Maîtriser les tableaux de suffixes : le guide ultime pour un traitement efficace des chaînes et une recherche de motifs. Découvrez comment les tableaux de suffixes révolutionnent les algorithmes de texte.
- Introduction aux tableaux de suffixes
- Fonctionnement des tableaux de suffixes : concepts clés
- Construction d’un tableau de suffixes : étape par étape
- Tableaux de suffixes vs. arbres de suffixes : principales différences
- Applications des tableaux de suffixes en informatique
- Optimiser la recherche et la correspondance de motifs avec les tableaux de suffixes
- Algorithmes courants utilisant des tableaux de suffixes
- Considérations de performance et limitations
- Cas d’utilisation et exemples du monde réel
- Lectures supplémentaires et sujets avancés
- Sources & Références
Introduction aux tableaux de suffixes
Un tableau de suffixes est une structure de données puissante utilisée dans le traitement de chaînes, en particulier pour la recherche efficace de motifs, les requêtes de sous-chaînes et l’indexation de texte. Il représente l’ordre trié de tous les suffixes d’une chaîne donnée, généralement sous la forme d’un tableau d’indices de départ. Cette structure permet une variété d’applications dans des domaines tels que la bioinformatique, la compression de données et la recherche d’informations, où la recherche rapide et l’analyse de grands textes sont essentielles.
Le concept de tableau de suffixes a été introduit comme une alternative économiquement efficace à l’arbre de suffixes, offrant des fonctionnalités similaires mais avec une réduction de l’empreinte mémoire. Contrairement aux arbres de suffixes, qui peuvent être complexes à mettre en œuvre et à maintenir, les tableaux de suffixes sont plus simples et plus compacts, ce qui les rend adaptés aux tâches de traitement de texte à grande échelle. La construction d’un tableau de suffixes implique de trier tous les suffixes possibles d’une chaîne, ce qui peut être réalisé en O(n log n) avec des algorithmes basés sur des comparaisons, ou même en temps linéaire avec des techniques plus avancées telles que la méthode de tri induite (American Mathematical Society).
Les tableaux de suffixes sont souvent utilisés en conjonction avec des structures de données auxiliaires comme le tableau du Plus Long Préfixe Commun (LCP), qui améliore encore leur utilité pour résoudre des problèmes tels que la recherche de la plus longue sous-chaîne répétée ou la réalisation de comparaisons lexicographiques rapides. Leur efficacité et leur polyvalence ont fait des tableaux de suffixes un outil fondamental dans l’analyse algorithmique moderne des chaînes (Princeton University).
Fonctionnement des tableaux de suffixes : concepts clés
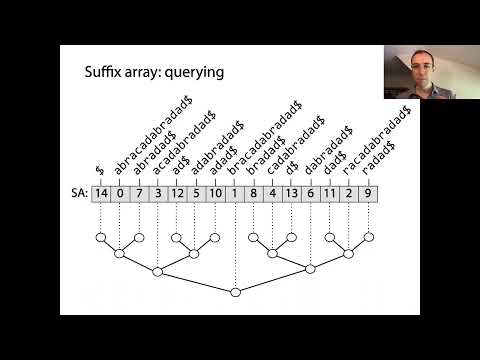
Les tableaux de suffixes sont des structures de données puissantes qui permettent un traitement efficace des chaînes, en particulier pour la recherche de motifs et l’indexation de texte. Au cœur des tableaux de suffixes se trouve la représentation de l’ordre trié de tous les suffixes possibles d’une chaîne donnée. La construction commence par la génération de chaque suffixe de la chaîne d’entrée, chacun commençant à une position différente. Ces suffixes sont ensuite triés lexicographiquement, et le tableau de suffixes lui-même est un tableau d’entiers, où chaque entrée indique l’indice de départ d’un suffixe dans cet ordre trié.
