passaggio
- Array di Suffissi vs. Alberi di Suffissi: Differenze Fondamentali
- Applicazioni degli Array di Suffissi in Informatica
- Ottimizzazione della Ricerca e del Matching dei Pattern con gli Array di Suffissi
- Algoritmi Comuni che Sfruttano gli Array di Suffissi
- Considerazioni sulle Prestazioni e Limitazioni
- Casi d’Uso Real-i ed Esempi
- Ulteriori Letture e Argomenti Avanzati
- Fonti & Riferimenti
Introduzione agli Array di Suffissi
Un array di suffissi è una potente struttura dati utilizzata nell’elaborazione delle stringhe, particolarmente per il matching dei pattern efficiente, le query di sottostringa e l’indicizzazione testuale. Rappresenta l’ordine ordinato di tutti i suffissi di una stringa data, tipicamente come un array di indici di partenza. Questa struttura consente una varietà di applicazioni in campi come la bioinformatica, la compressione dei dati e il recupero delle informazioni, dove una rapida ricerca e analisi di grandi testi sono essenziali.
Il concetto di array di suffissi è stato introdotto come un’alternativa efficiente in termini di spazio all’albero dei suffissi, offrendo funzionalità simili ma con una minore sovraccarico di memoria. A differenza degli alberi di suffissi, che possono essere complessi da implementare e mantenere, gli array di suffissi sono più semplici e compatti, rendendoli adatti per compiti di elaborazione di testi su larga scala. La costruzione di un array di suffissi implica l’ordinamento di tutti i possibili suffissi di una stringa, che può essere ottenuto in O(n log n) tempo utilizzando algoritmi basati su confronto, o persino in tempo lineare con tecniche più avanzate come il metodo di ordinamento indotto (American Mathematical Society).
Gli array di suffissi sono spesso utilizzati in combinazione con strutture dati ausiliarie come l’array del LCP (Longest Common Prefix), che ne migliora ulteriormente l’utilità per risolvere problemi come trovare la sottostringa ripetuta più lunga o eseguire confronti lessicografici rapidi. La loro efficienza e versatilità hanno reso gli array di suffissi uno strumento fondamentale nell’analisi moderna delle stringhe algoritmiche (Princeton University).
Come Funzionano gli Array di Suffissi: Concetti Base
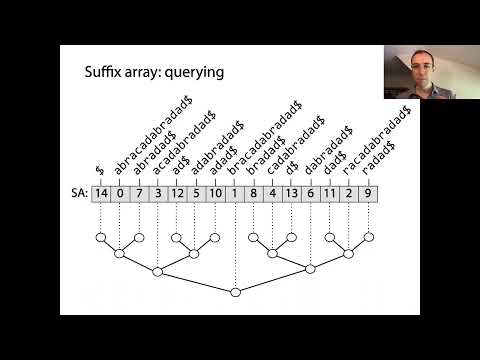
Gli array di suffissi sono potenti strutture dati che consentono un’elaborazione efficiente delle stringhe, in particolare per il matching dei pattern e l’indicizzazione testuale. Alla base, gli array di suffissi rappresentano l’ordine ordinato di tutti i possibili suffissi di una stringa data. La costruzione inizia generando ogni suffisso della stringa di input, ognuno che inizia in una posizione diversa. Questi suffissi vengono poi ordinati lessicograficamente e l’array di suffissi stesso è un array di interi, in cui ciascuna voce indica l’indice di partenza di un suffisso in questo ordine ordinato.
Il concetto chiave dietro gli array di suffissi è che, ordinando tutti i suffissi, è possibile eseguire ricerche binarie rapide per localizzare sottostringhe o pattern all’interno del testo originale. Questo rappresenta un miglioramento significativo rispetto ai metodi di ricerca naivi, che potrebbero richiedere di scandire l’intero testo per ogni query. Gli array di suffissi sono spesso associati all’array del LCP, che memorizza le lunghezze dei prefissi comuni più lunghi tra i suffissi consecutivi nell’array ordinato. Questa associazione accelera ulteriormente varie operazioni sulle stringhe, come trovare sottostringhe ripetute o il numero di sottostringhe distinte.
