Dominando los Árboles de Sufijos: La Guía Definitiva para el Procesamiento Eficiente de Cadenas y la Búsqueda de Patrones. Descubre Cómo los Árboles de Sufijos Revolucionan los Algoritmos de Texto.
- Introducción a los Árboles de Sufijos
- Cómo Funcionan los Árboles de Sufijos: Conceptos Clave
- Construyendo un Árbol de Sufijos: Paso a Paso
- Árboles de Sufijos vs. Árboles de Sufijos: Diferencias Clave
- Aplicaciones de los Árboles de Sufijos en Ciencias de la Computación
- Optimizando la Búsqueda y la Coincidencia de Patrones con Árboles de Sufijos
- Algoritmos Comunes que Aprovechan los Árboles de Sufijos
- Consideraciones de Rendimiento y Limitaciones
- Casos de Uso y Ejemplos del Mundo Real
- Lecturas Adicionales y Temas Avanzados
- Fuentes y Referencias
Introducción a los Árboles de Sufijos
Un árbol de sufijos es una poderosa estructura de datos utilizada en el procesamiento de cadenas, particularmente para coincidencias de patrones eficientes, consultas de subcadenas y indexación de textos. Representa el orden ordenado de todos los sufijos de una cadena dada, típicamente como un arreglo de índices de inicio. Esta estructura permite una variedad de aplicaciones en campos como bioinformática, compresión de datos y recuperación de información, donde la búsqueda rápida y el análisis de textos grandes son esenciales.
El concepto del árbol de sufijos fue introducido como una alternativa eficiente en espacio al árbol de sufijos, ofreciendo funcionalidades similares pero con una sobrecarga de memoria reducida. A diferencia de los árboles de sufijos, que pueden ser complejos de implementar y mantener, los árboles de sufijos son más simples y compactos, haciéndolos adecuados para tareas de procesamiento de texto a gran escala. La construcción de un árbol de sufijos implica ordenar todos los sufijos posibles de una cadena, lo cual se puede lograr en tiempo O(n log n) utilizando algoritmos basados en comparación, o incluso en tiempo lineal con técnicas más avanzadas como el método de ordenación inducida (Sociedad Matemática Americana).
Los árboles de sufijos se utilizan a menudo junto con estructuras de datos auxiliares como el arreglo del Prefijo Común Más Larga (LCP), que mejora aún más su utilidad para resolver problemas como encontrar la subcadena repetida más larga o realizar comparaciones lexicográficas rápidas. Su eficiencia y versatilidad han convertido a los árboles de sufijos en una herramienta fundamental en el análisis algorítmico moderno de cadenas (Universidad de Princeton).
Cómo Funcionan los Árboles de Sufijos: Conceptos Clave
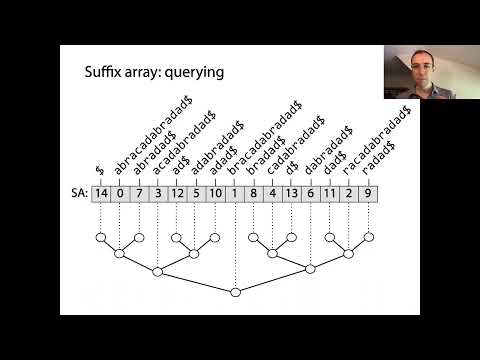
Los árboles de sufijos son estructuras de datos potentes que permiten un procesamiento eficiente de cadenas, particularmente para la búsqueda de patrones y la indexación de textos. En su núcleo, los árboles de sufijos representan el orden ordenado de todos los sufijos posibles de una cadena dada. La construcción comienza generando cada sufijo de la cadena de entrada, comenzando en diferentes posiciones. Estos sufijos se ordenan lexicográficamente, y el árbol de sufijos en sí es un arreglo de enteros, donde cada entrada indica el índice de inicio de un sufijo en este orden ordenado.