Le concept clé derrière les tableaux de suffixes est que, en triant tous les suffixes, on peut effectuer des recherches binaires rapides pour localiser des sous-chaînes ou des motifs dans le texte original. Cela représente une amélioration significative par rapport aux méthodes de recherche naïves, qui peuvent nécessiter de parcourir l’ensemble du texte pour chaque requête. Les tableaux de suffixes sont souvent associés au tableau du Plus Long Préfixe Commun (LCP), qui stocke les longueurs des plus longs préfixes communs entre les suffixes consécutifs dans le tableau trié. Cette association accélère encore diverses opérations sur les chaînes, comme la recherche de sous-chaînes répétées ou le nombre de sous-chaînes distinctes.
Des algorithmes de construction efficaces, tels que la méthode de tri induite ou l’utilisation du doublage de préfixes, ont réduit la complexité temporelle de construction des tableaux de suffixes à un temps linéaire ou presque linéaire, les rendant pratiques pour des applications à grande échelle. Les tableaux de suffixes sont largement utilisés en bioinformatique, compression de données et recherche d’informations, où un traitement efficace et consommant peu de mémoire des chaînes est essentiel. Pour un aperçu complet des principes et algorithmes sous-jacents, reportez-vous à la documentation du Département d’informatique, Université d’Helsinki.
Construction d’un tableau de suffixes : étape par étape
Construire un tableau de suffixes implique de créer un tableau trié de tous les suffixes d’une chaîne donnée, représentés par leurs indices de départ. Le processus peut être décomposé en plusieurs étapes clés :
- 1. Générer tous les suffixes : Pour une chaîne de longueur n, énumérer tous les suffixes par leurs positions de départ. Par exemple, la chaîne « banane » donne des suffixes commençant aux indices 0 (« banane »), 1 (« anana »), 2 (« nana »), etc.
- 2. Trier les suffixes : Trier ces suffixes de manière lexicographique. Cela peut être fait naïvement en O(n2 log n) en comparant les chaînes directement, mais des algorithmes plus efficaces existent.
- 3. Stocker les indices : Au lieu de stocker les chaînes de suffixes réelles, stocker leurs indices de départ dans l’ordre trié. Ce tableau d’indices est le tableau de suffixes.
- 4. Optimisation : Des algorithmes avancés, tels que l’algorithme Manber-Myers, utilisent une technique de doublage pour atteindre une complexité temporelle de O(n log n). Encore plus rapide, l’algorithme Karkkainen-Sanders (également connu sous le nom d’algorithme Skew) peut construire le tableau de suffixes en temps linéaire O(n) pour des alphabets d’entiers. Ces méthodes s’appuient sur le tri par rang et des stratégies récursives pour éviter les comparaisons directes de chaînes Association for Computing Machinery.
- 5. Sortie finale : Le tableau de suffixes résultant permet une correspondance efficace de motifs, des requêtes de sous-chaîne et est fondamental pour construire d’autres structures de données comme le tableau LCP GeeksforGeeks.
Comprendre chaque étape et les optimisations disponibles est crucial pour exploiter les tableaux de suffixes dans des applications de traitement de chaînes à grande échelle.
Tableaux de suffixes vs. arbres de suffixes : principales différences
Les tableaux de suffixes et les arbres de suffixes sont tous deux des structures de données fondamentales pour un traitement efficace des chaînes, en particulier dans des applications telles que la recherche de motifs, la bioinformatique et la compression de données. Bien qu’ils servent des objectifs similaires, leurs structures, exigences mémoire et caractéristiques opérationnelles diffèrent considérablement.
Un arbre de suffixes est un trie compressé de tous les suffixes d’une chaîne donnée, permettant des requêtes de sous-chaînes extrêmement rapides, généralement en temps linéaire par rapport à la longueur du motif. Cependant, les arbres de suffixes sont complexes à mettre en œuvre et nécessitent une surcharge mémoire substantielle—souvent plusieurs fois la taille de la chaîne originale—en raison de leur structure basée sur des nœuds et de la nécessité de stocker des pointeurs et des étiquettes d’arêtes. Cela les rend moins pratiques pour des ensembles de données très volumineux ou des environnements à mémoire limitée.
