Mestring af Suffiks Arrays: Den Ultimative Guide til Effektiv Strengbehandling og Mønster Matching. Opdag Hvordan Suffiks Arrays Revolutionerer Tekstalgoritmer.
- Introduktion til Suffiks Arrays
- Hvordan Suffiks Arrays Fungerer: Grundlæggende Begreber
- Bygning af et Suffiks Array: Trin-for-Trin
- Suffiks Arrays vs. Suffiks Træer: Nøgleforskelle
- Anvendelser af Suffiks Arrays i Datalogi
- Optimering af Søgning og Mønster Matching med Suffiks Arrays
- Fælles Algoritmer der Udnytter Suffiks Arrays
- Ydelsesovervejelser og Begrænsninger
- Virkelige Brugssager og Eksempler
- Yderligere Læsning og Avancerede Emner
- Kilder & Referencer
Introduktion til Suffiks Arrays
Et suffiks array er en kraftfuld datastruktur, der bruges inden for strengbehandling, især til effektiv mønster matching, understrengs forespørgsler og tekstindeksering. Det repræsenterer den sorterede rækkefølge af alle suffikser af en given streng, typisk som et array af startindekser. Denne struktur muliggør en række anvendelser inden for felter som bioinformatik, datakompression og informationshentning, hvor hurtig søgning og analyse af store tekster er afgørende.
Konceptet med suffiks array blev introduceret som et pladsbesparende alternativ til suffiks træet, der tilbyder lignende funktionaliteter, men med reduceret hukommelsesoverhead. I modsætning til suffiks træer, som kan være komplekse at implementere og vedligeholde, er suffiks arrays simplere og mere kompakte, hvilket gør dem egnede til storskala tekstbehandlingsopgaver. Konstruktionen af et suffiks array involverer sortering af alle mulige suffikser af en streng, hvilket kan opnås på O(n log n) tid ved hjælp af komparationsbaserede algoritmer, eller endda på lineær tid med mere avancerede teknikker som den inducerede sorteringsmetode (American Mathematical Society).
Suffiks arrays bruges ofte sammen med hjælpestrukturer som Longest Common Prefix (LCP) array, som yderligere forbedrer deres nytte til at løse problemer som at finde den længste gentagne understreng eller udføre hurtige leksikografiske sammenligninger. Deres effektivitet og alsidighed har gjort suffiks arrays til et grundlæggende værktøj i moderne algoritmisk strenganalyse (Princeton University).
Hvordan Suffiks Arrays Fungerer: Grundlæggende Begreber
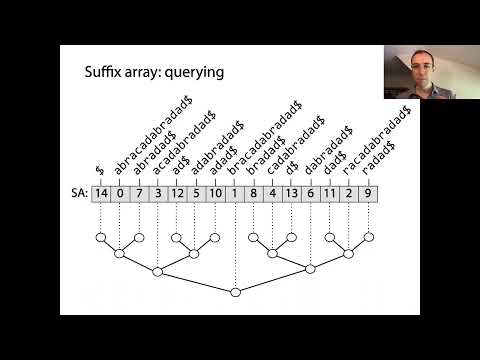
Suffiks arrays er kraftfulde datastrukturer, der muliggør effektiv strengbehandling, især til mønster matching og tekstindeksering. I sin kerne repræsenterer suffiks arrays den sorterede rækkefølge af alle mulige suffikser af en given streng. Konstruktionen begynder med at genere hvert suffiks af inputstrengen, hver startende på en anden position. Disse suffikser bliver derefter sorteret leksikografisk, og selve suffiks arrayet er et array af heltal, hvor hver indgang angiver startindekset for et suffiks i denne sorterede rækkefølge.
Det centrale koncept bag suffiks arrays er, at ved at sortere alle suffikser kan man udføre hurtige binære søgninger for at lokalisere understrenge eller mønstre inden for den oprindelige tekst. Dette er en betydelig forbedring i forhold til naive søgemetoder, som kan kræve at scanne hele teksten for hver forespørgsel. Suffiks arrays parres ofte med Longest Common Prefix (LCP) arrayet, som gemmer længderne af de længste fælles præfikser mellem på hinanden følgende suffikser i den sorterede array. Denne parring accelererer yderligere forskellige strengoperationer, såsom at finde gentagne understrenge eller antallet af distinkte understrenge.
Effektive konstruktionsalgoritmer, såsom den inducerede sorteringsmetode eller brugen af præfiks fordobling, har reduceret tidskompleksiteten af at bygge suffiks arrays til lineær eller næsten lineær tid, hvilket gør dem praktiske til storskala anvendelser. Suffiks arrays bruges vidt inden for bioinformatik, datakompression og informationshentning, hvor hurtig og hukommelseseffektiv strengbehandling er essentiel. For en omfattende oversigt over de underliggende principper og algoritmer, henvises der til dokumentationen fra Institut for Datalogi, Københavns Universitet.
