שליטה במערכי סופים: המדריך האולטימטיבי לעיבוד מחרוזות ולזיהוי תבניות. גלה כיצד מערכי סופים מהפכנים את האלגוריתמים הטקסטואליים.
- מבוא למערכי סופים
- איך מערכי סופים פועלים: מושגי יסוד
- בניית מערך סופים: שלב אחר שלב
- מערכי סופים מול עצי סופים: הבדלים מרכזיים
- יישומים של מערכי סופים במדעי המחשב
- אופטימיזציה של חיפוש וזיהוי תבניות באמצעות מערכי סופים
- אלגוריתמים נפוצים המסתמכים על מערכי סופים
- שיקולי ביצועים ומגבלות
- מקרים ושימושים אמיתיים ודוגמאות
- קריאה נוספת ונושאים מתקדמים
- מקורות והפניות
מבוא למערכי סופים
מערך סופים הוא מבנה נתונים חזק שמשמש בעיבוד מחרוזות, במיוחד עבור זיהוי תבניות, שאילתות תתי-מחרוזות ואינדוקס טקסט. הוא מייצג את סדר הממוין של כל הסופים של מחרוזת נתונה, בדרך כלל כמערך של אינדקסים התחליים. מבנה זה מאפשר מגוון רחב של יישומים בתחומים כגון ביואינפורמטיקה, דחיסת נתונים וחיפוש מידע, בהם חיפוש מהיר וניתוח של טקסטים גדולים הוא חיוני.
הרעיון של מערך סופים הוצג כחלופה חסכונית במקום לעץ סופים, מציע פונקציות דומות אך עם הפחתת עומס זיכרון. בניגוד לעצי סופים, שיכולים להיות מורכבים ליישום ולתחזוק, מערכי סופים הם פשוטים יותר וממוקדים יותר, מה שהופך אותם מתאימים למשימות עיבוד טקסט בקנה מידה גדול. בניית מערך סופים כוללת מיון של כל הסופים האפשריים של מחרוזת, מה שניתן להשיג בזמן O(n log n) utilizando אלגוריתמים מבוססי השוואה, או אפילו בזמן ליניארי באמצעות טכניקות מתקדמות יותר כמו שיטת המיון המושרה (American Mathematical Society).
מערכי סופים משמשים לעיתים קרובות בשילוב עם המבנים הנתונים העזריים כמו מערך הגובה המשותף הארוך ביותר (LCP), שמגביר עוד יותר את התועלת שלהם בפתרון בעיות כמו חיפוש תת-מחרוזת החוזרת הארוכה ביותר או ביצוע השוואות יחידות לסדר הרוחב. היעילות והגמישות שלהם הפכו את מערכי סופים לכלי בסיסי בניתוח מחרוזות אלגוריתמי מודרני (Princeton University).
איך מערכי סופים פועלים: מושגי יסוד
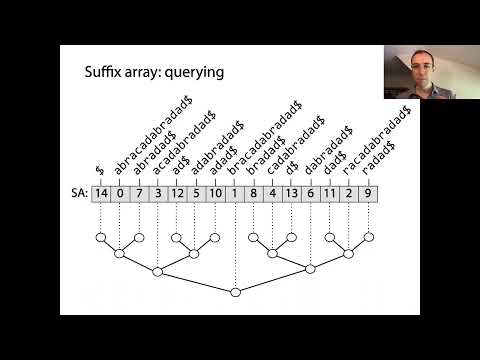
מערכי סופים הם מבני נתונים חזקים המאפשרים עיבוד מחרוזות יעיל, במיוחד עבור זיהוי תבניות ואינדוקס טקסט. בעיקרם, מערכי סופים מייצגים את סדר הממוין של כל הסופים האפשריים של מחרוזת נתונה. הבנייה מתחילה בהפקת כל סופו של המחרוזת הקלט, כאשר כל אחד מתחיל במיקום שונה. הסופים הללו מסודרים לאחר מכן לסדר לקסיקוגרפי, ומערך הסופים עצמו הוא מערך של שלמים, שבו כל רשומה מצביעה על האינדקס ההתחלתי של סוֹף בסדר זה.
המושג המרכזי מאחורי מערכי סופים הוא שבזמן שמיון כל הסופים, ניתן לבצע חיפושים בינאריים מהירים במטרה לאתר תתי-מחרוזות או תבניות בטקסט המקורי. זהו שיפור משמעותי על פני שיטות חיפוש נאיביות, שעשויות לדרוש סריקה של כל הטקסט לכל שאילתה. מערכי סופים משולבים לעיתים קרובות עם מערך החזקה המשותפת הארוך ביותר (LCP), ששומר את האורכים של החזקים המשותפים הארוכים ביותר בין סופים עוקבים במערך הממויין. חיבור זה מאיץ עוד יותר מגוון פעולות מחרוזות, כגון מציאת תתי-מחרוזות חוזרות או מספר תתי-מחרוזות ייחודיות.
