Suffix-taulukoiden hallinta: Tehokkaan merkkijonojen käsittelyn ja kuvioiden etsinnän lopullinen opas. Opi, miten suffix-taulukot mullistavat tekstialgoritmit.
- Johdanto suffix-taulukkoihin
- Miten suffix-taulukot toimivat: Peruskäsitteet
- Suffix-taulukon rakentaminen: Vaihe vaiheelta
- Suffix-taulukot vs. Suffix-puut: Keskeiset erot
- Suffix-taulukoiden sovellukset tietojenkäsittelytieteessä
- Etsinnän ja kuvioiden etsinnän optimointi suffix-taulukoilla
- Yleisimmät algoritmit, jotka hyödyntävät suffix-taulukoita
- Suorituskykyratkaisut ja rajoitukset
- Todelliset käyttöesimerkit ja esimerkit
- Lisälukemista ja edistyneet aiheet
- Lähteet ja viitteet
Johdanto suffix-taulukkoihin
Suffix-taulukko on voimakas tietorakenne, jota käytetään merkkijonojen käsittelyssä, erityisesti tehokkaassa kuvioiden etsinnässä, alimerkkijonokyselyissä ja tekstinnäyttöisessä. Se edustaa annetun merkkijonon kaikkien suffixien järjestettyä järjestystä, tyypillisesti aloitusindeksien taulukkoina. Tämä rakenne mahdollistaa monenlaisia sovelluksia, kuten bioinformatiikassa, tietojen pakkaamisessa ja informaation hakemisessa, joissa suurten tekstien nopea haku ja analyysi ovat olennaisia.
Suffix-taulukkokäsite esiteltiin tilatehokkaana vaihtoehtona suffix-puille, jotka tarjoavat samankaltaisia toimintoja, mutta vähentävät muistin käyttöä. Toisin kuin suffix-puut, jotka voivat olla monimutkaisia toteuttaa ja ylläpitää, suffix-taulukot ovat yksinkertaisempia ja tiiviimpiä, mikä tekee niistä soveltuvia suuren mittakaavan tekstinkäsittelytehtäviin. Suffix-taulukon rakentaminen tarkoittaa kaikkien mahdollisten suffixien järjestämistä, mikä voidaan toteuttaa O(n log n) ajassa vertailevaan algoritmiin perustuen tai jopa lineaarisessa ajassa edistyneemmillä tekniikoilla, kuten indusoitunutta järjestämistä (American Mathematical Society).
Suffix-taulukoita käytetään usein yhdessä apurakenteiden, kuten pisimmän yhteisen etuliitteen (LCP) taulukon kanssa, mikä parantaa niiden hyödyllisyyttä ongelmien, kuten pisimmän toistuvan alimerkkijonon löytämisessä tai nopeissa leksikografisissa vertailuissa. Niiden tehokkuus ja monipuolisuus ovat tehneet suffix-tauluista perustyökalun nykyaikaisessa algoritmisessa merkkijonan analyysissa (Princeton University).
Miten suffix-taulukot toimivat: Peruskäsitteet
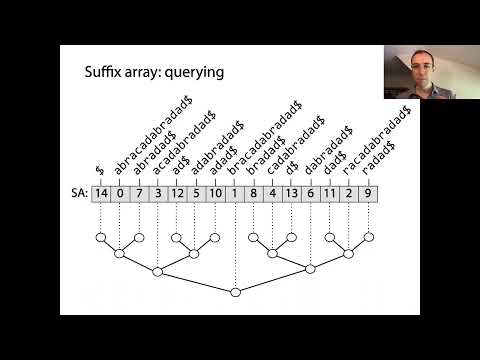
Suffix-taulukot ovat voimakkaita tietorakenteita, jotka mahdollistavat tehokkaan merkkijonojen käsittelyn, erityisesti kuvioiden etsinnässä ja tekstinnäyttöisessä. Perusasiantunteena on, että suffix-taulukot ilmentävät kaikkien mahdollisten suffixien järjestettyä järjestystä annetusta merkkijonosta. Rakentaminen alkaa generoimalla jokainen suffix syötteen merkkijonosta, kukin eri aloituspaikasta. Nämä suffixit järjestetään sitten leksikografisesti, ja itse suffix-taulukko on kokonaislukujen taulukko, jossa jokainen merkintä viittaa suffixin aloitusindeksiin tässä järjestyksessä.