Algoritmi di costruzione efficienti, come il metodo di ordinamento indotto o l’uso del raddoppio dei prefissi, hanno ridotto la complessità temporale di costruzione degli array di suffissi a tempo lineare o quasi lineare, rendendoli praticabili per applicazioni su larga scala. Gli array di suffissi sono ampiamente utilizzati nella bioinformatica, nella compressione dei dati e nel recupero delle informazioni, dove un’elaborazione delle stringhe rapida e a bassa memoria è essenziale. Per una panoramica completa dei principi sottostanti e degli algoritmi, fare riferimento alla documentazione della Facoltà di Informatica, Università di Helsinki.
Costruire un Array di Suffissi: Passaggio Dopo Passaggio
Costruire un array di suffissi implica la costruzione di un array ordinato di tutti i suffissi di una stringa data, rappresentati dai loro indici di partenza. Il processo può essere suddiviso in diversi passaggi chiave:
- 1. Genera Tutti i Suffissi: Per una stringa di lunghezza n, enumera tutti i suffissi per le loro posizioni di partenza. Ad esempio, la stringa “banana” produce suffissi che partono agli indici 0 (“banana”), 1 (“anana”), 2 (“nana”), e così via.
- 2. Ordina i Suffissi: Ordina questi suffissi lessicograficamente. Questo può essere fatto in modo naif in O(n2 log n) tempo confrontando direttamente le stringhe, ma esistono algoritmi più efficienti.
- 3. Memorizza gli Indici: Invece di memorizzare le effettive stringhe dei suffissi, memorizza i loro indici di partenza nell’ordine ordinato. Questo array di indici è l’array di suffissi.
- 4. Ottimizzazione: Algoritmi avanzati, come l’algoritmo Manber-Myers, usano una tecnica di raddoppio per raggiungere una complessità temporale di O(n log n). Ancora più veloce, l’algoritmo Karkkainen-Sanders (noto anche come algoritmo Skew) può costruire l’array di suffissi in tempo lineare O(n) per alfabeti interi. Questi metodi si basano sull’ordinamento per gradi e strategie ricorsive per evitare confronti diretti delle stringhe Association for Computing Machinery.
- 5. Output Finale: L’array di suffissi risultante consente un matching efficiente dei pattern, query di sottostringa, ed è fondamentale per costruire altre strutture dati come l’array del LCP GeeksforGeeks.
Comprendere ogni passaggio e le ottimizzazioni disponibili è cruciale per sfruttare gli array di suffissi in applicazioni di elaborazione delle stringhe su larga scala.
Array di Suffissi vs. Alberi di Suffissi: Differenze Fondamentali
Gli array di suffissi e gli alberi di suffissi sono entrambe strutture dati fondamentali per un’elaborazione efficiente delle stringhe, in particolare in applicazioni come il matching dei pattern, la bioinformatica e la compressione dei dati. Sebbene servano scopi simili, le loro strutture, requisiti di memoria e caratteristiche operative differiscono notevolmente.
Un albero di suffissi è un trie compresso di tutti i suffissi di una stringa data, che consente query di sottostringa estremamente rapide, tipicamente in tempo lineare rispetto alla lunghezza del pattern. Tuttavia, gli alberi di suffissi sono complessi da implementare e richiedono un notevole sovraccarico di memoria, spesso diverse volte le dimensioni della stringa originale, a causa della loro struttura basata sui nodi e della necessità di memorizzare puntatori e etichette di bordo. Questo li rende meno pratici per set di dati molto grandi o in ambienti a memoria limitata.