אלגוריתמים יעילים לבנייה, כגון שיטת המיון המושרה או השימוש בהכפלת תחיליות, הפחיתו את הזמן הפנוי לבניית מערכי סופים לזמן ליניארי או קרוב לליניארי, מה שהופך אותם למציאותיים עבור יישומים בקנה מידה גדול. מערכי סופים בשימוש נרחב בביו אינפורמטיקה, דחיסת נתונים וחיפוש מידע, שבהם עיבוד מחרוזות מהיר וחסכוני בזיכרון הוא חיוני. למידע מקיף על העקרונות והאלגוריתמים היסודיים, עיין בדוקומנטציה של המחלקה למדעי המחשב, אוניברסיטת הלסינקי.
בניית מערך סופים: שלב אחר שלב
בניית מערך סופים כוללת הקמת מערך מסודר של כל הסופים של מחרוזת נתונה, המיוצגים על ידי אינדקסים התחליים שלהם. התהליך ניתן לפירוק למספר שלבים מרכזיים:
- 1. הפקת כל הסופים: עבור מחרוזת באורך n, נמנה את כל הסופים לפי המיקומים ההתחלתיים שלהם. לדוגמה, המילה "בננה" מניבה סופים המתחילים באינדקסים 0 ("בננה"), 1 ("אננה"), 2 ("ננה"), וכן הלאה.
- 2. מיון הסופים: מיין את הסופים הללו בסדר לקסיקוגרפי. זה יכול להתבצע נאיבית בזמן O(n2 log n) על ידי השוואת מחרוזות ישירות, אבל אלגוריתמים יעילים יותר קיימים.
- 3. שמירת האינדקסים: במקום לשמור את המחרוזות הסופיות עצמן, שמור את האינדקסים ההתחלתיים שלהם בסדר הממויין. מערך האינדקסים הזה הוא מערך הסופים.
- 4. אופטימיזציה: אלגוריתמים מתקדמים, כגון אלגוריתם מאנבר-מאיירס, משתמשים בטכניקת הכפלה להשגת מורכבות בזמן של O(n log n). אפילו מהר יותר, האלגוריתם קארקינן-סנדרס (המוכר גם כאלגוריתם סקיו) יכול לבנות את מערך הסופים בזמן ליניארי O(n) עבור אלפביתים של מספרים שלמים. שיטות אלו מתבססות על מיון לפי דרגות וטכניקות רקורסיביות כדי להימנע מהשוואות ממוקדות Association for Computing Machinery.
- 5. פלט סופי: מערך הסופים המתקבל מאפשר זיהוי תבניות יעיל, שאילתות תתי-מחרוזות, והוא בסיס להקמת מבנים נתונים אחרים כמו מערך LCP GeeksforGeeks.
הבנה של כל שלב והאופטימיזציות הזמינות היא חיונית לניצול מערכי סופים ביישומים גדולים של עיבוד מחרוזות.
מערכי סופים מול עצי סופים: הבדלים מרכזיים
מערכי סופים ועצי סופים הם מבני נתונים יסודיים לעיבוד מחרוזות יעיל, במיוחד ביישומים כמו זיהוי תבניות, ביואינפורמטיקה ודחיסת נתונים. בעוד שהם משרתים מטרות דומות, המבנים שלהם, דרישות הזיכרון והמאפיינים התפעוליים שונים במידה רבה.
עץ סופים הוא טרי דחוס של כל הסופים של מחרוזת נתונה, המאפשר שאילתות תתי-מחרוזות מהירות מאוד, בדרך כלל בזמן ליניארי ביחס לאורך התבנית. עם זאת, עצי סופים מסובכים ליישום ודורשים עלויות זיכרון משמעותיות—לעיתים כמה פעמים מגודל המחרוזת המקורית—עקב מבנה מבוסס הצמתים וניהול מצביעים ותוויות קצה. זה מקשה על השימוש בהם עבור נתונים מאוד גדולים או בסביבות מוגבלות בזיכרון.
