Ovládání suffixových polí: Konečný průvodce efektivním zpracováním řetězců a shodovým vyhledáváním. Objevte, jak suffixová pole revolucionalizují textové algoritmy.
- Úvod do suffixových polí
- Jak fungují suffixová pole: Základní koncepty
- Tvorba suffixového pole: Krok za krokem
- Suffixová pole vs. Suffixové stromy: Klíčové rozdíly
- Aplikace suffixových polí v informatice
- Optimalizace vyhledávání a shodového porovnání pomocí suffixových polí
- Běžné algoritmy vycházející ze suffixových polí
- Úvahy o výkonu a omezení
- Případové studie a příklady z reálného světa
- Další čtení a pokročilá témata
- Zdroje & Odkazy
Úvod do suffixových polí
Suffixové pole je mocná datová struktura používaná při zpracování řetězců, zejména pro efektivní shodové vyhledávání, dotazy na podřetězce a indexaci textu. Reprezentuje seřazený pořádek všech suffixů daného řetězce, typicky jako pole počátečních indexů. Tato struktura umožňuje široké spektrum aplikací v oborech jako je bioinformatika, datová komprese a vyhledávání informací, kde je rychlé vyhledávání a analýza velkých textů zásadní.
Koncept suffixového pole byl zaveden jako prostorově efektivní alternativa k suffixovému stromu, nabízející podobné funkce, ale se sníženými nároky na paměť. Na rozdíl od suffixových stromů, které mohou být komplikované na implementaci a údržbu, jsou suffixová pole jednodušší a kompaktnější, což je činí vhodnými pro úkoly zpracování velkého objemu textu. Konstrukce suffixového pole zahrnuje seřazení všech možných suffixů řetězce, což lze dosáhnout v O(n log n) čase pomocí algoritmů založených na porovnávání, nebo dokonce v lineárním čase s pokročilejšími technikami, jako je metoda indukovaného řazení (Americká matematická společnost).
Suffixová pole se často používají ve spojení s pomocnými datovými struktury, jako je pole nejdelších společných prefixů (LCP), které dále zvyšují jejich užitečnost při řešení problémů, jako je nalezení nejdelšího opakujícího se podřetězce nebo provádění rychlých lexikografických porovnání. Jejich efektivita a univerzálnost učinily suffixová pole základním nástrojem v moderní algoritmické analýze řetězců (Princetonova univerzita).
Jak fungují suffixová pole: Základní koncepty
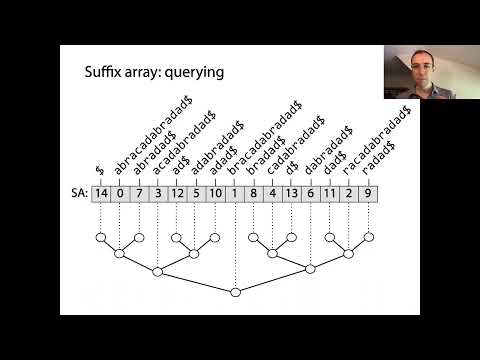
Suffixová pole jsou mocné datové struktury, které umožňují efektivní zpracování řetězců, zejména pro shodové vyhledávání a indexaci textu. V jejich jádru suffixová pole reprezentují seřazený pořádek všech možných suffixů daného řetězce. Konstrukce začíná generováním každého suffixu vstupního řetězce, každý začíná na jiné pozici. Tyto suffixy se poté řadí lexikograficky a samotné suffixové pole je pole celých čísel, kde každý záznam označuje počáteční index suffixu v tomto seřazeném pořadí.
Klíčovým konceptem suffixových polí je, že seřazením všech suffixů lze provádět rychlé binární vyhledávání za účelem lokalizace podřetězců nebo vzorů v původním textu. To představuje významné zlepšení oproti naivním metodám vyhledávání, které mohou vyžadovat procházení celého textu pro každý dotaz. Suffixová pole se často kombinují s polem nejdelších společných prefixů (LCP), které uchovává délky nejdelších společných prefixů mezi po sobě jdoucími suffixy v seřazeném poli. Tato kombinace dále urychluje různé operace se řetězci, jako je hledání opakovaných podřetězců nebo počet různých podřetězců.
