A suffix tömbök mesterfokon: A végső útmutató a hatékony szövegfeldolgozás és mintaillesztés területén. Fedezze fel, hogyan forradalmasítják a suffix tömbök a szövegalgoritmusokat.
- Bevezetés a suffix tömbökbe
- Hogyan működnek a suffix tömbök: Alapfogalmak
- Suffix tömb építése: Lépésről lépésre
- Suffix tömbök vs. Suffix fáknak: Kulcsfontosságú különbségek
- A suffix tömbök alkalmazásai a számítástechnikában
- A keresés és mintakeresés optimalizálása suffix tömbökkel
- Gyakori algoritmusok, amelyek a suffix tömböket használják
- Teljesítménybeli szempontok és korlátok
- Valós példák és esetek
- További olvasmányok és haladó témák
- Források és hivatkozások
Bevezetés a suffix tömbökbe
A suffix tömb egy hatékony adatstruktúra, amelyet szövegfeldolgozásra használnak, különösen a hatékony mintaillesztés, részszöveg-lekérdezések és szövegböngészés terén. Ez a struktúra a megadott szöveg összes suffixének rendezett sorrendjét reprezentálja, jellemzően kezdő indexek tömbjeként. Ez a struktúra különböző alkalmazásokat tesz lehetővé olyan területeken, mint a bioinformatika, az adatok tömörítése és az információkeresés, ahol a nagy szövegek gyors keresése és elemzése elengedhetetlen.
A suffix tömb fogalma egy térkímélő alternatívaként került bevezetésre a suffix fákkal szemben, hasonló funkciókat kínálva, de csökkentett memóriahasználattal. A suffix fákhoz képest, amelyek komplexek lehetnek a megvalósításban és karbantartásban, a suffix tömbök egyszerűbbek és kompaktabbak, így alkalmasabbak nagy léptékű szövegfeldolgozási feladatokhoz. A suffix tömb építése magában foglalja egy szöveg összes lehetséges suffixének rendezését, amely O(n log n) idő alatt megvalósítható összehasonlítás alapú algoritmusok segítségével, vagy még lineáris időben is a fejlettebb technikák, például az indukált rendezési módszer (American Mathematical Society) alkalmazásával.
A suffix tömböket gyakran használják kiegészítő adatstruktúrákkal, mint például a Leghosszabb Közös Prefix (LCP) tömb, amely tovább növeli hasznosságukat az olyan problémák megoldásában, mint a leghosszabb ismétlődő részszöveg megtalálása vagy a gyors lexikografikus összehasonlítások végrehajtása. Hatékonyságuk és sokoldalúságuk révén a suffix tömbök a modern algoritmikus szögelemzés alapvető eszközévé váltak (Princeton University).
Hogyan működnek a suffix tömbök: Alapfogalmak
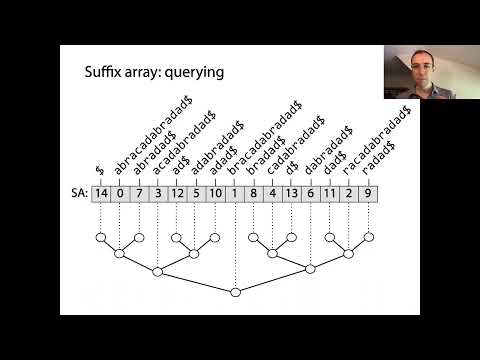
A suffix tömbök hatékony adatstruktúrák, amelyek lehetővé teszik a szövegfeldolgozás hatékonyságát, különösen a mintakeresés és a szövegböngészés terén. Lényegük, hogy a suffix tömbök a megadott szöveg összes lehetséges suffixének rendezett sorrendjét képviselik. Az építkezés azzal kezdődik, hogy a bemeneti szöveg minden suffixét generálják, mindegyik egy különböző pozícióból kezdve. Ezeket a suffixeket lexikográfiai sorrendben rendezik, és a suffix tömb magának egy egész számokból álló tömb, ahol minden bejegyzés egy suffix kezdő indexét jelzi ebben a rendezett sorrendben.