בניגוד לכך, מערך סופים הוא מבנה נתונים פשוט בהרבה וחסכוני במרחב. הוא מורכב ממערך של שלמים המייצגים את המיקומים ההתחלתיים של כל הסופים הממוינים של המחרוזת. מערכי סופים ניתן לבנות בזמן ליניארי ודורשים רק O(n) שטח, כאשר n הוא אורך המחרוזת. בעוד שחיפושי תתי-מחרוזות באמצעות מערך סופים בדרך כלל איטיים יותר מאשר עם עץ סופים (O(m log n) עבור תבנית באורך m), ניתן לשפר זאת ל-O(m) עם מבנים נתונים עזריים כגון מערך LCP. הפשטות và כמות הזיכרון הנמוכה של מערכי סופים מקנים להם יתרון בעבודות אינדוקס טקסט רחבות היקף.
לצורך השוואה מפורטת ועיון נוסף, ראו Association for Computing Machinery ו-GeeksforGeeks.
יישומים של מערכי סופים במדעי המחשב
מערכי סופים הפכו למבנה נתונים בסיסי במדעי המ מחשב, במיוחד בתחומים של עיבוד מחרוזות, ביואינפורמטיקה וחיפוש מידע. התועלת העיקרית שלהם היא בהענקת יכולות זיהוי תבניות ושאילתות תתי-מחרוזות ביעילות. לדוגמה, מערכי סופים משמשים באופן נרחב במנועי חיפוש עם טקסט מלא, שבהם הם מאפשרים לזיהוי מהיר של כל המקרים של תת-מחרוזת בתוך מאגר טקסטים גדול. זה מושג על ידי ניצול הסדר הממויין לסדר לקסיקוגרפי של הסופים, המאפשר פעולות חיפוש בינארי להתאמת תבניות בזמן מורכבות של לוגריתמית Princeton University.
בביואינפורמטיקה, מערכי סופים מקלים על יישור והשוואת רצפי DNA וחלבונים. כלים להקמת גנום והשוואת רצפים, כמו אלו המשמשים ברצף דורות הבאים, נשענים לרוב על מערכי סופים כדי לטפל ביעילות בקובצי נתונים ביולוגיים עצומים מרכז הלאומי למידע ביוטכנולוגי. בנוסף, מערכי סופים הם חלק מהותי מאלגוריתמים לדחיסת נתונים כמו טרנספורמציית בורו-ווילר, שעומדת בבסיס כלים פופולריים לדחיסה כמו bzip2. כאן, מערך הסופים מאפשר את ההמרה של נתוני הקלט לצורה הנוחה יותר לדחיסת נתונים על ידי קיבוץ תוים דומים יחד bzip2.
מעבר לכך, מערכי סופים משמשים גם במערכות לגילוי גניבה, הכפלת נתונים, והקמת מבנים נתונים יעילים לשאילתות LCP. הגמישות והיעילות שלהם מקנים להם שימושים קריטיים ביישומים שבהם נדרשות פעולות מהירות וניתנות להתרחבות בעיבוד מחרוזות.
אופטימיזציה של חיפוש וזיהוי תבניות באמצעות מערכי סופים
מערכי סופים הם מבני נתונים חזקים המייעלים באופן משמעותי את פעולות החיפוש וזיהוי התבניות במחרוזות. על ידי שמירה על האינדקסים ההתחלתיים של כל הסופים של טקסט בסדר לקסיקוגרפי, מערכי סופים מאפשרים שאילתות תתי-מחרוזות יעילות, החיוניות ביישומים כמו חיפוש טקסט מלא, ביואינפורמטיקה ודחיסת נתונים. היתרון העיקרי בשימוש במערך סופים על פני שיטות חיפוש נאיביות הוא ההפחתה במורכבות הזמן עבור זיהוי תבניות. בעוד גישה אכזרית עשויה לדרוש זמן O(nm) עבור טקסט באורך n ודפוס באורך m, מערכי סופים מאפשרים חיפושי תבניות בזמן O(m + log n) על ידי ניצול חיפוש בינארי על הסופים המסודרים.
כדי לשפר עוד יותר את הביצועים, מערכי סופים משמשים לעיתים קרובות בשילוב עם מבנים נתונים עזריים כמו מערך LCP הארוך ביותר. מערך LCP שומר את האורכים של החזקים המשותפים הארוכים ביותר בין סופים עוקבים במערך הסופים, ולהפוך אפילו את זיהוי התבניות ליעיל יותר ומקל על משימות כמו מציאת מספר תתי-מחרוזות ייחודיות או את תת-המחרוזת החוזרת הארוכה ביותר בזמן ליניארי. בנוסף, אלגוריתמים מודרניים לבניית מערכי סופים, כמו שיטת המיון המושרה, משיגים מורכבות זמן ליניארית, מה שהופך אותם למציאותיים עבור טקסטים בקנה מידה גדול (University of Helsinki).