Suffix-taulukoiden taustalla oleva avainkäsitys on, että järjestämällä kaikki suffixit voidaan suorittaa nopeita binäärisiä hakuja alimerkkijonojen tai kuvioiden paikantamiseksi alkuperäisestä tekstistä. Tämä on merkittävä parannus verrattuna naiiveihin hakumenetelmiin, jotka saattavat vaatia koko tekstin skannaamista jokaiselle kyselylle. Suffix-taulukkoja käytetään usein yhdessä pisimmän yhteisen etuliitteen (LCP) taulukon kanssa, joka tallentaa pisimpien yhteisten etuliitteiden pituudet järjestetyssä taulukossa. Tämä paritus nopeuttaa edelleen erilaisia merkkijonotoimintoja, kuten toistuvien alimerkkijonojen löytämistä tai erilaisten alimerkkijonojen määrän laskemista.
Tehokkaat rakentamisalgoritmit, kuten indusoidu järjestäminen tai etuliitteen kaksinkertaistus, ovat vähentäneet suffix-taulukoiden rakentamisen aikavaatimusta lineaariseen tai lähes lineaariseen aikaan, mikä tekee niistä käytännöllisiä suurissa sovelluksissa. Suffix-taulukot ovat laajasti käytössä bioinformatiikassa, tietojen pakkaamisessa ja informaation hakemisessa, missä nopea ja muistitehokas merkkijonojen käsittely on olennaista. Perusteelliseen tietoon perusteista ja algoritmeista viitataan Helsingin yliopiston tietojenkäsittelytieteen laitoksen dokumentaatioon.
Suffix-taulukon rakentaminen: Vaihe vaiheelta
Suffix-taulukon rakentaminen tarkoittaa kaikkien annetun merkkijonon suffixien järjestetyn taulukon luomista, joita edustavat niiden aloitusindeksit. Prosessi voidaan jakaa useisiin keskeisiin vaiheisiin:
- 1. Generoi kaikki suffixit: Merkkijonolle, jonka pituus on n, luetteloi kaikki suffixit niiden aloituspaikasta. Esimerkiksi merkkijono ”banana” tuottaa suffixit, jotka alkavat indikaattoreista 0 (”banana”), 1 (”anana”), 2 (”nana”) ja niin edelleen.
- 2. Järjestä suffixit: Järjestä nämä suffixit leksikografisesti. Tämä voidaan tehdä naiivia O(n2 log n) aikaa vaativalla menetelmällä vertaamalla merkkijonoja suoraan, mutta käytettävissä on tehokkaampia algoritmeja.
- 3. Tallenna indeksit: Sen sijaan, että tallennettaisiin itse suffix-merkkijonoja, tallenna niiden aloitusindeksit järjestyksessä. Tämä indeksien taulukko on suffix-taulukko.
- 4. Optimointi: Edistyneet algoritmit, kuten Manber-Myers -algoritmi, käyttävät kaksinkertaistusmenetelmää saavuttaakseen O(n log n) aikavaatimuksen. Vielä nopeammin, Karkkainen-Sanders -algoritmi (tunnetaan myös nimellä Skew-algoritmi) voi rakentaa suffix-taulukon lineaarisessa ajassa O(n) kokonaislukualfabeetille. Nämä menetelmät perustuvat järjestämiseen järjestyksen mukaan ja rekursiivisiin strategioihin, joiden avulla vältetään suorat merkkijonojen vertailut (Association for Computing Machinery).
- 5. Lopullinen tuotos: Saadut suffix-taulukot mahdollistavat tehokkaan kuvioiden etsimisen, alimerkkijonokyselyt, ja toimivat perustana muiden rakenteiden, kuten LCP-taulukon, rakentamiselle GeeksforGeeks.