El concepto clave detrás de los árboles de sufijos es que, al ordenar todos los sufijos, se pueden realizar búsquedas binarias rápidas para localizar subcadenas o patrones dentro del texto original. Esta es una mejora significativa sobre los métodos de búsqueda ingenuos, que pueden requerir escanear todo el texto para cada consulta. Los árboles de sufijos a menudo se emparejan con el arreglo del Prefijo Común Más Largo (LCP), que almacena las longitudes de los prefijos comunes más largos entre sufijos consecutivos en el arreglo ordenado. Este emparejamiento acelera aún más varias operaciones de cadenas, como encontrar subcadenas repetidas o el número de subcadenas distintas.
Los algoritmos de construcción eficientes, como el método de ordenación inducida o el uso de duplicación de prefijos, han reducido la complejidad temporal de construir árboles de sufijos a tiempo lineal o casi lineal, haciéndolos prácticos para aplicaciones a gran escala. Los árboles de sufijos se utilizan ampliamente en bioinformática, compresión de datos y recuperación de información, donde el procesamiento de cadenas rápido y eficiente en memoria es esencial. Para obtener una visión completa de los principios subyacentes y los algoritmos, consulte la documentación del Departamento de Ciencias de la Computación, Universidad de Helsinki.
Construyendo un Árbol de Sufijos: Paso a Paso
Construir un árbol de sufijos implica construir un arreglo ordenado de todos los sufijos de una cadena dada, representados por sus índices de inicio. El proceso se puede desglosar en varios pasos clave:
- 1. Generar Todos los Sufijos: Para una cadena de longitud n, enumera todos los sufijos por sus posiciones de inicio. Por ejemplo, la cadena «banana» produce sufijos que comienzan en los índices 0 («banana»), 1 («anana»), 2 («nana»), etc.
- 2. Ordenar los Sufijos: Ordena estos sufijos lexicográficamente. Esto se puede hacer ingenuamente en O(n2 log n) tiempo comparando cadenas directamente, pero existen algoritmos más eficientes.
- 3. Almacenar los Índices: En lugar de almacenar las cadenas de sufijos reales, almacena sus índices de inicio en el orden ordenado. Este arreglo de índices es el árbol de sufijos.
- 4. Optimización: Algoritmos avanzados, como el algoritmo Manber-Myers, utilizan una técnica de duplicación para lograr una complejidad de tiempo O(n log n). Aún más rápido, el algoritmo Karkkainen-Sanders (también conocido como el algoritmo Skew) puede construir el árbol de sufijos en tiempo lineal O(n) para alfabetos enteros. Estos métodos dependen de ordenar por rangos y estrategias recursivas para evitar comparaciones directas de cadenas Asociación para la Maquinaria Computacional.
- 5. Salida Final: El árbol de sufijos resultante permite coincidencias eficientes de patrones, consultas de subcadenas, y es fundamental para construir otras estructuras de datos como el arreglo LCP GeeksforGeeks.
Entender cada paso y las optimizaciones disponibles es crucial para aprovechar los árboles de sufijos en aplicaciones de procesamiento de cadenas a gran escala.
Árboles de Sufijos vs. Árboles de Sufijos: Diferencias Clave
Los árboles de sufijos y los árboles de sufijos son estructuras de datos fundamentales para el procesamiento eficiente de cadenas, particularmente en aplicaciones como coincidencias de patrones, bioinformática y compresión de datos. Aunque sirven propósitos similares, sus estructuras, requisitos de memoria y características operativas difieren significativamente.
Un árbol de sufijos es un trie comprimido de todos los sufijos de una cadena dada, lo que permite consultas de subcadenas extremadamente rápidas, generalmente en tiempo lineal en relación con la longitud del patrón. Sin embargo, los árboles de sufijos son complejos de implementar y requieren una sobrecarga de memoria considerable, a menudo varias veces el tamaño de la cadena original, debido a su estructura basada en nodos y la necesidad de almacenar punteros y etiquetas de borde. Esto los hace menos prácticos para conjuntos de datos muy grandes o entornos restringidos en memoria.