מערכי סופים גם חסכוניים במרחב בהשוואה לעצי סופים, מכיוון שהם דורשים רק O(n) שטח וקל יותר ליישום. היעילות והגמישות שלהם הופכים אותם לאבן יסוד בעיצוב מערכות אינדוקס טקסט מהירות וקנה מידה זיהוי תבניות (Princeton University).
אלגוריתמים נפוצים המסתמכים על מערכי סופים
מערכי סופים הם מבנה נתונים בסיסי בעיבוד מחרוזות, המאפשר פתרונות יעילים למגוון בעיות מורכבות. מספר אלגוריתמים נפוצים מנצלים את מערכי סופים כדי להשיג ביצועים אופטימליים או קרובים לאופטימליים, במיוחד בתחומים של זיהוי תבניות, דחיסת נתונים וביואינפורמטיקה.
אחד היישומים הבולטים הוא בחיפוש תתי-מחרוזות. על ידי שילוב מערך סופים עם חיפוש בינארי, ניתן לאתר את כל המקרים של תבנית בטקסט בזמן O(m log n), כאשר m הוא אורך התבנית וn הוא אורך הטקסט. גישה זו היא מהירה משמעותית מאשר שיטות חיפוש נאיביות, במיוחד בטקסטים גדולים. בנוסף, מערך החזקה המשותפת הארוך ביותר (LCP) מוקם לעיתים קרובות מיד עם מערך הסופים כדי לייעל עוד יותר שאילתות תבניות חוזרות ולסייע באלגוריתמים לזיהוי תתי-המחרוזת החוזרת הארוכה ביותר או תת-המחרוזת המשותפת הארוכה ביותר בין מספר מחרוזות.
מערכי סופים גם משמשים כאמצעי מרכזי באלגוריתמי דחיסת נתונים כמו טרנספורמציית בורו-ווילר (BWT), שהיא רכיב מרכזי בכלי דחיסה bzip2. ה-BWT נשען על סדר העילוי של הסופים לסדר מחדש של הטקסט הקלט, מה שהופך אותו לנוח יותר לקידוד לפי רצועות וטכניקות דחיסה אחרות (bzip2).
באופן ביואינפורמטית, מערכי סופים משמשים ליישור והשוואת רצפים יעילים, כאשר חיפושים מהירים והשוואות של רצפי DNA חיוניים (מרכז הלאומי למידע ביוטכנולוגי). היעילות שלהם במרחב ובמהירות הופכת אותם למועדפים על פני עצי סופים בהרבה יישומים בקנה מידה גדול.
שיקולי ביצועים ומגבלות
מערכי סופים הם מבנים נתונים יעילים מאוד לפתרון מגוון בעיות עיבוד מחרוזות, כמו חיפוש תתי-מחרוזות, זיהוי תבניות וחישוב חזקים משותפים ארוכים ביותר. עם זאת, הביצועים והיישומיות שלהם מושפעים ממספר שיקולים ומגבלות טבועות.
אחד מהגורמים המרכזיים לביצועים הוא זמן הבנייה. בעוד שיטה פשוטה לבניית מערכי סופים פועלת בזמן O(n log2 n), אלגוריתמים מתקדמים יותר משיגים מורכבות זמן ליניארית, כמו אלגוריתם SA-IS. עם זאת, אלגוריתמים אופטימליים אלו יכולים להיות מורכבים ליישום ולהכיל גורמים קבועים משמעותיים, העוברים על הביצועים המע практичного, במיוחד עבור טקסטים מאוד גדולים או בסביבות מוגבלות במאגרי מידע. מורכבות הזיכרון היא גם אספקט חשוב; מערך סופים בדרך כלל דורש O(n) שטח, אבל מבנים עזריים כמו מערך LCP הארוך ביותר או מבני אינדוקס נוספים יכולים להגדיל את השימוש בזיכרון עוד יותר University of Helsinki.
מערכי סופים פחות גמישים מעצי סופים כשמדובר בעדכונים דינמיים, כמו הכנסות או מחיקות בתוך הטקסט. שינוי מערך סופים לאחר הבנייה שלו אינו פשוט ולעיתים קרובות דורש בנייה מחדש של כל המבנה, דבר שהופך אותו לפחות מתאים ליישומים שבהם הטקסט הבסיסי משנה לעיתים קרובות Carnegie Mellon University. בנוסף, בעוד שמערכי סופים חסכוניים יותר במרחב לעומת עצי סופים, הם עשויים להיות לא מעשיים עבור קבוצות נתונים גדולות מאוד, כמו רצפים גנומיים שלמים, מבלי להשתמש בדחיסה נוספת או טכניקות של זיכרון חיצוני מרכז הלאומי למידע ביוטכנולוגי.