A suffix tömbök mögötti kulcsfontosságú koncepció az, hogy ha az összes suffixet rendezzük, gyors bináris kereséseket végezhetünk a részszövegek vagy minták megtalálására az eredeti szövegben. Ez jelentős javulást jelent a naiv keresési módszerekhez képest, amelyek esetleg az egész szöveget át kell nézniük minden lekérdezéshez. A suffix tömböket gyakran párosítják a Leghosszabb Közös Prefix (LCP) tömbbel, amely a rendezett tömbben egymást követő suffixek közötti leghosszabb közös prefixek hosszát tárolja. Ez a párosítás tovább gyorsítja a különböző szövegeműveleteket, például a részszövegek vagy a különböző részszövegek számának megtalálásában.
A hatékony építési algoritmusok, mint például az indukált rendezési módszer vagy a prefix duplázás alkalmazása, csökkentették a suffix tömbök építésének időbeli bonyolultságát lineáris vagy közel lineáris időre, így praktikussá váltak nagy léptékű alkalmazások számára. A suffix tömböket széles körben használják a bioinformatikában, az adatok tömörítésében és az információkeresésben, ahol a gyors és memóriahatékony szövegfeldolgozás elengedhetetlen. A mögöttes elvek és algoritmusok átfogó áttekintéséhez lásd a Helsinki Egyetem Számítástechnikai Tanszékének dokumentációját.
Suffix tömb építése: Lépésről lépésre
A suffix tömb építése magában foglalja a megadott szöveg összes suffixének rendezett tömbjének létrehozását, amelyeket a kezdő indexeik reprezentálnak. Ez a folyamat több kulcsfontosságú lépésre bontható:
- 1. Minden suffix generálása: Egy n hosszú szöveg esetén enumerálja a kezdő pozícióik alapján az összes suffixet. Például a „banana” szöveg a 0 indexnél kezdődő („banana”), 1 indexnél kezdődő („anana”), 2 indexnél kezdődő („nana”) suffixeket adja.
- 2. A suffixek rendezése: A suffixeket lexikográfiai sorrendben rendezze. Ezt naivan O(n2 log n) idő alatt lehet elvégezni közvetlenül a szövegek összehasonlításával, de léteznek hatékonyabb algoritmusok is.
- 3. Az indexek tárolása: A tényleges suffix szövegek tárolása helyett tárolja a kezdő indexeiket a rendezett sorrendben. Ez az indexek tömbje a suffix tömb.
- 4. Optimalizálás: Fejlettebb algoritmusok, mint a Manber-Myers algoritmus, duplázási technikát használnak, hogy O(n log n) időbeli bonyolultságot érjenek el. Még gyorsabb, a Karkkainen-Sanders algoritmus (más néven Skew algoritmus) lineáris időben O(n) képes felépíteni a suffix tömböt, ha az ábécé egész számokból áll. Ezek a módszerek rangsorok szerinti rendezésen és rekurzív stratégiákon alapulnak, elkerülve a közvetlen karakterek összehasonlítását Association for Computing Machinery.
- 5. Végső kimenet: Az így kapott suffix tömb lehetővé teszi a hatékony mintaillesztést, részszöveg-lekérdezéseket, és alapvető a többi adatstruktúra, például az LCP tömb építéséhez GeeksforGeeks.
A minden lépés és az elérhető optimalizálások megértése kulcsfontosságú a suffix tömbök kihasználásához nagy léptékű szövegfeldolgozási alkalmazásokban.
Suffix tömbök vs. Suffix fáknak: Kulcsfontosságú különbségek
A suffix tömbök és a suffix fák mindkettő alapvető adatstruktúrák a hatékony szövegfeldolgozás terén, különösen a mintaillesztés, bioinformatika és adatok tömörítése során. Bár hasonló célokat szolgálnak, struktúrájuk, memóriaigényük és működési jellemzőik jelentősen eltérnek.
A suffix fa egy tömörített trie az adott szöveg összes suffixéről, amely rendkívül gyors részszöveg-kereséseket tesz lehetővé, amelyek tipikusan lineáris időben végezhetők el a minta hosszához viszonyítva. A suffix fák azonban bonyolultak a megvalósításban, és jelentős memóriaigénnyel rendelkeznek – gyakran az eredeti szöveg méretének többszöröse – a csomópont-alapú struktúrájuk és a mutatók, valamint élek címkéinek tárolási szükséglete miatt. Ez kevésbé praktikus számukra nagyon nagy adathalmazon vagy memória-korlátozott környezetekben.