Bygning af et Suffiks Array: Trin-for-Trin
At bygge et suffiks array involverer at konstruere et sorterede array af alle suffikser af en given streng, repræsenteret ved deres startindekser. Processen kan opdeles i flere nøgletrin:
- 1. Generer Alle Suffikser: For en streng af længde n, opregn alle suffikser efter deres startpositioner. For eksempel giver strengen “banana” suffikser, der starter ved indeks 0 (“banana”), 1 (“anana”), 2 (“nana”) og så videre.
- 2. Sorter Suffikserne: Sorter disse suffikser leksikografisk. Dette kan gøres naivt på O(n2 log n) tid ved at sammenligne strenge direkte, men der findes mere effektive algoritmer.
- 3. Gem Indekserne: I stedet for at gemme de faktiske suffiksstrenge, gem deres startindekser i den sorterede rækkefølge. Dette array af indekser er suffiks arrayet.
- 4. Optimering: Avancerede algoritmer, såsom Manber-Myers-algoritmen, bruger en fordoblingsteknik for at opnå O(n log n) tidskompleksitet. Endda hurtigere kan Karkkainen-Sanders-algoritmen (også kendt som Skew-algoritmen) konstruere suffiks arrayet på lineær tid O(n) for heltalsalfabeter. Disse metoder er baseret på sortering ved rang og rekursive strategier for at undgå direkte strengsammenligninger Association for Computing Machinery.
- 5. Endelig Output: Det resulterende suffiks array muliggør effektiv mønster matching, understrengs forespørgsler og er grundlæggende for at konstruere andre datastrukturer som LCP arrayet GeeksforGeeks.
At forstå hvert trin og de tilgængelige optimeringer er afgørende for at udnytte suffiks arrays i storskala strengbehandlingsapplikationer.
Suffiks Arrays vs. Suffiks Træer: Nøgleforskelle
Suffiks arrays og suffiks træer er begge grundlæggende datastrukturer for effektiv strengbehandling, især i applikationer som mønster matching, bioinformatik og datakompression. Selvom de tjener lignende formål, adskiller deres strukturer, hukommelseskrav og operationelle karakteristika sig betydeligt.
Et suffiks træ er en komprimeret trie af alle suffikserne af en given streng, hvilket muliggør ekstremt hurtige understrengs forespørgsler, typisk i lineær tid i forhold til mønster længden. Men suffiks træer er komplekse at implementere og kræver betydelig hukommelsesoverhead—ofte flere gange størrelsen af den oprindelige streng—på grund af deres nodebaserede struktur og behovet for at gemme pegepunkter og kantetiketter. Dette gør dem mindre praktiske for meget store datasæt eller hukommelsesbegrænsede miljøer.
I kontrast er et suffiks array en meget simplere og mere pladsbesparende datastruktur. Det består af et array af heltal, der repræsenterer startpositionerne af alle sorterede suffikser af strengen. Suffiks arrays kan konstrueres på lineær tid og kræver kun O(n) plads, hvor n er længden af strengen. Selvom understrengs søgninger ved brug af et suffiks array typisk er langsommere end med et suffiks træ (O(m log n) for et mønster af længde m), kan dette forbedres til O(m) med hjælpe datastrukturer som Longest Common Prefix (LCP) arrayet. Enkelheden og den lavere hukommelsesbelastning af suffiks arrays gør dem at foretrække til storskala tekstindeksering og søgeopgaver.
For en detaljeret sammenligning og yderligere læsning, se Association for Computing Machinery og GeeksforGeeks.
Anvendelser af Suffiks Arrays i Datalogi
Suffiks arrays er blevet en grundlæggende datastruktur i datalogi, især inden for felterne strengbehandling, bioinformatik og informationshentning. Deres primære nytte ligger i at muliggøre effektiv mønster matching og understrengs forespørgsler. For eksempel er suffiks arrays vidt brugt i fuldtekst søgemaskiner, hvor de muliggør hurtig identifikation af alle forekomster af en forespørgselsunderstreng inden for en stor tekstsamling. Dette opnås ved at udnytte den leksikografisk sorterede rækkefølge af suffikserne, som understøtter binære søge operationer til mønster matching i logaritmisk tidskompleksitet Princeton University.
I bioinformatik letter suffiks arrays justeringen og sammenligningen af DNA- og proteinsekvenser. Værktøjer til genommontering og sekvensjustering, såsom dem der bruges i næste generations sekventering, er ofte afhængige af suffiks arrays for effektivt at håndtere massive biologiske datasæt National Center for Biotechnology Information. Derudover er suffiks arrays integrale til datakompressionsalgoritmer som Burrows-Wheeler Transform, som understøtter populære komprimeringsværktøjer som bzip2. Her muliggør suffiks arrayet transformationen af inputdata til en form, der er mere modtagelig for kompression ved at samle lignende tegn sammen bzip2.