Efektivní konstrukční algoritmy, jako je metoda indukovaného řazení nebo použití dvojitého prefixu, snížily časovou složitost konstrukce suffixových polí na lineární nebo téměř lineární čas, což je činí praktickými pro aplikace velkého rozsahu. Suffixová pole se široce používají v bioinformatice, datové kompresi a vyhledávání informací, kde je rychlé a paměťově efektivní zpracování řetězců nezbytné. Pro komplexní přehled základních principů a algoritmů se podívejte na dokumentaci od Katedry informatiky Univerzity Helsinky.
Tvorba suffixového pole: Krok za krokem
Tvorba suffixového pole zahrnuje konstrukci seřazeného pole všech suffixů daného řetězce, které jsou reprezentovány jejich počátečními indexy. Proces lze rozdělit do několika klíčových kroků:
- 1. Vytvořte všechny suffixy: Pro řetězec délky n enumerujte všechny suffixy podle jejich počátečních pozic. Například řetězec „banana“ vyprodukuje suffixy začínající na indexech 0 („banana“), 1 („anana“), 2 („nana“) a tak dále.
- 2. Řaďte suffixy: Seřaďte tyto suffixy lexikograficky. To lze udělat naivně za O(n2 log n) času přímo srovnáváním řetězců, ale existují i efektivnější algoritmy.
- 3. Uložte indexy: Místo toho, abyste ukládali skutečné suffixové řetězce, uložte jejich počáteční indexy v seřazeném pořadí. Toto pole indexů je suffixové pole.
- 4. Optimalizace: Pokročilé algoritmy, jako je Manber-Myers algoritmus, používají techniku zdvojování k dosažení časové složitosti O(n log n). Dokonce rychlejší, Karkkainen-Sanders algoritmus (známý také jako Skew algoritmus) dokáže sestavit suffixové pole v lineárním čase O(n) pro celočíselné abecedy. Tyto metody se spoléhají na řazení podle hodnocení a rekurzivní strategie, které se vyhýbají přímému porovnávání řetězců Společnost pro počítačovou vědu.
- 5. Konečný výstup: Výsledné suffixové pole umožňuje efektivní shodové vyhledávání, dotazy na podřetězce a je základním kamenem pro konstrukci dalších datových struktur, jako je LCP pole GeeksforGeeks.
Porozumění každému kroku a dostupným optimalizacím je zásadní pro využití suffixových polí v aplikacích zpracování řetězců velkého rozsahu.
Suffixová pole vs. Suffixové stromy: Klíčové rozdíly
Suffixová pole a suffixové stromy jsou obě základní datové struktury pro efektivní zpracování řetězců, zejména v aplikacích jako shodové vyhledávání, bioinformatika a datová komprese. Ačkoli slouží podobným účelům, jejich struktura, požadavky na paměť a provozní charakteristiky se výrazně liší.
Suffixový strom je komprimovaný trie všech suffixů daného řetězce, což umožňuje extrémně rychlé dotazy na podřetězce, obvykle v lineárním čase vzhledem k délce vzoru. Nicméně, suffixové stromy jsou složité na implementaci a vyžadují značné nároky na paměť – často několikrát větší velikost než původní řetězec – kvůli své struktuře založené na uzlech a potřebě ukládat ukazatele a označení hran. To je činí méně praktickými pro velmi velké datové sady nebo prostředí s omezenou pamětí.