Jokaisen vaiheen ja käytettävissä olevien optimointien ymmärtäminen on olennaista suffix-taulukoiden hyödyntämiseksi suurissa merkkijonojen käsittelysovelluksissa.
Suffix-taulukot vs. Suffix-puut: Keskeiset erot
Suffix-taulukot ja suffix-puut ovat molemmat perusrakenteita tehokkaassa merkkijonojen käsittelyssä, erityisesti sovelluksissa, kuten kuvioiden etsinnässä, bioinformatiikassa ja tietojen pakkaamisessa. Vaikka ne palvelevat samankaltaisia tarkoituksia, niiden rakenteet, muistin vaatimukset ja toiminnalliset ominaisuudet eroavat merkittävästi.
Suffix-puu on tiivistetty trie kaikista annetun merkkijonon suffixista, ja se mahdollistaa äärimmäisen nopeat alimerkkijonokyselyt, tyypillisesti lineaarisessa ajassa suhteessa kuvion pituuteen. Kuitenkin suffix-puut ovat monimutkaisempia toteuttaa ja ne vaativat merkittävästi enemmän muistia – usein useita kertoja alkuperäisen merkkijonon koon – johtuen solmupohjaisesta rakenteestaan ja osoitinten ja reunalippujen varastoinnin tarpeesta. Tämä tekee niistä vähemmän käytännöllisiä hyvin suurille tietojoukoille tai muistiin rajoitetuissa ympäristöissä.
Sen sijaan suffix-taulukko on paljon yksinkertaisempi ja tilatehokkaampi tietorakenne. Se koostuu kokonaislukutaulukosta, joka edustaa kaikkien järjestettyjen suffixien aloituspaikkoja merkkijonosta. Suffix-taulukot voidaan rakentaa lineaarisessa ajassa ja ne vaativat vain O(n) muistia, missä n on merkkijonon pituus. Vaikka alimerkkijonojen haku suffix-taulukon avulla on tyypillisesti hitaampaa kuin suffix-puun kanssa (O(m log n) pituuden m kuviossa), tätä voidaan parantaa O(m) ajaksi apurakenteilla, kuten pisimmän yhteisen etuliitteen (LCP) taulukolla. Suffix-taulukoiden yksinkertaisuus ja pienempi muistijalanjälki tekevät niistä suotuisampia suuren mittakaavan tekstin indeksointi- ja haku tehtäviin.
Tarkempaa vertailua ja lisälukemista varten katso Association for Computing Machinery ja GeeksforGeeks.
Suffix-taulukoiden sovellukset tietojenkäsittelytieteessä
Suffix-taulukot ovat tulleet olennaiseksi tietorakenteeksi tietojenkäsittelytieteessä, erityisesti merkkijonojen käsittelyssä, bioinformatiikassa ja informaation hakemuksessa. Niiden pääasiallinen käyttövoima perustuu tehokkaan kuvioiden etsinnän ja alimerkkijonokyselyjen mahdollistamiseen. Esimerkiksi suffix-taulukkoja käytetään laajasti täysimittaisissa hakukoneissa, joissa ne mahdollistavat nopean tunnistamisen kaikista kyselyalimerkkijonoista suuressa tekstikorpuksessa. Tämä saavutetaan hyödyntämällä leksikografisesti järjestettyjen suffixien järjestystä, joka tukee binäärisen haun operaatioita kuvioiden etsinnässä, jossa on logaritminen aikavaatimuksen Princeton University.
Bioinformatiikassa suffix-taulukot mahdollistavat DNA- ja proteiinisekvenssien vertailun ja kohdistamisen. Työkalut genomin koostamiseen ja sekvenssin kohdistamiseen, kuten seuraavan sukupolven sekvensoinnissa käytettävät, nojaavat usein suffix-tauluihin tehokkaasti käsitellä suuria biologisia tietojoukkoja National Center for Biotechnology Information. Lisäksi suffix-taulukot ovat keskeisiä tietojen pakkausalgoritmeille kuten Burrows-Wheeler-muunnokselle, joka perustaa suosittuja pakkaustyökaluja, kuten bzip2. Tässä suffix-taulukko mahdollistaa syötedatan muuntamisen muotoon, joka on helpompi pakata ryhmittelemällä samankaltaisia merkkejä yhteen bzip2.