Udover disse anvendes suffiks arrays også i plagiatkontrol, datadulcering og konstruktion af effektive datastrukturer til længste fælles præfiks (LCP) forespørgsler. Deres alsidighed og effektivitet gør dem uundgåelige i applikationer, hvor hurtig og skalerbar strengbehandling er nødvendig.
Optimering af Søgning og Mønster Matching med Suffiks Arrays
Suffiks arrays er kraftfulde datastrukturer, der betydeligt optimerer søge- og mønster matching operationer i strenge. Ved at gemme startindekserne for alle suffikser af en tekst i leksikografisk rækkefølge muliggør suffiks arrays effektive understrengs forespørgsler, som er grundlæggende i applikationer som fuldtekst søgning, bioinformatik og datakompression. Den primære fordel ved at bruge et suffiks array frem for naive søgemetoder er reduktionen i tidskompleksiteten til mønster matching. Mens en brute-force tilgang kan kræve O(nm) tid for en tekst af længde n og et mønster af længde m, muliggør suffiks arrays mønster søgninger på O(m + log n) tid ved at udnytte binære søgninger på de sorterede suffikser.
For yderligere at forbedre ydelsen bruges suffiks arrays ofte sammen med hjælpestrukturer som Longest Common Prefix (LCP) arrayet. LCP arrayet gemmer længderne af de længste fælles præfikser mellem på hinanden følgende suffikser i suffiks arrayet, hvilket muliggør endnu hurtigere mønster matching og letter opgaver som at finde antallet af distinkte understrenge eller den længste gentagne understreng i lineær tid. Derudover opnår moderne algoritmer til konstruktion af suffiks arrays, såsom den inducerede sorteringsmetode, lineær tidskompleksitet, hvilket gør dem praktiske til store tekster (University of Helsinki).
Suffiks arrays er også pladsbesparende i forhold til suffiks træer, da de kun kræver O(n) plads og er lettere at implementere. Deres effektivitet og alsidighed gør dem til en grundpille i designet af hurtige og skalerbare tekstindeksering og mønster matching systemer (Princeton University).
Fælles Algoritmer der Udnytter Suffiks Arrays
Suffiks arrays er en grundlæggende datastruktur i strengbehandling, der muliggør effektive løsninger på en række komplekse problemer. Flere almindelige algoritmer udnytter suffiks arrays for at opnå optimal eller næsten optimal ydeevne, især inden for domænerne mønster matching, datakompression og bioinformatik.
En af de mest fremtrædende anvendelser er i understrengs søgning. Ved at kombinere et suffiks array med en binær søgning, er det muligt at lokalisere alle forekomster af et mønster i en tekst på O(m log n) tid, hvor m er mønster længden, og n er tekst længden. Denne tilgang er betydeligt hurtigere end naive søgemetoder, især for store tekster. Derudover konstrueres Longest Common Prefix (LCP) arrayet ofte sideløbende med suffiks arrayet for at optimere gentagne mønster forespørgsler yderligere og lette algoritmer til at finde den længste gentagne understreng eller den længste fælles understreng mellem flere strenge.
Suffiks arrays er også integrale til datakompressionsalgoritmer såsom Burrows-Wheeler Transform (BWT), som er en nøglekomponent i bzip2 komprimeringsværktøjet. BWT er afhængig af den sorterede rækkefølge af suffikser til at omarrangere inputteksten, hvilket gør den mere modtagelig for run-length kodning og andre kompressionsteknikker (bzip2).
I bioinformatik bruges suffiks arrays til effektiv sekvensjustering og genom analyse, hvor hurtig søgning og sammenligning af DNA-sekvenser er afgørende (National Center for Biotechnology Information). Deres plads effektivitet og hastighed gør dem at foretrække frem for suffiks træer i mange storskala anvendelser.
Ydelsesovervejelser og Begrænsninger
Suffiks arrays er meget effektive datastrukturer til at løse en række stringbehandlingsproblemer, såsom understrengsøgning, mønster matching og beregningen af den længste fælles præfiks. Men deres ydeevne og anvendelighed påvirkes af flere overvejelser og iboende begrænsninger.
En af de primære ydeevne faktorer er konstruktionstiden. Mens naive algoritmer til at bygge suffiks arrays opererer i O(n log2 n) tid, opnår mere avancerede algoritmer lineær tidskompleksitet, såsom SA-IS algoritmen. Ikke desto mindre kan disse optimale algoritmer være komplekse at implementere og kan have betydelige konstantfaktorer, som kan påvirke den praktiske ydeevne, især for meget store tekster eller i hukommelsesbegrænsede miljøer. Plads kompleksiteten er et andet vigtigt aspekt; et suffiks array kræver typisk O(n) plads, men hjælpe strukturer som Longest Common Prefix (LCP) arrayet eller yderligere indeksstrukturer kan øge hukommelsesforbruget yderligere University of Helsinki.