Naopak, suffixové pole je mnohem jednodušší a prostorově efektivní datová struktura. Skládá se z pole celých čísel, které reprezentují počáteční pozice všech seřazených suffixů řetězce. Suffixová pole lze konstrukčně sestavit v lineárním čase a vyžadují pouze O(n) paměti, kde n je délka řetězce. Ačkoli jsou vyhledávání podřetězců pomocí suffixového pole obvykle pomalejší než s suffixovým stromem (O(m log n) pro vzor délky m), toto lze zlepšit na O(m) s pomocnými datovými strukturami, jako je pole nejdelších společných prefixů (LCP). Jednoduchost a nižší nároky na paměť dělají z suffixových polí preferovaný nástroj pro indexaci textů a vyhledávací úkoly velkého rozsahu.
Pro podrobný srovnávací přehled a další čtení viz Společnost pro počítačovou vědu a GeeksforGeeks.
Aplikace suffixových polí v informatice
Suffixová pole se stala základní datovou strukturou v informatice, zejména v oblastech jako zpracování řetězců, bioinformatika a vyhledávání informací. Jejich primární užitečnost spočívá v umožnění efektivního shodového vyhledávání a dotazů na podřetězce. Například suffixová pole se široce používají ve vyhledávačích plného textu, kde umožňují rychlou identifikaci všech výskytů dotazovaného podřetězce v rámci velkého textového korpusu. To je dosaženo využitím lexikograficky seřazeného pořadí suffixů, které podporuje binární vyhledávací operace pro shodové vyhledávání v logaritmické časové složitosti Princetonova univerzita.
V bioinformatice usnadňují suffixová pole porovnávání a zarovnávání sekvencí DNA a proteinů. Nástroje pro sestavování genomu a zarovnání sekvencí, jako jsou ty používané v sekvenování nové generace, často spoléhají na suffixová pole, aby efektivně zpracovávala masivní biologické datové sady Národní centrum pro biotechnologické informace. Kromě toho jsou suffixová pole nedílnou součástí algoritmů pro datovou kompresi, jako je Burrows-Wheelerova transformace, která je základem populárních kompresních nástrojů, jako je bzip2. Zde suffixové pole umožňuje transformaci vstupních dat do podoby, která je lépe vhodná pro kompresi tím, že seskupuje podobné znaky dohromady.
Kromě těchto využití se suffixová pole také používají v systémech pro detekci plagiátů, deduplikaci dat a konstrukci efektivních datových struktur pro dotazy typu nejdelší společný prefix (LCP). Jejich univerzálnost a efektivita je činí nenahraditelnými v aplikacích, kde je vyžadováno rychlé a škálovatelné zpracování řetězců.
Optimalizace vyhledávání a shodového porovnání pomocí suffixových polí
Suffixová pole jsou mocné datové struktury, které významně optimalizují operace vyhledávání a shodového porovnání v řetězcích. Uložením počátečních indexů všech suffixů textu v lexikografickém pořadí, suffixová pole umožňují efektivní dotazy na podřetězce, což je zásadní v aplikacích, jako je fulltextové vyhledávání, bioinformatika a datová komprese. Hlavní výhodou použití suffixového pole oproti naivním metodám vyhledávání je snížení časové složitosti pro shodové vyhledávání. Zatímco přístup pomocí brutální síly může vyžadovat čas O(nm) pro text délky n a vzor délky m, suffixová pole umožňují hledání vzoru v O(m + log n) čase využitím binárního vyhledávání na seřazených suffixech.
Pro další zlepšení výkonu se suffixová pole často používají v kombinaci s pomocnými datovými strukturami, jako je pole nejdelších společných prefixů (LCP). LCP pole uchovává délky nejdelších společných prefixů mezi po sobě jdoucími suffixy v suffixovém poli, což umožňuje ještě rychlejší shodové vyhledávání a usnadňuje úkoly, jako je nalezení počtu různých podřetězců nebo nejdelšího opakujícího se podřetězce v lineárním čase. Kromě toho moderní algoritmy pro konstrukci suffixových polí, jako je metoda indukovaného řazení, dosahují lineární časové složitosti, což je činí praktickými pro texty velkého rozsahu (Univerzita Helsinky).