Näiden lisäksi suffix-taulukot ovat käytössä plagioinnin havaitsemisessa, tietojen pois suodattamisessa ja tehokkaiden tietorakenteiden rakentamisessa pisimmän yhteisen etuliitteen (LCP) kyselyille. Niiden monipuolisuus ja tehokkuus tekevät niistä korvaamattomia sovelluksissa, joissa tarvitaan nopeaa ja skaalautuvaa merkkijonojen käsittelyä.
Etsinnän ja kuvioiden etsinnän optimointi suffix-taulukoilla
Suffix-taulukot ovat voimakkaita tietorakenteita, jotka optimoivat merkittävästi haku- ja kuvioiden etsintäoperatioita merkkijonoissa. Tallentamalla kaikkien tekstin suffixien aloitusindeksit leksikografisessa järjestyksessä, suffix-taulukot mahdollistavat tehokkaat alimerkkijonokyselyt, jotka ovat perustavanlaatuisia sovelluksissa, kuten täysimittaisessa haussa, bioinformatiikassa ja tietojen pakkaamisessa. Pääasiallinen etu suffix-taulukon käytössä naiiveihin hakumenetelmiin verrattuna on aikavaatimusten väheneminen kuvioiden etsinnässä. Vaikka raaka voima -lähestymistapa saattaa vaatia O(nm) aikaa, jossa merkkijonon pituus on n ja kuvion pituus m, suffix-taulukot mahdollistavat kuvioiden haut O(m + log n) ajassa hyödyntämällä binääristä hakua järjestetyistä suffixista.
Suorituskyvyn parantamiseksi suffix-taulukot käytetään usein yhdessä apurakenteiden, kuten pisimmän yhteisen etuliitteen (LCP) taulukon kanssa. LCP-taulukko tallentaa pisimpien yhteisten etuliitteiden pituudet peräkkäisten suffixien välillä suffix-taulukossa, mikä mahdollistaa vielä nopeammat kuvioiden etsimiset ja helpottaa tehtäviä, kuten erilaisten alimerkkijonojen määrän tai pisimmän toistuvan alimerkkijonon löytämistä lineaarisessa ajassa. Lisäksi modernit algoritmit suffix-taulukoiden rakentamiseen, kuten indusoitu järjestäminen, saavutetaan lineaarisessa aikavaatimuksessa, mikä tekee niistä käytännöllisiä suurten tekstien käsittelyyn (Helsingin yliopisto).
Suffix-taulukot ovat myös muistitehokkaita verrattuna suffix-puihin, koska ne vaativat vain O(n) muistia ja ne on helpompi toteuttaa. Niiden tehokkuus ja monipuolisuus tekevät niistä kulmakivennopean ja skaalautuvan tekstin indeksoinnin ja kuvioiden etsinnän järjestelmissä (Princeton University).
Yleisimmät algoritmit, jotka hyödyntävät suffix-taulukoita
Suffix-taulukot ovat perusrakenne merkkijonojen käsittelyssä, mahdollistaen tehokkaita ratkaisuja erilaisiin monimutkaisiin ongelmiin. useat yleiset algoritmit hyödyntävät suffix-taulukoita saavuttaakseen optimaalista tai lähes optimaalista suorituskykyä erityisesti kuvioiden etsinnässä, tietojen pakkaamisessa ja bioinformatiikassa.
Yksi merkittävimmistä sovelluksista on alimerkkijonojen haku. Yhdistämällä suffix-taulukon binääriseen hakuun voidaan löytää kaikki kuvion esiintymät tekstissä O(m log n) ajassa, missä m on kuvion pituus ja n on tekstin pituus. Tämä lähestymistapa on merkittävästi nopeampi kuin naiivit hakumenetelmät, erityisesti suurissa teksteissä. Lisäksi Pisimmän yhteisen etuliitteen (LCP) taulukko rakennetaan usein samanaikaisesti suffix-taulukon kanssa optimoimaan toistuvia kuvioita ja helpottamaan algoritmeja löytää pisimmän toistuvan alimerkkijonon tai pisimmän yhteisen alimerkkijonon useiden merkkijonojen välillä.