Ezzel szemben a suffix tömb egy sokkal egyszerűbb és térben hatékonyabb adatstruktúra. Egész számokból álló tömb, amely a rendezett suffixek kezdő pozícióit képviseli. A suffix tömbök lineáris időben felépíthetők és csak O(n) teret igényelnek, ahol n a szöveg hossza. Bár a suffix tömb használatával végzett részszöveg keresések általában lassabbak, mint a suffix fákkal (O(m log n) m hosszúságú minta esetén), ezt a Leghosszabb Közös Prefix (LCP) tömbhöz hasonló kiegészítő adatstruktúrákkal javítható O(m) időre. A suffix tömbök egyszerűsége és alacsony memóriaigénye miatt előnyösebbek nagy léptékű szövegindexelési és keresési feladatokhoz.
A részletes összehasonlításhoz és további olvasás érdemes megnézni az Association for Computing Machinery és a GeeksforGeeks anyagait.
A suffix tömbök alkalmazásai a számítástechnikában
A suffix tömbök alapvető adatstruktúrává váltak a számítástechnikában, különösen a szövegfeldolgozás, bioinformatika és információkeresés területén. Elsődleges hasznosságuk abban rejlik, hogy lehetővé teszik a hatékony mintaillesztést és részszöveg-kereséseket. Például a suffix tömbök széleskörűen alkalmazottak a teljes szöveg keresőmotorokban, ahol lehetővé teszik a lekérdezési részszöveg összes előfordulásának gyors azonosítását egy nagy szövegkorpuszon belül. Ez a lexikográfiai sorrendű suffixek kiaknázásával érhető el, amely támogatja a bináris keresési műveleteket a mintakereséshez logaritmikus időbeli bonyolultsággal Princeton University.
A bioinformatikában a suffix tömbök elősegítik a DNS és fehérjék összehangolását és összehasonlítását. A genom szekvenciák összeállításához és szekvenciaösszehangolásához használt eszközök, például a következő generációs szekvenálás, gyakran támaszkodnak a suffix tömbökre, hogy hatékonyan kezeljék a hatalmas biológiai adatállományokat National Center for Biotechnology Information. Ezenkívül a suffix tömbök alapvetőek az adat tömörítési algoritmusokban, mint például a Burrows-Wheeler Transform, amely a népszerű tömörítő eszközök, például a bzip2 alapját képezi. Itt a suffix tömb lehetővé teszi a bemeneti adatok átalakítását olyan formába, amely jobban alkalmas a tömörítésre azáltal, hogy egymáshoz hasonló karaktereket klaszterez.
Ezen túlmenően a suffix tömbök használatosak plagizálás-észlelési, adat-hasonlóság csökkentési és hatékony adatstruktúrák építésében a leghosszabb közös prefix (LCP) lekérdezésekhez. Sokoldalúságuk és hatékonyságuk elengedhetetlenné teszi őket azokban az alkalmazásokban, ahol gyors és méretezhető szövegfeldolgozásra van szükség.
A keresés és mintakeresés optimalizálása suffix tömbökkel
A suffix tömbök hatékony adatstruktúrák, amelyek jelentősen optimalizálják a keresési és mintaillesztési műveleteket a szövegekben. Az összes suffix kezdő indexének lexikográfiai sorrendben való tárolásával a suffix tömbök lehetővé teszik a hatékony részszöveg-kereséseket, amelyek alapvető fontosságúak olyan alkalmazásokban, mint a teljes szöveg keresés, bioinformatika és adat tömörítés. A suffix tömb használatának elsődleges előnye a naiv keresési módszerekhez képest a bonyolultság időbeli csökkentése a mintaillesztés során. Míg a brutális módszer egy n hosszúságú szöveg esetén és egy m hosszúságú minta esetén O(nm) időt igényel, a suffix tömb lehetővé teszi a minta keresést O(m + log n) idő alatt a rendezett suffixek bináris keresésének kihasználásával.
A teljesítmény tovább növelésére a suffix tömböket gyakran kiegészítő adatstruktúrákkal, például a Leghosszabb Közös Prefix (LCP) tömbbel együtt használják. Az LCP tömb eltárolja a rendezett tömbben egymást követő suffixek közötti leghosszabb közös prefixek hosszát, lehetővé téve ezzel még gyorsabb mintaillesztést és megkönnyítve olyan feladatokat, mint a különböző részszövegek számának vagy a leghosszabb ismétlődő részszöveg megtalálása lineáris időben. Továbbá, a modern algoritmusok a suffix tömbök építésére, mint például az indukált rendezési módszer, lineáris időbeli bonyolultságot érnek el, így praktikussá téve őket nagy léptékű szövegek számára (Helsinki Egyetem).