En revanche, un tableau de suffixes est une structure de données beaucoup plus simple et plus efficace en espace. Il se compose d’un tableau d’entiers représentant les positions de départ de tous les suffixes triés de la chaîne. Les tableaux de suffixes peuvent être construits en temps linéaire et nécessitent seulement O(n) d’espace, où n est la longueur de la chaîne. Bien que les recherches de sous-chaînes utilisant un tableau de suffixes soient généralement plus lentes qu’avec un arbre de suffixes (O(m log n) pour un motif de longueur m), cela peut être amélioré à O(m) avec des structures de données auxiliaires telles que le tableau du Plus Long Préfixe Commun (LCP). La simplicité et l’empreinte mémoire réduite des tableaux de suffixes les rendent préférables pour les tâches d’indexation de texte et de recherche à grande échelle.
Pour une comparaison détaillée et une lecture complémentaire, voir Association for Computing Machinery et GeeksforGeeks.
Applications des tableaux de suffixes en informatique
Les tableaux de suffixes sont devenus une structure de données fondamentale en informatique, en particulier dans les domaines du traitement de chaînes, de la bioinformatique et de la recherche d’informations. Leur utilité principale réside dans la possibilité d’effectuer des recherches efficaces de motifs et des requêtes de sous-chaînes. Par exemple, les tableaux de suffixes sont largement utilisés dans les moteurs de recherche en texte intégral, où ils permettent une identification rapide de tous les occurrences d’une sous-chaîne de requête au sein d’un large corpus textuel. Cela est réalisé en tirant parti de l’ordre trié lexicographiquement des suffixes, ce qui facilite les opérations de recherche binaire pour la correspondance de motifs avec une complexité temporelle logarithmique Princeton University.
En bioinformatique, les tableaux de suffixes facilitent l’alignement et la comparaison des séquences ADN et des protéines. Les outils pour l’assemblage de génomes et l’alignement de séquences, tels que ceux utilisés dans le séquençage de nouvelle génération, s’appuient souvent sur les tableaux de suffixes pour gérer efficacement d’énormes ensembles de données biologiques National Center for Biotechnology Information. De plus, les tableaux de suffixes sont intégrés dans les algorithmes de compression de données comme la Transformation de Burrows-Wheeler, qui sous-tend des outils de compression populaires comme bzip2. Ici, le tableau de suffixes permet de transformer les données d’entrée en une forme plus propice à la compression en regroupant des caractères similaires.
Au-delà de cela, les tableaux de suffixes sont également utilisés dans la détection de plagiat, la dé-duplication des données et la construction de structures de données efficaces pour les requêtes du Plus Long Préfixe Commun (LCP). Leur polyvalence et leur efficacité les rendent indispensables dans des applications où un traitement rapide et évolutif des chaînes est requis.
Optimiser la recherche et la correspondance de motifs avec les tableaux de suffixes
Les tableaux de suffixes sont des structures de données puissantes qui optimisent considérablement les opérations de recherche et de correspondance de motifs dans les chaînes. En stockant les indices de départ de tous les suffixes d’un texte dans l’ordre lexicographique, les tableaux de suffixes permettent des requêtes de sous-chaînes efficaces, qui sont fondamentales dans des applications telles que la recherche en texte intégral, la bioinformatique et la compression de données. L’avantage principal de l’utilisation d’un tableau de suffixes par rapport aux méthodes de recherche naïves est la réduction de la complexité temporelle pour la correspondance de motifs. Alors qu’une approche de force brute peut nécessiter O(nm) de temps pour un texte de longueur n et un motif de longueur m, les tableaux de suffixes permettent des recherches de motifs en O(m + log n) en tirant parti de la recherche binaire sur les suffixes triés.
Pour améliorer encore les performances, les tableaux de suffixes sont souvent utilisés en conjonction avec des structures de données auxiliaires comme le tableau du Plus Long Préfixe Commun (LCP). Le tableau LCP stocke les longueurs des plus longs préfixes communs entre les suffixes consécutifs dans le tableau de suffixes, permettant une correspondance de motifs encore plus rapide et facilitant des tâches telles que la recherche du nombre de sous-chaînes distinctes ou de la plus longue sous-chaîne répétée en temps linéaire. De plus, les algorithmes modernes pour construire des tableaux de suffixes, tels que la méthode de tri induite, atteignent une complexité temporelle linéaire, ce qui les rend pratiques pour des textes à grande échelle (Université d’Helsinki).