En contraste, un árbol de sufijos es una estructura de datos mucho más simple y eficiente en espacio. Consiste en un arreglo de enteros que representan las posiciones de inicio de todos los sufijos ordenados de la cadena. Los árboles de sufijos se pueden construir en tiempo lineal y requieren solo O(n) espacio, donde n es la longitud de la cadena. Aunque las búsquedas de subcadenas utilizando un árbol de sufijos son típicamente más lentas que con un árbol de sufijos (O(m log n) para un patrón de longitud m), esto se puede mejorar a O(m) con estructuras de datos auxiliares como el arreglo del Prefijo Común Más Largo (LCP). La simplicidad y menor huella de memoria de los árboles de sufijos los hacen preferibles para indexación y búsqueda de texto a gran escala.
Para una comparación detallada y más lecturas, consulte Asociación para la Maquinaria Computacional y GeeksforGeeks.
Aplicaciones de los Árboles de Sufijos en Ciencias de la Computación
Los árboles de sufijos se han convertido en una estructura de datos fundamental en ciencias de la computación, particularmente en los campos del procesamiento de cadenas, bioinformática y recuperación de información. Su utilidad principal radica en permitir coincidencias eficientes de patrones y consultas de subcadenas. Por ejemplo, los árboles de sufijos se utilizan ampliamente en motores de búsqueda de texto completo, donde permiten la identificación rápida de todas las ocurrencias de una subcadena de consulta dentro de un gran corpus de texto. Esto se logra aprovechando el orden lexicográficamente ordenado de los sufijos, que facilita operaciones de búsqueda binaria para la coincidencia de patrones en una complejidad de tiempo logarítmica Universidad de Princeton.
En bioinformática, los árboles de sufijos facilitan la alineación y comparación de secuencias de ADN y proteínas. Herramientas para ensamblaje de genomas y alineación de secuencias, como las utilizadas en secuenciación de nueva generación, a menudo dependen de los árboles de sufijos para manejar eficazmente enormes conjuntos de datos biológicos Centro Nacional de Información Biotecnológica. Además, los árboles de sufijos son integrales a algoritmos de compresión de datos como la Transformación de Burrows-Wheeler, que subyacen a herramientas de compresión populares como bzip2. Aquí, el árbol de sufijos permite la transformación de los datos de entrada en una forma más propensa a la compresión al agrupar caracteres similares.
Más allá de esto, los árboles de sufijos también se utilizan en detección de plagio, deduplicación de datos y la construcción de estructuras de datos eficaces para consultas de prefijo común más largo (LCP). Su versatilidad y eficiencia los hacen indispensables en aplicaciones donde se requiere un procesamiento rápido y escalable de cadenas.
Optimizando la Búsqueda y la Coincidencia de Patrones con Árboles de Sufijos
Los árboles de sufijos son estructuras de datos potentes que optimizan significativamente las operaciones de búsqueda y coincidencia de patrones en cadenas. Al almacenar los índices de inicio de todos los sufijos de un texto en orden lexicográfico, los árboles de sufijos permiten consultas de subcadenas eficientes, que son fundamentales en aplicaciones como búsqueda de texto completo, bioinformática y compresión de datos. La principal ventaja de usar un árbol de sufijos sobre los métodos de búsqueda ingenuos es la reducción en la complejidad temporal para la coincidencia de patrones. Mientras que un enfoque de fuerza bruta puede requerir O(nm) tiempo para un texto de longitud n y un patrón de longitud m, los árboles de sufijos permiten búsquedas de patrones en O(m + log n) tiempo al aprovechar la búsqueda binaria en los sufijos ordenados.
Para mejorar aún más el rendimiento, los árboles de sufijos a menudo se utilizan junto con estructuras de datos auxiliares como el arreglo del Prefijo Común Más Largo (LCP). El arreglo LCP almacena las longitudes de los prefijos comunes más largos entre sufijos consecutivos en el árbol de sufijos, lo que permite coincidencias de patrones aún más rápidas y facilita tareas como encontrar el número de subcadenas distintas o la subcadena repetida más larga en tiempo lineal. Además, los algoritmos modernos para construir árboles de sufijos, como el método de ordenación inducida, logran complejidad temporal lineal, haciéndolos prácticos para textos a gran escala (Universidad de Helsinki).