A suffix tömbök a suffix fákkal összehasonlítva térben is hatékonyak, mivel csupán O(n) teret igényelnek, és könnyebben implementálhatók. Hatékonyságuk és sokoldalúságuk alapkövetelmény a gyors és skálázható szövegindexelés és mintaillesztés rendszerek tervezésében (Princeton University).
Gyakori algoritmusok, amelyek a suffix tömböket használják
A suffix tömbök alapvető adatstruktúrák a szövegfeldolgozásban, amelyek lehetővé teszik a hatékony megoldásokat különböző bonyolult problémákra. Számos gyakori algoritmus használja a suffix tömböket, hogy optimális vagy közel optimális teljesítményt érjen el, különösen a mintaillesztés, adat tömörítés és bioinformatika területén.
Az egyik legprominensebb alkalmazás a részszöveg-keresés. A suffix tömb egyesítése bináris kereséssel lehetővé teszi, hogy minden előfordulását megtaláljuk egy mintának egy szövegben O(m log n) idő alatt, ahol m a minta hossza és n a szöveg hossza. Ez a megközelítés jelentősen gyorsabb a naiv keresési módszerekhez képest, különösen nagy szövegek esetén. Továbbá, a Leghosszabb Közös Prefix (LCP) tömb gyakran a suffix tömb mellett épül fel, hogy tovább optimalizálja az ismétlődő minták lekérdezéseit és megkönnyítse az algoritmusokat a leghosszabb ismétlődő részszöveg vagy a több szöveg közötti leghosszabb közös részszöveg megtalálásához.
A suffix tömbök szintén integrális részei a adat tömörítési algoritmusok-nak, mint például a Burrows-Wheeler Transform (BWT), amely a bzip2 tömörítő eszköz kulcseleme. A BWT a suffixek rendezett sorrendjét használja a bemeneti szöveg átrendezésére, így az jobban alkalmassá válik a futás nélküli kódolásra és egyéb tömörítési technikákra (bzip2).
A bioinformatikában a suffix tömbök hatékony szekvencia-összehangolásra és genom-analízisre használatosak, ahol a DNS szekvenciák gyors keresése és összehasonlítása elengedhetetlen (National Center for Biotechnology Information). Térbeli hatékonyságuk és sebességük miatt a nagy léptékű alkalmazásokban preferálják őket a suffix fákkal szemben.
Teljesítménybeli szempontok és korlátok
A suffix tömbök rendkívül hatékony adatstruktúrák különböző szövegfeldolgozási problémák, például részszöveg keresés, mintaillesztés és a leghosszabb közös prefix kiszámítása megoldására. Azonban a teljesítményüket és alkalmazhatóságukat több tényező és inherent korlátozás befolyásolja.
Az egyik fő teljesítménybeli tényező az építési idő. Míg a naiv algoritmusok a suffix tömbök felépítésére O(n log2 n) időben működnek, fejlettebb algoritmusok lineáris időbeli bonyolultságot érnek el, mint például az SA-IS algoritmus. Mindazonáltal, ezek az optimális algoritmusok gyakran bonyolultak a végrehajtás során, és jelentős konstans tényezőkkel rendelkeznek, amelyek befolyásolják a gyakorlatban a teljesítményt, különösen nagyon nagy szövegek vagy memória-korlátozott környezetek esetén. A térbeli bonyolultság egy másik fontos szempont; a suffix tömb általában O(n) teret igényel, de a kiegészítő struktúrák, mint például a Leghosszabb Közös Prefix (LCP) tömb vagy további indexelési struktúrák a memóriafelhasználást tovább növelhetik University of Helsinki.
A suffix tömbök kevésbé rugalmasak, mint a suffix fák a dinamikus frissítések terén, például a szöveg belső betoldásainak vagy törléseinek végrehajtásában. A suffix tömb módosítása a felépítés után nem triviális, és gyakran az egész szerkezet újjáépítését igényli, így kevésbé alkalmasak olyan alkalmazásokhoz, ahol a szöveg gyakran változik Carnegie Mellon University. Továbbá, bár a suffix tömbök a suffix fákkal összehasonlítva hatékonyabbak, még mindig lehetnek gyakorlatilag nem kivitelezhetőek rendkívül nagy adathalmazon, például teljes genom szekvenciákon, további tömörítés vagy külső memória technikák nélkül National Center for Biotechnology Information.