Les tableaux de suffixes sont également économes en espace par rapport aux arbres de suffixes, car ils ne nécessitent qu’un espace de O(n) et sont plus faciles à mettre en œuvre. Leur efficacité et leur polyvalence en font une pierre angulaire dans la conception de systèmes d’indexation de texte et de correspondance de motifs rapides et évolutifs (Princeton University).
Algorithmes courants utilisant des tableaux de suffixes
Les tableaux de suffixes sont une structure de données fondamentale dans le traitement des chaînes, permettant des solutions efficaces à une variété de problèmes complexes. Plusieurs algorithmes courants tirent parti des tableaux de suffixes pour atteindre des performances optimales ou quasi-optimales, en particulier dans les domaines de la recherche de motifs, de la compression de données et de la bioinformatique.
Une des applications les plus notables est la recherche de sous-chaînes. En combinant un tableau de suffixes avec une recherche binaire, il est possible de localiser toutes les occurrences d’un motif dans un texte en O(m log n), où m est la longueur du motif et n est la longueur du texte. Cette approche est considérablement plus rapide que les méthodes de recherche naïves, surtout pour des textes volumineux. De plus, le tableau du Plus Long Préfixe Commun (LCP) est souvent construit en parallèle du tableau de suffixes pour optimiser davantage les requêtes de motifs répétés et pour faciliter les algorithmes de recherche de la plus longue sous-chaîne répétée ou de la plus longue sous-chaîne commune entre plusieurs chaînes.
Les tableaux de suffixes sont également intégrés dans les algorithmes de compression de données tels que la Transformation de Burrows-Wheeler (BWT), qui est un composant clé de l’outil de compression bzip2. La BWT s’appuie sur l’ordre trié des suffixes pour réorganiser le texte d’entrée, le rendant plus propice à l’encodage par longueur de course et à d’autres techniques de compression (bzip2).
En bioinformatique, les tableaux de suffixes sont utilisés pour l’alignement des séquences et l’analyse des génomes, où la recherche rapide et la comparaison des séquences ADN sont essentielles (National Center for Biotechnology Information). Leur efficacité en espace et leur rapidité les rendent préférables aux arbres de suffixes dans de nombreuses applications à grande échelle.
Considérations de performance et limitations
Les tableaux de suffixes sont des structures de données très efficaces pour résoudre une variété de problèmes de traitement de chaînes, tels que la recherche de sous-chaînes, la correspondance de motifs et le calcul du plus long préfixe commun. Cependant, leur performance et leur applicabilité sont influencées par plusieurs considérations et limitations inhérentes.
Un des principaux facteurs de performance est le temps de construction. Alors que les algorithmes naïfs pour construire des tableaux de suffixes fonctionnent en O(n log2 n), des algorithmes plus avancés atteignent une complexité temporelle linéaire, tel que l’algorithme SA-IS. Néanmoins, ces algorithmes optimaux peuvent être complexes à mettre en œuvre et peuvent avoir des facteurs constants significatifs, ce qui peut affecter la performance pratique, surtout pour des textes très volumineux ou dans des environnements à mémoire limitée. La complexité spatiale est un autre aspect important ; un tableau de suffixes nécessite généralement un espace de O(n), mais des structures auxiliaires comme le tableau du Plus Long Préfixe Commun (LCP) ou des structures d’indexation supplémentaires peuvent augmenter davantage l’utilisation de la mémoire Université d’Helsinki.
Les tableaux de suffixes sont moins flexibles que les arbres de suffixes en ce qui concerne les mises à jour dynamiques, telles que les insertions ou les suppressions dans le texte. Modifier un tableau de suffixes après sa construction n’est pas trivial et nécessite souvent de reconstruire l’ensemble de la structure, ce qui le rend moins adapté aux applications où le texte sous-jacent change fréquemment Carnegie Mellon University. De plus, bien que les tableaux de suffixes soient plus économes en espace que les arbres de suffixes, ils peuvent tout de même s’avérer impratiques pour les ensembles de données extrêmement volumineux, comme des séquences génomiques complètes, sans techniques de compression ou de mémoire externe supplémentaires National Center for Biotechnology Information.