Los árboles de sufijos también son eficientes en espacio en comparación con los árboles de sufijos, ya que requieren solo O(n) espacio y son más fáciles de implementar. Su eficiencia y versatilidad los convierten en una piedra angular en el diseño de sistemas de indexación de texto rápidos y escalables y coincidencia de patrones (Universidad de Princeton).
Algoritmos Comunes que Aprovechan los Árboles de Sufijos
Los árboles de sufijos son una estructura de datos fundamental en el procesamiento de cadenas, que permiten soluciones eficientes a una variedad de problemas complejos. Varios algoritmos comunes aprovechan los árboles de sufijos para lograr un rendimiento óptimo o casi óptimo, particularmente en los dominios de coincidencia de patrones, compresión de datos y bioinformática.
Una de las aplicaciones más prominentes es en búsqueda de subcadenas. Al combinar un árbol de sufijos con una búsqueda binaria, es posible localizar todas las ocurrencias de un patrón en un texto en O(m log n) tiempo, donde m es la longitud del patrón y n es la longitud del texto. Este enfoque es significativamente más rápido que los métodos de búsqueda ingenuos, especialmente para textos grandes. Además, el arreglo del Prefijo Común Más Largo (LCP) a menudo se construye junto con el árbol de sufijos para optimizar aún más las consultas de patrones repetidos y facilitar algoritmos para encontrar la subcadena repetida más larga o la subcadena común más larga entre varias cadenas.
Los árboles de sufijos también son integrales a algoritmos de compresión de datos como la Transformación de Burrows-Wheeler (BWT), que es un componente clave de la herramienta de compresión bzip2. La BWT depende del orden ordenado de los sufijos para reordenar el texto de entrada, haciéndolo más propenso a la codificación de longitud de carrera y otras técnicas de compresión (bzip2).
En bioinformática, los árboles de sufijos se utilizan para la alineación de secuencias y análisis genómico eficientes, donde la búsqueda y comparación rápidas de secuencias de ADN son esenciales (Centro Nacional de Información Biotecnológica). Su eficiencia en espacio y velocidad los hace preferibles frente a los árboles de sufijos en muchas aplicaciones a gran escala.
Consideraciones de Rendimiento y Limitaciones
Los árboles de sufijos son estructuras de datos altamente eficientes para resolver una variedad de problemas de procesamiento de cadenas, como búsqueda de subcadenas, coincidencia de patrones y el cálculo del prefijo común más largo. Sin embargo, su rendimiento y aplicabilidad están influenciados por varias consideraciones y limitaciones inherentes.
Uno de los principales factores de rendimiento es el tiempo de construcción. Mientras que los algoritmos ingenuos para construir árboles de sufijos operan en O(n log2 n) tiempo, algoritmos más avanzados logran complejidad temporal lineal, como el algoritmo SA-IS. Sin embargo, estos algoritmos óptimos pueden ser complejos de implementar y pueden tener factores constantes significativos, lo que puede afectar el rendimiento práctico, especialmente para textos muy grandes o en entornos restringidos en memoria. La complejidad espacial es otro aspecto importante; un árbol de sufijos típicamente requiere O(n) espacio, pero estructuras auxiliares como el arreglo del Prefijo Común Más Largo (LCP) o estructuras de indexación adicionales pueden aumentar aún más el uso de memoria Universidad de Helsinki.
Los árboles de sufijos son menos flexibles que los árboles de sufijos cuando se trata de actualizaciones dinámicas, tales como inserciones o eliminaciones dentro del texto. Modificar un árbol de sufijos después de su construcción no es trivial y a menudo requiere reconstruir toda la estructura, haciéndolo menos adecuado para aplicaciones donde el texto subyacente cambia con frecuencia Universidad Carnegie Mellon. Además, aunque los árboles de sufijos son más eficientes en espacio que los árboles de sufijos, pueden seguir siendo poco prácticos para conjuntos de datos extremadamente grandes, como secuencias genómicas completas, sin técnicas de compresión adicionales o memoria externa Centro Nacional de Información Biotecnológica.