Összefoglalva, míg a suffix tömbök jelentős előnyöket kínálnak sebesség és memóriahatékonyság terén statikus szövegek esetén, dinamikus szcenáriókban és nagy léptékű alkalmazásokban a korlátaikat figyelembe kell venni a rendszer tervezése során.
Valós példák és esetek
A suffix tömbök széles körben alkalmazottak különféle valós alkalmazásokban, amelyek hatékony szövegfeldolgozást és mintaillesztést igényelnek. Az egyik legkiemelkedőbb felhasználási eset a bioinformatikában található, különösen a genom szekvenálás és elemzés terén. Az olyan eszközök, mint a Burrows-Wheeler Aligner, suffix tömböket használnak, hogy gyorsan összehangolják a rövid DNS olvasmányokat a referencia genomokkal, lehetővé téve a nagy léptékű genomikai tanulmányokat és a személyre szabott orvoslást.
Az információkeresés terén a suffix tömbök alapvető szerepet játszanak a gyors teljes szöveges keresőmotorok megvalósításában. Például az Apache Lucene projekt a suffix tömböket és a kapcsolódó adatstruktúrákat használja a hatékony részszöveg-keresési lehetőségek biztosítására, amelyek elengedhetetlenek a nagy szöveges korpuszek indexeléséhez és lekérdezéséhez.
A suffix tömbök emellett kulcsszerepet játszanak az adat tömörítési algoritmusokban is. A bzip2 tömörítő eszköz például a Burrows-Wheeler Transformat használja, amely a suffix tömb felépítésére támaszkodik az adat bemenetének átrendezéséhez és a tömöríthetőség javításához.
Ezen kívül a suffix tömböket plagizálás-észlelési rendszerekben, mint például a Turnitin, használják a dokumentumok közötti hasonlóságok azonosítására, hatékonyan összehasonlítva a részszövegeket. A természetes nyelv feldolgozása során olyan feladatokra használják őket, mint ismétlődő kifejezések azonosítása, kulcsszavak kinyerése és concordance-ok építése.
Ezek a példák kiemelik a suffix tömbök sokoldalúságát és hatékonyságát nagy léptékű szövegfeldolgozási feladatok kezelésében, változatos területeken, a számítástechnikai biológiától a keresőmotorokig és az adatok tömörítéséig.
További olvasmányok és haladó témák
A suffix tömbök iránt érdeklődő olvasóknak számos fejlettebb téma és forrás érhető el. Az egyik jelentős terület az enhanced suffix arrays tanulmányozása, amelyek a alap struktúrát kiegészítő adatokkal bővítik, mint például a Leghosszabb Közös Prefix (LCP) tömb, lehetővé téve a mintaillesztés és részszöveg lekérdezések hatékonyabb végrehajtását. A suffix tömbök és suffix fák közötti kölcsönhatás szintén gazdag terület, mivel mindkét struktúra hasonló problémák megoldására szolgál, de eltérő előnyökkel és hátrányokkal bír a tér és építési idő szempontjából.
A közelmúltban végzett kutatások a suffix tömbök lineáris időbeli felépítési algoritmusaira összpontosítottak, mint például az SA-IS és DC3 (Skew) algoritmusok, amelyek kulcsfontosságúak a nagy léptékű genomikai vagy szöveges adatok kezelésében. Ezeket az algoritmusokat részletesen tárgyalják szakirodalomban, beleértve az alapvető munkát a Helsinki Egyetem Funkcionális Suffix Tömb Csoportjától.
A suffix tömbök alkalmazása kiterjed más területekre is, mint például adat tömörítés (például Burrows-Wheeler Transform), bioinformatika (genom összeállítás és összehangolás), és információkeresés. A komprehensív áttekintéshez a Algorithm on Strings, Trees, and Sequences című Dan Gusfield könyv ajánlott.
- Suffix tömbök: Új módszer az online szövegkeresésekhez (eredeti cikk Manber & Myers által)
- Lineáris időbeli suffix tömb építés indukált rendezéssel (SA-IS algoritmus)
- Wikipedia: Suffix Array (áttekintés és további linkek)
Források és hivatkozások
- American Mathematical Society
- Princeton University
- Department of Computer Science, University of Helsinki
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Suffix Array