En résumé, bien que les tableaux de suffixes offrent des avantages significatifs en termes de rapidité et d’efficacité mémoire pour les textes statiques, leurs limitations dans les scénarios dynamiques et les applications à grande échelle doivent être soigneusement prises en compte lors de la conception du système.
Cas d’utilisation et exemples du monde réel
Les tableaux de suffixes sont largement utilisés dans diverses applications du monde réel nécessitant un traitement efficace des chaînes et une correspondance de motifs. Un des cas d’utilisation les plus notables se situe dans la bioinformatique, en particulier dans le séquençage et l’analyse du génome. Des outils tels que le Burrows-Wheeler Aligner utilisent des tableaux de suffixes pour aligner rapidement de courtes lectures d’ADN sur des génomes de référence, permettant des études génomiques à grande échelle et la médecine personnalisée.
Dans la recherche d’informations, les tableaux de suffixes sont fondamentaux pour la mise en œuvre de moteurs de recherche rapide en texte intégral. Par exemple, le projet Apache Lucene exploite les tableaux de suffixes et des structures de données apparentées pour fournir des capacités de recherche de sous-chaînes efficaces, qui sont essentielles pour l’indexation et l’interrogation de grands corpus textuels.
Les tableaux de suffixes jouent également un rôle crucial dans les algorithmes de compression de données. L’outil de compression bzip2, par exemple, utilise la Transformation de Burrows-Wheeler, qui repose sur la construction d’un tableau de suffixes pour réorganiser les données d’entrée et améliorer la compressibilité.
De plus, les tableaux de suffixes sont employés dans des systèmes de détection de plagiat, comme Turnitin, pour identifier les similitudes entre documents en comparant efficacement les sous-chaînes. Dans le traitement du langage naturel, ils sont utilisés pour des tâches telles que l’identification de phrases répétées, l’extraction de mots-clés et la construction de concordances.
Ces exemples soulignent la polyvalence et l’efficacité des tableaux de suffixes dans le traitement de tâches de chaînes à grande échelle à travers divers domaines, de la biologie computationnelle aux moteurs de recherche et à la compression de données.
Lectures supplémentaires et sujets avancés
Pour les lecteurs intéressés à approfondir le sujet des tableaux de suffixes, plusieurs sujets avancés et ressources sont disponibles. Un domaine important est l’étude des tableaux de suffixes améliorés, qui augmentent la structure de base avec des données supplémentaires telles que le tableau du Plus Long Préfixe Commun (LCP), permettant une correspondance de motifs plus efficace et des requêtes de sous-chaînes. L’interaction entre les tableaux de suffixes et les arbres de suffixes est également un domaine riche, car les deux structures résolvent des problèmes similaires mais avec des compromis différents en termes d’espace et de temps de construction.
Des recherches récentes se sont concentrées sur les algorithmes de construction en temps linéaire pour les tableaux de suffixes, tels que les algorithmes SA-IS et DC3 (Skew), qui sont cruciaux pour gérer des données génomiques ou textuelles à grande échelle. Ces algorithmes sont détaillés dans la documentation, y compris le travail fondamental du Groupe de tableaux de suffixes fonctionnels de l’Université d’Helsinki.
Les applications des tableaux de suffixes s’étendent au-delà de la correspondance de chaînes à des domaines tels que la compression de données (par exemple, la Transformation de Burrows-Wheeler), la bioinformatique (assemblage et alignement de génomes) et la recherche d’informations. Pour un aperçu complet, le livre Algorithms on Strings, Trees, and Sequences de Dan Gusfield est fortement recommandé.
- Tableaux de suffixes : une nouvelle méthode pour les recherches de chaînes en ligne (article original par Manber & Myers)
- Construction de tableaux de suffixes en temps linéaire utilisant le tri induit (algorithme SA-IS)
- Wikipedia : tableau de suffixes (aperçu et liens supplémentaires)
Sources & Références
- American Mathematical Society
- Princeton University
- Département d’informatique, Université d’Helsinki
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia : tableau de suffixes