Suffixová pole jsou také prostorově efektivní v porovnání se suffixovými stromy, protože vyžadují pouze O(n) paměti a jsou snadněji implementovatelná. Jejich efektivita a univerzálnost je činí základem při navrhování rychlých a škálovatelných systémů pro indexaci textů a shodové vyhledávání (Princetonova univerzita).
Běžné algoritmy vycházející ze suffixových polí
Suffixová pole jsou základní datová struktura v zpracování řetězců, umožňující efektivní řešení řady složitých problémů. Několik běžných algoritmů využívá suffixová pole k dosažení optimálního nebo téměř optimálního výkonu, zejména v oblastech shodového vyhledávání, datové komprese a bioinformatiky.
Jednou z nejvýznamnějších aplikací je vyhledávání podřetězců. Kombinováním suffixového pole s binárním vyhledáváním je možné lokalizovat všechny výskyty vzoru v textu za O(m log n) času, kde m je délka vzoru a n je délka textu. Tento přístup je významně rychlejší než naivní metody vyhledávání, zejména pro velké texty. Kromě toho je pole nejdelších společných prefixů (LCP) často konstruováno spolu s suffixovým polem, aby dále optimalizovalo dotazy na opakující se vzory a usnadnilo algoritmy pro nalezení nejdelšího opakujícího se podřetězce nebo nejdelšího společného podřetězce mezi více řetězci.
Suffixová pole jsou také klíčová pro algoritmy datové komprese, jako je Burrows-Wheelerova transformace (BWT), která je hlavní součástí kompresního nástroje bzip2. BWT spoléhá na seřazené pořadí suffixů k přeuspořádání vstupního textu, což ho činí vhodnějším pro hodnocení běhu a jiné techniky komprese (bzip2).
V bioinformatice se suffixová pole používají pro efektivní zarovnávání sekvencí a analýzu genomu, kde je rychlé vyhledávání a porovnávání sekvencí DNA nezbytné (Národní centrum pro biotechnologické informace). Jejich prostorová efektivita a rychlost je činí preferovanými před suffixovými stromy v mnoha aplikacích velkého rozsahu.
Úvahy o výkonu a omezení
Suffixová pole jsou vysoce efektivní datové struktury pro řešení různých problémů zpracování řetězců, jako je vyhledávání podřetězců, shodové vyhledávání a výpočet nejdelšího společného prefixu. Nicméně, jejich výkon a použitelnost jsou ovlivněny několika úvahami a inherentními omezeními.
Jedním z hlavních faktorů ovlivňujících výkon je čas konstrukce. Zatímco naivní algoritmy pro sestavení suffixových polí pracují v O(n log2 n) času, pokročilejší algoritmy dosahují lineární časové složitosti, jako je algoritmus SA-IS. Nicméně, tyto optimální algoritmy mohou být složité na implementaci a mohou mít významné konstantní faktory, které mohou ovlivnit praktický výkon, zejména pro velmi velké texty nebo v prostředích s omezenou pamětí. Prostorová složitost je dalším důležitým aspektem; suffixové pole obvykle vyžaduje O(n) paměti, ale pomocné struktury jako pole nejdelších společných prefixů (LCP) nebo další indexovací struktury mohou dále zvýšit využití paměti Univerzita Helsinky.
Suffixová pole jsou méně flexibilní než suffixové stromy, pokud jde o dynamické aktualizace, jako jsou vkládání nebo mazání v textu. Modifikace suffixového pole po jeho konstrukci není triviální a často vyžaduje rekonstrukci celé struktury, což je činí méně vhodnými pro aplikace, kde se základní text často mění Carnegie Mellon University. Kromě toho, i když jsou suffixová pole prostorově efektivnější než suffixové stromy, mohou se stále ukázat jako nepraktická pro extrémně velké datové sady, jako jsou celé genomové sekvence, bez další komprese nebo technik externí paměti Národní centrum pro biotechnologické informace.