Al contrario, un array di suffissi è una struttura dati molto più semplice e più efficiente in termini di spazio. Consiste in un array di interi che rappresentano le posizioni di partenza di tutti i suffissi ordinati della stringa. Gli array di suffissi possono essere costruiti in tempo lineare e richiedono solo O(n) spazio, dove n è la lunghezza della stringa. Sebbene le ricerche di sottostringhe utilizzando un array di suffissi siano tipicamente più lente rispetto a un albero di suffissi (O(m log n) per un pattern di lunghezza m), questo può essere migliorato a O(m) con strutture dati ausiliarie come l’array del LCP. La semplicità e il minore impatto sulla memoria degli array di suffissi li rendono preferibili per compiti di indicizzazione e ricerca testuale su larga scala.
Per un confronto dettagliato e ulteriori letture, vedere Association for Computing Machinery e GeeksforGeeks.
Applicazioni degli Array di Suffissi in Informatica
Gli array di suffissi sono diventati una struttura dati fondamentale in informatica, in particolare nei campi dell’elaborazione delle stringhe, della bioinformatica e del recupero delle informazioni. La loro principale utilità risiede nel consentire un matching efficiente dei pattern e query di sottostringa. Ad esempio, gli array di suffissi sono ampiamente utilizzati nei motori di ricerca full-text, dove consentono l’identificazione rapida di tutte le occorrenze di una sottostringa di query all’interno di un ampio corpus testuale. Ciò è ottenuto sfruttando l’ordine ordinato lessicograficamente dei suffissi, che supporta operazioni di ricerca binaria per il matching dei pattern con complessità temporale logaritmica Princeton University.
Nella bioinformatica, gli array di suffissi facilitano l’allineamento e il confronto di sequenze di DNA e proteine. Gli strumenti per l’assemblaggio dei genomi e l’allineamento delle sequenze, come quelli utilizzati nel sequenziamento di nuova generazione, si basano spesso sugli array di suffissi per gestire in modo efficiente enormi dataset biologici National Center for Biotechnology Information. Inoltre, gli array di suffissi sono integrali per gli algoritmi di compressione dei dati come la Trasformazione di Burrows-Wheeler, che sta dietro a strumenti di compressione popolari come bzip2. Qui, l’array di suffissi consente la trasformazione dei dati di input in una forma più adatta alla compressione raggruppando insieme caratteri simili bzip2.
Oltre a questi, gli array di suffissi sono utilizzati anche in sistemi di rilevamento del plagio, deduplicazione dei dati e nella costruzione di strutture dati efficienti per le query del prefisso comune più lungo (LCP). La loro versatilità e efficienza li rendono indispensabili in applicazioni in cui è necessaria un’elaborazione delle stringhe rapida e scalabile.
Ottimizzazione della Ricerca e del Matching dei Pattern con gli Array di Suffissi
Gli array di suffissi sono potenti strutture dati che ottimizzano significativamente le operazioni di ricerca e matching dei pattern nelle stringhe. Memorizzando gli indici di partenza di tutti i suffissi di un testo in ordine lessicografico, gli array di suffissi consentono query di sottostringa efficienti, fondamentali in applicazioni come la ricerca full-text, la bioinformatica e la compressione dei dati. Il principale vantaggio dell’utilizzo di un array di suffissi rispetto ai metodi di ricerca naivi è la riduzione della complessità temporale per il matching dei pattern. Mentre un approccio brutale potrebbe richiedere O(nm) tempo per un testo di lunghezza n e un pattern di lunghezza m, gli array di suffissi consentono le ricerche di pattern in O(m + log n) tempo sfruttando la ricerca binaria sui suffissi ordinati.
Per ulteriormente migliorare le prestazioni, gli array di suffissi sono spesso utilizzati in combinazione con strutture dati ausiliarie come l’array del LCP (Longest Common Prefix). L’array del LCP memorizza le lunghezze dei prefissi comuni più lunghi tra i suffissi consecutivi nell’array di suffissi, consentendo un matching dei pattern ancora più veloce e facilitando compiti come trovare il numero di sottostringhe distinte o la sottostringa ripetuta più lunga in tempo lineare. Inoltre, gli algoritmi moderni per la costruzione di array di suffissi, come il metodo di ordinamento indotto, raggiungono la complessità temporale lineare, rendendoli praticabili per testi su larga scala (Università di Helsinki).