Suffix-taulukot ovat olennaisia tietojen pakkausalgoritmeille, kuten Burrows-Wheeler muunnos (BWT), joka on olennaisin komponentti bzip2-pakkaustyökalussa. BWT nojaa järjestettyjen suffixien järjestykseen järjestääksesi syötedatan, mikä tekee siitä miellyttävämmän pituuskoodeille ja muille pakkaustekniikoille (bzip2).
Bioinformatiikassa suffix-taulukot käytetään tehokkaaseen sekvenssien kohdistamiseen ja genomianalyysiin, joissa nopea haku ja vertailu DNA-sekvensseistä ovat elintärkeitä (National Center for Biotechnology Information). Niiden muistitehokkuus ja nopeus tekevät niistä suositumpia kuin suffix-puut monilla suurilla sovelluksilla.
Suorituskykyratkaisut ja rajoitukset
Suffix-taulukot ovat erittäin tehokkaita tietorakenteita erilaisten merkkijonojen käsittelyn ongelmien, kuten alimerkkijonojen haku, kuvioiden etsinnän ja pisimmän yhteisen etuliitteen laskennan ratkaisemiseen. Kuitenkin niiden suorituskyky ja soveltuvuus riippuvat useista harkintakysymyksistä ja luontaisista rajoituksista.
Yksi tärkeimmistä suorituskykytekijöistä on rakentamisaika. Vaikka naiivit algoritmit suffix-taulukoiden rakentamiseen toimivat O(n log2 n) ajassa, edistyneemmät algoritmit saavuttavat lineaarisen aikavaatimuksen, kuten SA-IS-algoritmi. Kuitenkin nämä optimaaliset algoritmit voivat olla monimutkaisia toteuttaa ja niillä voi olla merkittäviä vakiofaktoreita, jotka voivat vaikuttaa käytännön suorituskykyyn, erityisesti erittäin suurilla teksteillä tai muistin rajoitetuissa ympäristöissä. Muistin monimutkaisuus on myös tärkeä asia; suffix-taulukko vaatii tyypillisesti O(n) muistia, mutta apurakenteet kuten pisimmän yhteisen etuliitteen (LCP) taulukko tai lisäindeksirakenteet voivat lisätä muistinkäyttöä edelleen Helsingin yliopisto.
Suffix-taulukot ovat vähemmän joustavia kuin suffix-puut dynaamisten päivitysten sattuessa, kuten lisäykset tai poisto teksteistä. Suffix-taulukon muuttaminen sen rakentamisen jälkeen ei ole triviaalista ja usein vaatii koko rakenteen uudelleenrakentamisen, mikä tekee siitä vähemmän sopivan sovelluksille, joissa perusteksti muuttuu usein Carnegie Mellon University. Lisäksi, vaikka suffix-taulukot ovat muistitehokkaampia kuin suffix-puut, ne voivat silti olla epäkäytännöllisiä erittäin suurille tietojoukoille, kuten koko genomijaksoille, ilman lisäpakkauksia tai ulkopuolisia muistitaitteita National Center for Biotechnology Information.
Yhteenvetona, vaikka suffix-taulukot tarjoavat merkittäviä etuja nopeudessa ja muistitehokkuudessa staattisille teksteille, niiden rajoituksia dynaamisissa skenaarioissa ja suurilla sovelluksilla on tarkasti harkittava järjestelmän suunnittelussa.
Todelliset käyttöesimerkit ja esimerkit
Suffix-taulukot ovat laajasti käytössä eri käytännön sovelluksissa, jotka vaativat tehokasta merkkijonojen käsittelyä ja kuvioiden etsintää. Yksi merkittävimmistä käyttötapauksista on bioinformatiikassa, erityisesti genomisekvensoinnissa ja analysoinnissa. Työkalut, kuten Burrows-Wheeler Aligner, hyödyntävät suffix-tauluja nopeasti kohdentaa lyhyitä DNA-lukuja viitegenomeihin, mahdollistamalla suuria genomitutkimuksia ja henkilökohtaista lääkintää.