Shrnuto, zatímco suffixová pole nabízejí významné výhody v oblasti rychlosti a paměťové efektivity pro statické texty, jejich omezení v dynamických scénářích a aplikacích velkého rozsahu musí být pečlivě zvažována během návrhu systému.
Případové studie a příklady z reálného světa
Suffixová pole se široce používají v různých reálných aplikacích, které vyžadují efektivní zpracování řetězců a shodové vyhledávání. Jedním z nejvýznamnějších případů použití je v bioinformatice, zejména při sekvenování a analýze genomu. Nástroje jako Burrows-Wheeler Aligner využívají suffixová pole k rychlému zarovnání krátkých čtení DNA k referenčním genomům, což umožňuje rozsáhlé genomové studie a personalizovanou medicínu.
V oboru vyhledávání informací jsou suffixová pole základní pro implementaci rychlých vyhledávačů plného textu. Například projekt Apache Lucene využívá suffixová pole a související datové struktury k poskytování efektivních schopností vyhledávání podřetězců, které jsou nezbytné pro indexaci a dotazování velkých textových korpusů.
Suffixová pole také hrají klíčovou role v algoritmech datové komprese. Například kompresní nástroj bzip2 využívá Burrows-Wheelerovu transformaci, která se spoléhá na konstrukci suffixového pole k přeuspořádání vstupních dat a zlepšení kompresibility.
Dále se suffixová pole používají v systémech detekce plagiátů, jako je Turnitin, k identifikaci podobností mezi dokumenty efektivním porovnáváním podřetězců. V zpracování přirozeného jazyka se používají k úkolům, jako je identifikace opakovaných frází, extrakce klíčových slov a tvorba konkordancí.
Tyto příklady ukazují univerzálnost a efektivitu suffixových polí při zpracování velkého objemu řetězců napříč různými obory, od výpočetní biologie po vyhledávače a datovou kompresi.
Další čtení a pokročilá témata
Pro čtenáře, kteří se chtějí podrobněji zabývat suffixovými poli, je k dispozici několik pokročilých témat a zdrojů. Jednou z významných oblastí je studium vylepšených suffixových polí, která rozšiřují základní strukturu o další data, jako je pole nejdelších společných prefixů (LCP), což umožňuje efektivnější shodové vyhledávání a dotazy na podřetězce. Interakce mezi suffixovými poli a suffixovými stromy je také bohatým polem, protože obě struktury řeší podobné problémy, ale s různými výhodami z hlediska prostoru a času konstrukce.
Nedávný výzkum se soustředil na algoritmy konstrukce v lineárním čase pro suffixová pole, jako jsou algoritmy SA-IS a DC3 (Skew), které jsou klíčové pro zpracování velkých genomických nebo textových dat. Tyto algoritmy jsou podrobně projednávány v literatuře, včetně zakládající práce Skupiny funkčních suffixových polí Univerzity Helsinky.
Aplikace suffixových polí přesahují zpracování řetězců do oblastí jako datová komprese (např. Burrows-Wheelerova transformace), bioinformatika (sestavování a zarovnávání genomu) a vyhledávání informací. Pro komplexní přehled je vysoce doporučována kniha Algoritmy na řetězcích, stromech a sekvencích od Dana Gusfielda.
- Suffixová pole: Nová metoda pro online vyhledávání řetězců (původní článek od Manbera & Myerse)
- Lineární konstrukce suffixového pole pomocí indukovaného řazení (algoritmus SA-IS)
- Wikipedia: Suffixové pole (přehled a další odkazy)
Zdroje & Odkazy
- Americká matematická společnost
- Princetonova univerzita
- Katedra informatiky Univerzity Helsinky
- GeeksforGeeks
- Národní centrum pro biotechnologické informace
- Carnegie Mellon University
- Apache Lucene
- Turnitin
- Algoritmy na řetězcích, stromech a sekvencích
- Wikipedia: Suffixové pole