לסיכום, בעוד שמערכי סופים מציעים יתרונות משמעותיים מבחינת מהירות ויעילות זיכרון עבור טקסטים סטטיים, יש לשקול בזהירות את המגבלות שלהם במצבים דינמיים וביישומים בקנה מידה גדול במהלך עיצוב המערכת.
מקרים ושימושים אמיתיים ודוגמאות
מערכי סופים משמשים באופן נרחב ביישומים שונים בעולם האמיתי הדורשים עיבוד מחרוזות יעיל וזיהוי תבניות. אחד משימושים הבולטים הוא בביואינפורמטיקה, במיוחד בהקשר של רצוף גנום וניתוח. כלים כמו בורו-ווילר אלינר משתמשים במערכי סופים כדי ליישר במהירות קריאות DNA קצרות לגנומים מגדיר, ומאפשרים מחקרים גנומיים על פני קנה מידה גדול ורפואה מותאמת אישית.
בחקירת מידע, מערכי סופים הם עצם יסוד עבור יישום מנועי חיפוש בולטים. לדוגמה, פרויקט Apache Lucene מנצל את מערכי הסופים ומבני נתונים קשורים כדי לספק יכולות חיפוש תתי-מחרוזות יעילות, השייכות לאינדוקס ולשאילתות של מאגרי טקסטים גדולים.
מערכי סופים גם ממלאים תפקיד מהותי באלגוריתמי דחיסת נתונים. לדוגמה, כלי דחיסת bzip2 משיב את טרנספורמציית בורו-ווילר, התלויה בהקמת מערך סופים כדי לסדר מידע קלט ולשפר את הדחיסות.
בנוסף, מערכי סופים משמשים במערכות לזיהוי גניבה, כמו Turnitin, כדי לאתר דמיון בין מסמכים על ידי השוואת תתי-מחרוזות ביעילות. בעיבוד השפה הטבעית, הם משמשים במשימות כמו זיהוי ביטויים חוזרים, חילוץ מילות מפתח ובניית קונקורדנציה.
דוגמאות אלו מדגישות את הגמישות והיעילות של מערכי סופים בטיפול במשימות עיבוד מחרוזות בקנה מידה גדול בתחומים שונים, מרפואה חישובית עד למנועי חיפוש ודחיסת נתונים.
קריאה נוספת ונושאים מתקדמים
לגולשים שמעוניינים לצלול יותר אל תוך מערכי סופים, ישנם מספר נושאים avanzados ומקורות זמינים. אחד מהתחומים המיוחדים הוא חקר מערכי סופים משופרים, המוסיפים מבנה הבסיסי עם נתונים נוספים כמו מערך LCP, מה שמאפשר זיהוי תבניות ושאילתות תתי-מחרוזות בצורה יעילה יותר. הגומחה בין מערכי סופים לעצי סופים היא גם תחום עושר, כאשר שני המבנים פותרים בעיות דומות, אך עם שיקולים שונים של מקום וזמן בנייה.
מחקרים עכשוויים התמקדות במערכי בניית ליניאריים עבור מערכי סופים, כמו אלגוריתמי SA-IS ו-DC3 (סקיו), שהם גישות חיוניות לניהול נתונים בגנה הנעים על קנה מידה גדול. אלגוריתמים אלה נדונים בפרטים בספרות, כולל העבודה הבסיסית של University of Helsinki Functional Suffix Array Group.
יישומי מערכי סופים מתפרסים מעבר לזיהוי מחרוזות לאזורים כמו דחיסת נתונים (כגון טרנספורמציית בורו-ווילר), ביואינפורמטיקה (הקמת גנום ויישור) וחיפוש מידע. לקבלת סקירה מקיפה, מומלץ לקרוא את הספר Algorithms on Strings, Trees, and Sequences מאת דן גוספילד.
- מערכי סופים: שיטה חדשה לחיפושי מחרוזות אונליין (מאמר מקורי מאת מאנבר & מאיירס)
- בנייה ליניארית של מערכי סופים באמצעות מיון מושרה (אלגוריתם SA-IS)
- ויקיפדיה: מערך סופים (סקירה וקישורים נוספים)
מקורות והפניות
- American Mathematical Society
- Princeton University
- Department of Computer Science, University of Helsinki
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Suffix Array