Informaationhakuprosessissa suffix-taulukot ovat keskeisiä toteuttamaan nopeita täysimittaisia hakukoneita. Esimerkiksi Apache Lucene -projekti hyödyntää suffix-tauluja ja niihin liittyviä tietorakenteita tarjotakseen tehokkaita alimerkkijonohakuominaisuuksia, jotka ovat olennaisia suurten tekstikorpusten indeksoimisessa ja kyselyssä.
Suffix-taulukot toimivat myös keskeisessä roolissa tietojen pakkausalgoritmeissa. Esimerkiksi bzip2-pakkaustyökalu käyttää Burrows-Wheeler-muunnosta, joka luottaa suffix-taulukon rakentamisessa syötedatan uudelleenjärjestämiseen ja parantaa pakkauskykyä.
Lisäksi suffix-taulukot ovat käytössä plagioinnin havaitsemisjärjestelmissä, kuten Turnitin, jotka tunnistavat asiakirjojen välisiä samankaltaisuuksia vertaamalla alimerkkijonoja tehokkaasti. Luonnollisen kielen käsittelyssä niitä käytetään tehtävissä, kuten toistuvien lauseiden tunnistamisessa, avainsanojen erottelussa ja concordanssin rakentamisessa.
Nämä esimerkit korostavat suffix-taulukoiden monipuolisuutta ja tehokkuutta suurten mittakaavojen merkkijonojen käsittelytehtävissä eri aloilla, aina laskennallisesta biologiasta hakukoneisiin ja tietojen pakkaamiseen.
Lisälukemista ja edistyneet aiheet
Ne lukijat, jotka ovat kiinnostuneita syventämään tietämystään suffix-taulukoista, voivat tutustua useisiin kehittyneisiin aiheisiin ja resursseihin. Yksi merkittävä alue on parannettujen suffix-taulukoiden tutkimus, jotka laajentavat perusrakennetta lisädatalla, kuten pisimmällä yhteisellä etuliitteellä (LCP) taulukolla, mikä mahdollistaa tehokkaamman kuvioiden etsinnän ja alimerkkijonokyselyt. Suffix-taulukoiden ja suffix-puiden välinen vuorovaikutus on myös rikas kenttä, koska molemmat rakenteet ratkaisevat samankaltaisia ongelmia mutta erilaisilla kauppahinnalla tilasta ja rakentamisaikaa.
Viime aikojen tutkimus on keskittynyt lineaarisen ajan rakentamisalgoritmeihin suffix-taulukoille, kuten SA-IS- ja DC3 (Skew) algoritmeihin, jotka ovat ratkaisevia suurten mittakaavojen geneettisten tai tekstuaalisten tietojen hallinnassa. Näitä algoritmeja käsitellään yksityiskohtaisesti tutkimuksessa, mukaan lukien perusmateriaalit Helsingin yliopiston funktionaaliselta suffix-taulukkoryhmältä.
Suffix-taulukkojen soveltaminen ulottuu merkkijonojen etsinnän lisäksi muihin alueisiin, kuten tietojen pakkaamiseen (esim. Burrows-Wheeler -muunnos), bioinformatiikkaan (genomin koostaminen ja kohdistaminen) ja informaation hakemiseen. Laaja-alaisempaa tietoa varten suositellaan kirjaa Algorithms on Strings, Trees, and Sequences kirjoittanut Dan Gusfield.
- Suffix-taulukot: Uusi menetelmä Online-merkkijonohakuihin (alkuperäinen julkaisu Manberilta ja Myersiltä)
- Lineaarinen ajan suffix-taulukon rakentaminen käyttäen indusoitua järjestämistä (SA-IS algoritmi)
- Wikipedia: Suffix-taulukko (yhteenveto ja lisälinkit)
Lähteet ja viitteet
- American Mathematical Society
- Princeton University
- Helsingin yliopiston tietojenkäsittelytieteen laitos
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Suffix-taulukko