Gli array di suffissi sono anche efficienti in termini di spazio rispetto agli alberi di suffissi, poiché richiedono solo O(n) spazio e sono più facili da implementare. La loro efficienza e versatilità li rendono una pietra miliare nella progettazione di sistemi di indicizzazione testuale rapidi e scalabili e nel matching dei pattern (Princeton University).
Algoritmi Comuni che Sfruttano gli Array di Suffissi
Gli array di suffissi sono una struttura dati fondamentale nell’elaborazione delle stringhe, che consente soluzioni efficienti a una varietà di problemi complessi. Diversi algoritmi comuni sfruttano gli array di suffissi per ottenere prestazioni ottimali o quasi ottimali, in particolare nei settori del matching dei pattern, della compressione dei dati e della bioinformatica.
Una delle applicazioni più significative è nella ricerca di sottostringhe. Combinando un array di suffissi con una ricerca binaria, è possibile localizzare tutte le occorrenze di un pattern in un testo in O(m log n) tempo, dove m è la lunghezza del pattern e n è la lunghezza del testo. Questo approccio è notevolmente più veloce rispetto ai metodi di ricerca naivi, soprattutto per testi di grandi dimensioni. Inoltre, l’array del prefisso comune più lungo (LCP) è spesso costruito insieme all’array di suffissi per ottimizzare ulteriormente le query sui pattern ripetuti e per facilitare algoritmi per trovare la sottostringa ripetuta più lunga o la sottostringa comune più lunga tra più stringhe.
Gli array di suffissi sono anche parte integrante degli algoritmi di compressione dei dati come la Trasformazione di Burrows-Wheeler (BWT), che è un componente chiave dello strumento di compressione bzip2. La BWT si basa sull’ordine ordinato dei suffissi per riordinare il testo di input, rendendolo più adatto all’encoding per run-length e ad altre tecniche di compressione (bzip2).
Nella bioinformatica, gli array di suffissi sono utilizzati per un allineamento delle sequenze efficiente e l’analisi dei genomi, dove la ricerca rapida e il confronto delle sequenze di DNA sono essenziali (National Center for Biotechnology Information). La loro efficienza in termini di spazio e velocità li rende preferibili agli alberi di suffissi in molte applicazioni su larga scala.
Considerazioni sulle Prestazioni e Limitazioni
Gli array di suffissi sono strutture dati altamente efficienti per risolvere una varietà di problemi di elaborazione delle stringhe, come la ricerca di sottostringhe, il matching dei pattern e il calcolo del prefisso comune più lungo. Tuttavia, le loro prestazioni e applicabilità sono influenzate da diverse considerazioni e limitazioni intrinseche.
Uno dei principali fattori di prestazione è il tempo di costruzione. Mentre gli algoritmi naivi per costruire array di suffissi operano in O(n log2 n) tempo, algoritmi più avanzati raggiungono una complessità temporale lineare, come l’algoritmo SA-IS. Tuttavia, questi algoritmi ottimali possono essere complessi da implementare e possono avere fattori costanti significativi, che possono influenzare le prestazioni pratiche, specialmente per testi molto grandi o in ambienti a memoria limitata. La complessità di spazio è un altro aspetto importante; un array di suffissi richiede tipicamente O(n) spazio, ma le strutture ausiliarie come l’array del prefisso comune più lungo (LCP) o ulteriori strutture di indicizzazione possono aumentare ulteriormente l’utilizzo della memoria Università di Helsinki.
Gli array di suffissi sono meno flessibili degli alberi di suffissi quando si tratta di aggiornamenti dinamici, come inserimenti o cancellazioni all’interno del testo. Modificare un array di suffissi dopo la sua costruzione non è banale e richiede spesso di ricostruire l’intera struttura, rendendolo meno adatto per applicazioni in cui il testo sottostante cambia frequentemente Carnegie Mellon University. Inoltre, sebbene gli array di suffissi siano più efficienti in termini di spazio rispetto agli alberi di suffissi, potrebbero comunque essere impraticabili per dataset estremamente grandi, come intere sequenze genomiche, senza ulteriori tecniche di compressione o di memoria esterna National Center for Biotechnology Information.