Suffiks arrays er mindre fleksible end suffiks træer, når det kommer til dynamiske opdateringer, såsom indsatser eller sletninger inden for teksten. At ændre et suffiks array efter dets konstruktion er ikke trivielt og kræver ofte at hele strukturen skal genopbygges, hvilket gør det mindre egnet til applikationer, hvor den underliggende tekst ændres hyppigt Carnegie Mellon University. Derudover, mens suffiks arrays er mere plads effektive end suffiks træer, kan de stadig være upraktiske for ekstremt store datasæt, såsom hele genomsekvenser, uden yderligere kompression eller eksterne hukommelsesteknikker National Center for Biotechnology Information.
Sammenfattende, mens suffiks arrays tilbyder betydelige fordele med hensyn til hastighed og hukommelseseffektivitet for statiske tekster, skal deres begrænsninger i dynamiske scenarier og storskala anvendelser overvejes omhyggeligt under systemdesign.
Virkelige Brugssager og Eksempler
Suffiks arrays bruges i vid udstrækning i forskellige virkelige applikationer, der kræver effektiv strengbehandling og mønster matching. En af de mest fremtrædende anvendelser er inden for bioinformatik, især i genom sekventering og analyse. Værktøjer som Burrows-Wheeler Aligner udnytter suffiks arrays til hurtigt at justere korte DNA-læs til referencegenomer, hvilket muliggør storskala genomstudier og personlig medicin.
I informationshentning er suffiks arrays grundlæggende for at implementere hurtige fuldtekst søgemaskiner. For eksempel udnytter Apache Lucene projektet suffiks arrays og relaterede datastrukturer for at tilbyde effektive understrengs søgemuligheder, hvilket er essentielt for indeksering og forespørgsel af store tekstsamlinger.
Suffiks arrays spiller også en afgørende rolle i datakompressionsalgoritmer. Bzip2 komprimeringsværktøjet bruger for eksempel Burrows-Wheeler Transform, som er afhængig af konstruktionen af et suffiks array for at omarrangere inputdata og forbedre kompressibiliteten.
Derudover anvendes suffiks arrays i plagiatdetekteringssystemer, såsom Turnitin, til at identificere ligheder mellem dokumenter ved effektivt at sammenligne understrenge. I natural language processing bruges de til opgaver som at identificere gentagne sætninger, udtrække nøgleord og bygge koncordancer.
Disse eksempler understreger alsidigheden og effektiviteten af suffiks arrays i håndteringen af storskalale stringbehandlingsopgaver på tværs af forskellige domæner, fra beregningsbiologi til søgemaskiner og datakompression.
Yderligere Læsning og Avancerede Emner
For læsere der er interesserede i at dykke dybere ned i suffiks arrays, er der flere avancerede emner og ressourcer tilgængelige. Et væsentligt område er studiet af forbedrede suffiks arrays, som udvider den grundlæggende struktur med yderligere data såsom Longest Common Prefix (LCP) arrayet, hvilket muliggør mere effektiv mønster matching og understrengs forespørgsler. Samspillet mellem suffiks arrays og suffiks træer er også et rigt felt, da begge strukturer løser lignende problemer, men med forskellige afvejninger med hensyn til plads og konstruktionstid.
Nylige forskningsfokuser har været på lineære konstruktionsalgoritmer for suffiks arrays, såsom SA-IS og DC3 (Skew) algoritmerne, som er afgørende for håndtering af storskala genomiske eller tekstuelle data. Disse algoritmer diskuteres i detaljer i litteraturen, herunder det grundlæggende arbejde af University of Helsinki Functional Suffix Array Group.
Anvendelser af suffiks arrays strækker sig ud over string matching til områder som datakompression (f.eks. Burrows-Wheeler Transform), bioinformatik (genom montering og justering) og informationshentning. For en omfattende oversigt anbefales bogen Algorithms on Strings, Trees, and Sequences af Dan Gusfield.
- Suffiks Arrays: En Ny Metode til Online String Søgninger (oprindelig artikel af Manber & Myers)
- Lineær Tids Suffiks Array Konstruktionsmetode ved Brug af Induceret Sortering (SA-IS algoritmen)
- Wikipedia: Suffiks Array (oversigt og videre links)
Kilder & Referencer
- American Mathematical Society
- Princeton University
- Institut for Datalogi, Universitetet i Helsinki
- GeeksforGeeks
- National Center for Biotechnology Information
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algorithms on Strings, Trees, and Sequences
- Wikipedia: Suffiks Array