En resumen, aunque los árboles de sufijos ofrecen ventajas significativas en términos de velocidad y eficiencia en memoria para textos estáticos, sus limitaciones en escenarios dinámicos y aplicaciones a gran escala deben ser cuidadosamente consideradas durante el diseño del sistema.
Casos de Uso y Ejemplos del Mundo Real
Los árboles de sufijos se utilizan ampliamente en diversas aplicaciones del mundo real que requieren procesamiento eficiente de cadenas y coincidencia de patrones. Uno de los casos de uso más prominentes es en bioinformática, particularmente en secuenciación y análisis de genomas. Herramientas como el Alineador de Burrows-Wheeler utilizan árboles de sufijos para alinear rápidamente lecturas cortas de ADN a genomas de referencia, lo que permite estudios genómicos a gran escala y medicina personalizada.
En recuperación de información, los árboles de sufijos son fundamentales para implementar motores de búsqueda de texto completo rápidos. Por ejemplo, el proyecto Apache Lucene utiliza árboles de sufijos y estructuras de datos relacionadas para proporcionar capacidades eficientes de búsqueda de subcadenas, que son esenciales para indexar y consultar grandes corpus de texto.
Los árboles de sufijos también juegan un papel crucial en algoritmos de compresión de datos. La herramienta de compresión bzip2, por ejemplo, utiliza la Transformación de Burrows-Wheeler, que depende de la construcción de un árbol de sufijos para reordenar los datos de entrada y mejorar la compresibilidad.
Además, los árboles de sufijos se emplean en sistemas de detección de plagio, como Turnitin, para identificar similitudes entre documentos al comparar eficientemente subcadenas. En el procesamiento del lenguaje natural, se utilizan para tareas como identificar frases repetidas, extraer palabras clave y construir concordancias.
Estos ejemplos destacan la versatilidad y eficiencia de los árboles de sufijos en el manejo de tareas de procesamiento de cadenas a gran escala en diversos dominios, desde biología computacional hasta motores de búsqueda y compresión de datos.
Lecturas Adicionales y Temas Avanzados
Para los lectores interesados en profundizar en los árboles de sufijos, hay varios temas avanzados y recursos disponibles. Un área significativa es el estudio de los árboles de sufijos mejorados, que aumentan la estructura básica con datos adicionales como el arreglo del Prefijo Común Más Largo (LCP), lo que permite coincidencias de patrones y consultas de subcadenas más eficientes. La interacción entre los árboles de sufijos y los árboles de sufijos también es un campo rico, ya que ambas estructuras resuelven problemas similares pero con diferentes compensaciones en términos de espacio y tiempo de construcción.
La investigación reciente se ha centrado en algoritmos de construcción en tiempo lineal para árboles de sufijos, como los algoritmos SA-IS y DC3 (Skew), que son cruciales para manejar datos genómicos o textuales a gran escala. Estos algoritmos se discuten en detalle en la literatura, incluyendo el trabajo fundamental de Grupo Funcional de Árboles de Sufijos de la Universidad de Helsinki.
Las aplicaciones de los árboles de sufijos se extienden más allá de la coincidencia de cadenas a áreas como la compresión de datos (por ejemplo, la Transformación de Burrows-Wheeler), bioinformática (ensamblaje y alineación de genomas) y recuperación de información. Para obtener una visión completa, se recomienda el libro Algoritmos en Cadenas, Árboles y Secuencias de Dan Gusfield.
- Árboles de Sufijos: Un Nuevo Método para Búsquedas en Línea de Cadenas (artículo original por Manber & Myers)
- Construcción de Árboles de Sufijos en Tiempo Lineal Utilizando Ordenación Inducida (algoritmo SA-IS)
- Wikipedia: Árbol de Sufijos (visión general y enlaces adicionales)
Fuentes y Referencias
- Sociedad Matemática Americana
- Universidad de Princeton
- Departamento de Ciencias de la Computación, Universidad de Helsinki
- GeeksforGeeks
- Centro Nacional de Información Biotecnológica
- Universidad Carnegie Mellon
- Apache Lucene
- Turnitin
- Algoritmos en Cadenas, Árboles y Secuencias
- Wikipedia: Árbol de Sufijos