In sintesi, mentre gli array di suffissi offrono vantaggi significativi in termini di velocità ed efficienza di memoria per testi statici, le loro limitazioni in scenari dinamici e in applicazioni su larga scala devono essere attentamente considerate durante la progettazione del sistema.
Casi d’Uso Real-i ed Esempi
Gli array di suffissi sono ampiamente utilizzati in vari casi d’uso reali che richiedono un’elaborazione efficiente delle stringhe e il matching dei pattern. Uno dei casi d’uso più significativi è nella bioinformatica, in particolare nel sequenziamento e nell’analisi del genoma. Strumenti come il Burrows-Wheeler Aligner utilizzano array di suffissi per allineare rapidamente brevi letture di DNA ai genomi di riferimento, consentendo studi genomici su larga scala e medicina personalizzata.
Nel recupero delle informazioni, gli array di suffissi sono fondamentali per implementare motori di ricerca full-text rapidi. Ad esempio, il progetto Apache Lucene sfrutta gli array di suffissi e strutture dati correlate per fornire capacità efficienti di ricerca di sottostringhe, essenziali per indicizzare e interrogare ampi corpora testuali.
Gli array di suffissi giocano anche un ruolo cruciale negli algoritmi di compressione dei dati. Lo strumento di compressione bzip2, ad esempio, utilizza la Trasformazione di Burrows-Wheeler, che si basa sulla costruzione di un array di suffissi per riordinare i dati di input e migliorare la compressibilità.
Inoltre, gli array di suffissi sono impiegati in sistemi di rilevamento del plagio, come Turnitin, per identificare similarità tra documenti confrontando efficientemente sottostringhe. Nel processamento del linguaggio naturale, sono utilizzati per compiti come l’identificazione di frasi ripetute, l’estrazione di parole chiave e la costruzione di concordanze.
Questi esempi evidenziano la versatilità e l’efficienza degli array di suffissi nella gestione di compiti di elaborazione delle stringhe su larga scala in diversi domini, dalla biologia computazionale ai motori di ricerca e alla compressione dei dati.
Ulteriori Letture e Argomenti Avanzati
Per i lettori interessati a esplorare più a fondo gli array di suffissi, sono disponibili diversi argomenti avanzati e risorse. Un’area significativa è lo studio degli array di suffissi potenziati, che aumentano la struttura di base con dati aggiuntivi come l’array del LCP (Longest Common Prefix), consentendo matching dei pattern e query di sottostringa più efficienti. L’interazione tra gli array di suffissi e gli alberi di suffissi è anche un campo ricco, poiché entrambe le strutture risolvono problemi simili ma con diversi compromessi in termini di spazio e tempo di costruzione.
Recenti ricerche si sono concentrate su algoritmi di costruzione in tempo lineare per gli array di suffissi, come gli algoritmi SA-IS e DC3 (Skew), che sono cruciali per gestire dati genomici o testuali su larga scala. Questi algoritmi sono discussi in dettaglio nella letteratura, incluso il lavoro fondamentale del Gruppo degli Array di Suffissi Funzionali, Università di Helsinki.
Le applicazioni degli array di suffissi si estendono oltre il matching delle stringhe a settori come la compressione dei dati (ad es., la Trasformazione di Burrows-Wheeler), la bioinformatica (assemblaggio e allineamento del genoma) e il recupero delle informazioni. Per una panoramica completa, il libro Algoritmi su Stringhe, Alberi e Sequenze di Dan Gusfield è altamente raccomandato.
- Array di Suffissi: Un Nuovo Metodo per le Ricerche di Stringhe Online (articolo originale di Manber & Myers)
- Costruzione di Array di Suffissi in Tempo Lineare Usando Ordinamento Indotto (algoritmo SA-IS)
- Wikipedia: Array di Suffissi (panoramica e ulteriori link)
Fonti & Riferimenti
- American Mathematical Society
- Princeton University
- Department of Computer Science, University of Helsinki
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Suffix Array